
字节跳动和北京大学深圳研究生院的研究人员推出一个基于DiT模型的图像定制框架DreamO ,旨在支持多种图像定制任务,同时实现多种条件(如身份、主体、风格、背景等)的无缝集成。它通过引入特征路由约束和占位符策略,确保生成结果与参考图像在特定属性上保持一致,同时允许灵活控制生成内容的放置位置。
- 项目主页:https://mc-e.github.io/project/DreamO
- GitHub:https://github.com/bytedance/DreamO
- 模型:https://huggingface.co/ByteDance/DreamO
- Demo:https://huggingface.co/spaces/ByteDance/DreamO
- ComfyUI插件:https://github.com/jax-explorer/ComfyUI-DreamO(需要40G显存)
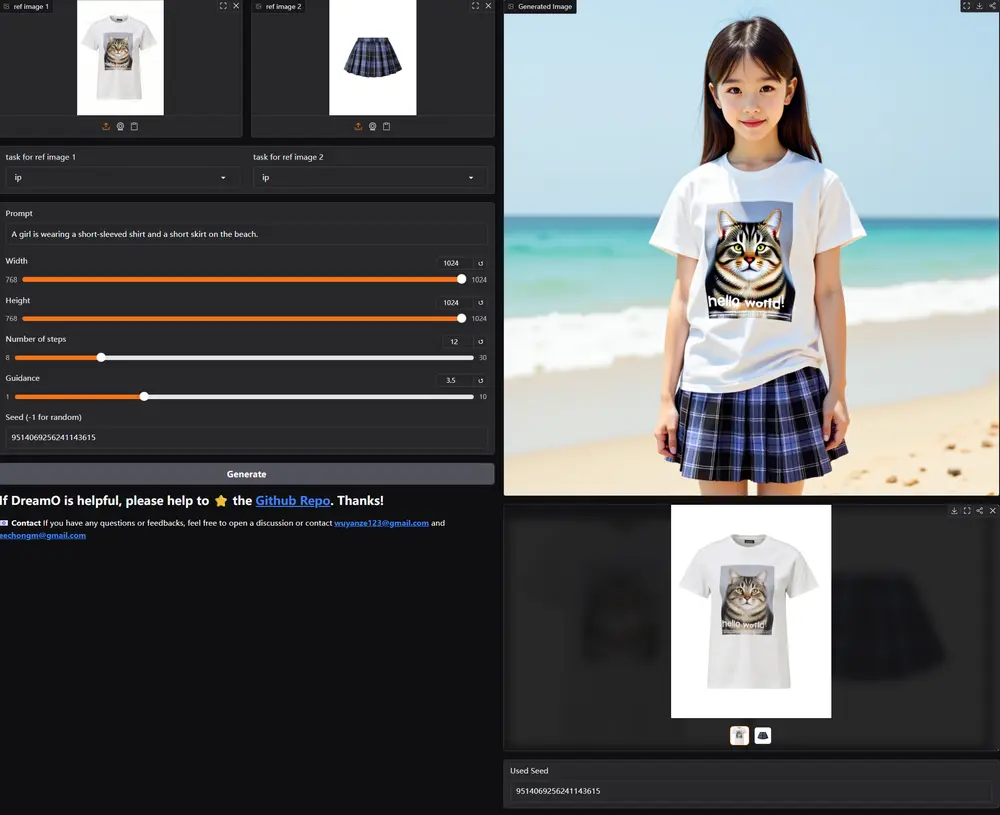
例如,你想生成一张图像,内容是一个穿着特定服装的人在特定场景中。使用 DreamO,你可以提供一张参考图像(如某个人的面部特写)和一个描述(如“在森林中,一个穿着黄色帽子和太阳镜的男人”)。DreamO 能够将参考图像的特征(如面部特征)与描述中的场景和服装信息结合起来,生成一张符合要求的图像。
主要功能
- 多条件图像定制:支持多种条件的组合,如身份(identity)、主体(subject)、风格(style)和背景(background)。
- 灵活的条件放置控制:通过占位符策略,用户可以指定条件在生成图像中的具体位置。
- 高质量生成:通过特征路由约束和逐步训练策略,确保生成图像的质量和一致性。
- 统一框架:在一个模型中实现多种图像定制任务,无需为每个任务单独训练模型。

主要特点
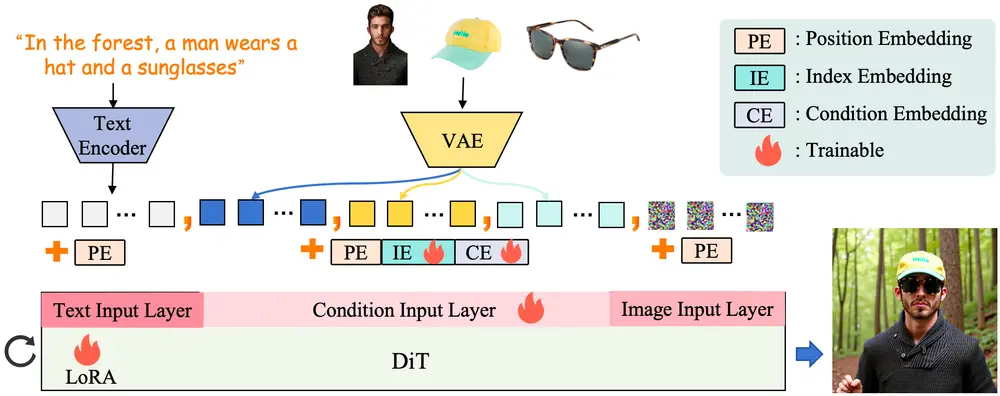
- 特征路由约束:通过约束条件图像与生成结果之间的交叉注意力,确保生成结果与参考图像在特定区域的一致性。
- 占位符策略:通过在文本描述中添加占位符(如 [ref#1]),建立文本描述与条件图像之间的对应关系,控制条件在生成图像中的位置。
- 逐步训练策略:通过分阶段训练(初始阶段、全面训练阶段、质量对齐阶段),逐步提升模型的定制能力和生成质量。
- 轻量级设计:基于预训练的 DiT 模型,仅通过少量额外参数(如 LoRA 模块)实现定制能力,降低了训练成本。
工作原理
- 预训练扩散变换器(DiT):DreamO 基于预训练的 DiT 模型,将图像和文本输入统一处理为序列,通过扩散过程生成高质量图像。
- 特征路由约束:在训练过程中,通过最小化条件图像与生成结果之间的交叉注意力差异,确保生成结果与参考图像在特定区域的一致性。
- 占位符策略:在文本描述中添加占位符(如 [ref#1]),并通过训练确保占位符与条件图像之间的正确关联,从而控制条件在生成图像中的位置。
- 逐步训练策略:
- 初始阶段:在简单的主体驱动数据上进行训练,快速建立一致性生成能力。
- 全面训练阶段:在所有任务数据上进行训练,提升模型的多任务能力。
- 质量对齐阶段:通过生成的高质量图像对模型进行微调,确保生成结果与预训练模型的质量一致。
测试结果
- 高质量生成:DreamO 在多种图像定制任务中表现出色,生成的图像在细节和一致性上与参考图像高度匹配。
- 多条件集成:能够灵活处理多种条件的组合,如同时控制身份、主体和风格。
- 逐步训练的优势:通过逐步训练策略,模型在复杂任务上的收敛速度更快,生成质量更高。
- 轻量级设计:仅通过少量额外参数(如 LoRA 模块)实现定制能力,显著降低了训练成本。
应用场景
- 内容创作:用于生成高质量的定制图像,适用于广告、游戏、影视等领域。
- 虚拟试穿:支持虚拟试穿功能,用户可以预览不同服装在自己身上的效果。
- 风格转换:将一种风格的图像转换为另一种风格,适用于艺术创作和设计。
- 教育和培训:生成符合特定条件的图像,帮助学生更好地理解和学习复杂概念。
通过其统一的框架和灵活的定制能力,DreamO 为图像生成领域提供了一种高效、高质量的解决方案,适用于多种实际应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











