传统视觉定位方法主要关注单图像场景,依赖于简单文本引用。然而,在现实世界中,处理隐含和复杂的指令,尤其是在涉及多图像的情况下,是一个重大挑战,主要原因是缺乏跨多模态上下文的高级推理能力。
清华大学和阿里巴巴的研究人员推出 UniVG-R1,通过推理引导的多模态大语言模型(MLLM)实现通用视觉定位(Universal Visual Grounding)。UniVG-R1 通过结合强化学习(Reinforcement Learning, RL)和冷启动数据(cold-start data),增强了模型的推理能力。

主要功能
UniVG-R1 的主要功能包括:
- 复杂指令理解:能够理解隐含和复杂的指令,例如处理类似“在第二张图片中找到与第一张图片中物体功能相似的物体”这样的指令。
- 多图像上下文理解:支持在多图像场景中进行视觉定位,例如在多张图片中找到共同的物体或处理图像间的对应关系。
- 推理增强:通过强化学习提升模型的推理能力,使其能够更好地处理复杂的多模态任务。
主要特点
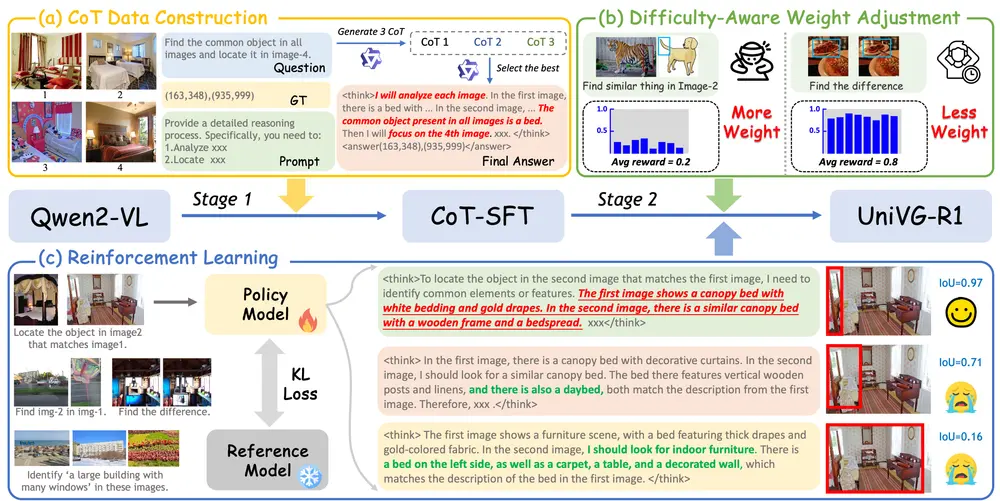
- 推理引导的训练:UniVG-R1 通过构建高质量的推理链(Chain-of-Thought, CoT)数据集,指导模型学习结构化的推理路径。
- 强化学习:采用基于规则的强化学习(Group Relative Policy Optimization, GRPO)算法,激励模型选择正确的推理链,从而增强其推理能力。
- 难度感知权重调整策略:识别 GRPO 训练中的难度偏差,提出一种动态调整样本权重的策略,使模型更多地关注困难样本,进一步提升性能。
工作原理
UniVG-R1 的工作原理基于以下两个阶段的训练过程:
- 冷启动监督微调(CoT-SFT):
- 数据集构建:从 MGrounding-630k 数据集中随机采样,并利用先进的多模态大语言模型 Qwen-VL-MAX 生成推理链。每个样本都标注了详细的推理过程,确保模型能够学习正确的推理路径。
- 监督微调:使用这些标注了推理链的数据对模型进行监督微调,使模型能够通过逐步推理生成最终的边界框预测。
- 强化学习(GRPO):
- 奖励函数:定义了两种奖励函数:准确性奖励(Accuracy Reward)和格式奖励(Format Reward)。准确性奖励基于预测边界框与真实边界框的交并比(IoU),格式奖励确保模型输出符合特定格式。
- 相对优势计算:GRPO 通过计算每个响应的相对优势,激励模型选择正确的推理链。通过动态调整样本权重,使模型更多地关注困难样本,从而提升整体性能。
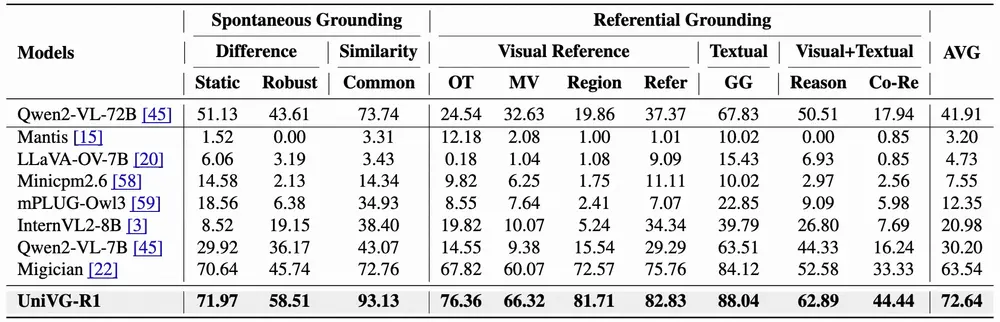
测试结果
UniVG-R1 在多个基准测试中表现出色,具体结果如下:
- MIG-Bench:在多图像定位基准测试 MIG-Bench 上,UniVG-R1 实现了 72.64% 的平均性能,比之前的最佳方法 Migician 提高了 9.1%。
- 零样本性能:在多个推理引导的定位基准测试中,UniVG-R1 展示了强大的零样本性能,平均性能提升 23.4%。具体来说,在 LISA-Grounding 上提升了 27.8%,在 LLMSeg-Grounding 上提升了 15.9%,在 ReVOS-Grounding 上提升了 20.3%,在 ReasonVOS 上提升了 25.3%。
- RefCOCO 数据集:在 RefCOCO 数据集上,UniVG-R1 达到了 88.20% 的平均性能,优于其他模型,尤其是在包含更复杂引用指令的 RefCOCOg 数据集上表现突出。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











