
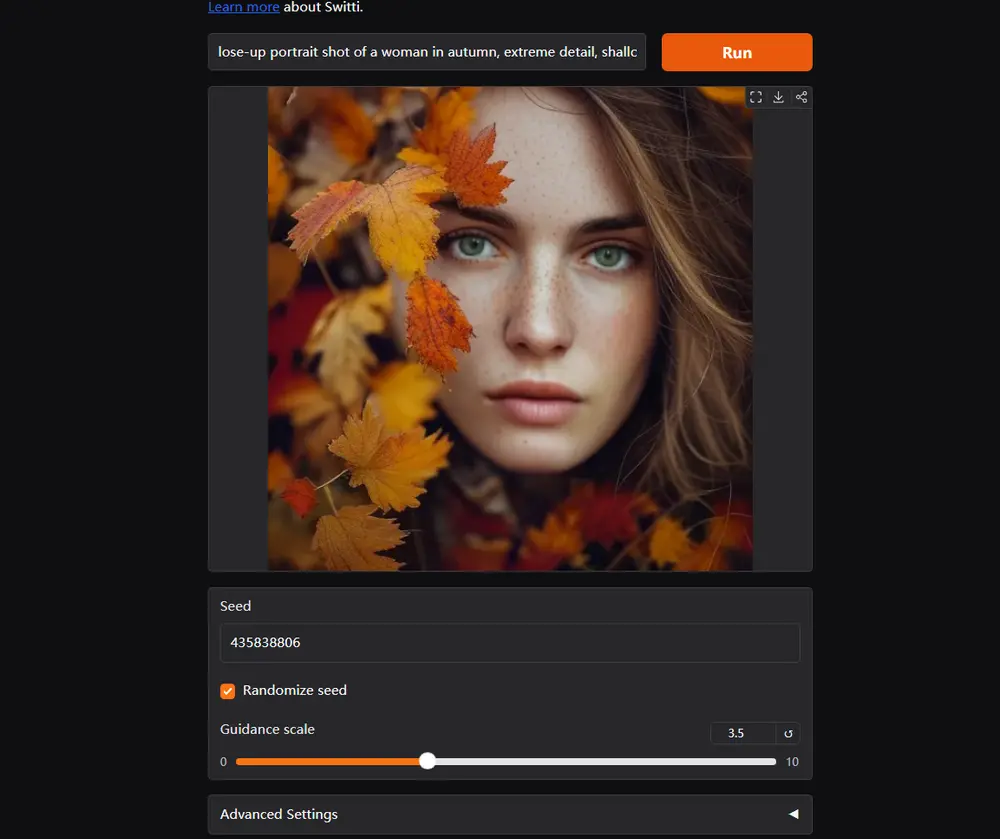
Yandex Research、俄罗斯国立研究型大学高等经济学院、莫斯科物理技术学院和Skoltech科大的研究人员推出新型规模感知变换器SWITTI,它用于文本到图像的合成。SWITTI基于现有的下一代规模预测自回归(AR)模型,通过提出架构修改来改善模型的收敛性和整体性能。SWITTI的核心在于其规模感知的特性,它能够根据文本提示生成高质量的图像。例如,你给SWITTI一个文本提示,比如“一个穿着宇航服的小猫在月球上”,SWITTI将根据这个描述生成一个相应的图像。它能够理解文本中的元素,并将其转化为视觉内容,如小猫、宇航服和月球表面。
- 项目主页:https://yandex-research.github.io/switti
- GitHub:https://github.com/yandex-research/switti
- 模型:https://huggingface.co/yresearch
- Demo:https://huggingface.co/spaces/dbaranchuk/Switti
Switti的技术创新
- 从下一尺度预测出发:研究团队基于现有的下一尺度预测自回归模型,探索其在文本到图像生成中的应用潜力。这些模型通过逐步构建图像的不同尺度来生成最终的高分辨率图像。
- 架构改进提升收敛性和性能:为了克服传统AR模型在文本到图像任务中的局限性,研究人员对模型架构进行了优化,增强了模型的收敛速度和整体性能,使得生成过程更加稳定且高效。
- 非自回归替代方案:研究人员发现预训练的尺度感知AR模型的自注意力图对前序尺度的依赖较弱。基于这一观察,他们提出了一种非自回归的替代方案,实现了约11%的采样加速和更低的内存占用,同时保持甚至提升了图像生成的质量。
- 优化高分辨率尺度下的引导机制:在高分辨率尺度下,传统的无分类器引导(classifier-free guidance)往往没有必要,有时甚至会降低生成效果。Switti通过在这些尺度上禁用引导,进一步实现了约20%的采样加速,并改善了细粒度细节的生成。

主要功能:
- 文本到图像的合成:SWITTI可以将文本描述直接转换成图像。
- 高质量和高分辨率的图像生成:SWITTI能够产生512×512像素的高质量图像样本。
- 高效率的采样:SWITTI在采样过程中比现有的文本到图像的自回归模型快约7倍。
主要特点:
- 规模感知变换器:SWITTI不需要因果关系,可以非因果地工作,这加快了采样速度并降低了内存使用。
- 改进的架构设计:通过修改变换器的主干,提高了训练稳定性和收敛性。
- 高分辨率下的文本条件依赖性降低:SWITTI在高分辨率尺度上对文本的依赖性较弱,允许在最后几个尺度上禁用分类器自由引导(CFG),从而进一步提高采样速度和细节生成质量。
工作原理:
SWITTI通过一个分层的变分自编码器(VAE)将图像映射到不同分辨率的潜在变量(尺度)序列,并使用变换器迭代预测图像的尺度。它从单一像素开始,逐步预测更高分辨率的图像版本,同时关注之前生成的尺度。SWITTI采用了非因果变换器,允许在同一尺度的令牌之间进行自注意力操作,而不需要存储之前尺度的信息。
- 基本架构:紧密遵循 VAR 和 STAR,包含作为图像标记器的 RQ-VAE、预训练的文本编码器以及尺度感知块级因果转换器。采用预训练的 RQ-VAE,结合两个文本编码器以确保图像与文本的强对齐。
- 训练动态:分析基本模型的训练性能并引入改进,如将模型头转换为 FP32、使用 “三明治” 样的归一化、采用 SwiGLU 激活等,以稳定训练并提高性能。
- 采用非因果转换器:基于观察到 VAR 模型中对先前尺度的条件作用存在两次,更新注意力掩码,使转换器不再是因果的,从而提高采样效率并改善性能。
- 文本条件的作用:分析不同模型尺度上文本条件的影响,发现模型在较高尺度上对提示的依赖较小,且在最后两个尺度上提示对图像语义的影响最小。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











