
近年来,视频生成模型因其能够捕捉现实世界中的动态变化和复杂因果关系,被广泛视为一种“世界模拟器”。它们整合了视觉、时间、空间和语义等多个维度的信息,在建模长程依赖和多模态交互方面展现出强大潜力。
那么问题来了:能否将这些高维视频生成模型迁移到低维任务中,比如可控图像生成?
近日,浙江大学、Kunbyte AI、蚂蚁集团和杭州师范大学联合提出了一种创新性的知识迁移方法——DRA-Ctrl,通过压缩视频模型的知识并适配到图像生成任务中,成功实现了对图像生成的高质量控制。
- 项目主页:https://dra-ctrl-2025.github.io/DRA-Ctrl
- GitHub:https://github.com/Kunbyte-AI/DRA-Ctrl
- 模型:https://huggingface.co/Kunbyte/DRA-Ctrl
- Demo:https://huggingface.co/spaces/Kunbyte/DRA-Ctrl
这项研究是基于腾讯开源的视频模型HunyuanVideo-I2V,不仅展示了视频模型在图像生成领域的潜在价值,也为未来统一视觉生成模型的发展提供了新思路。
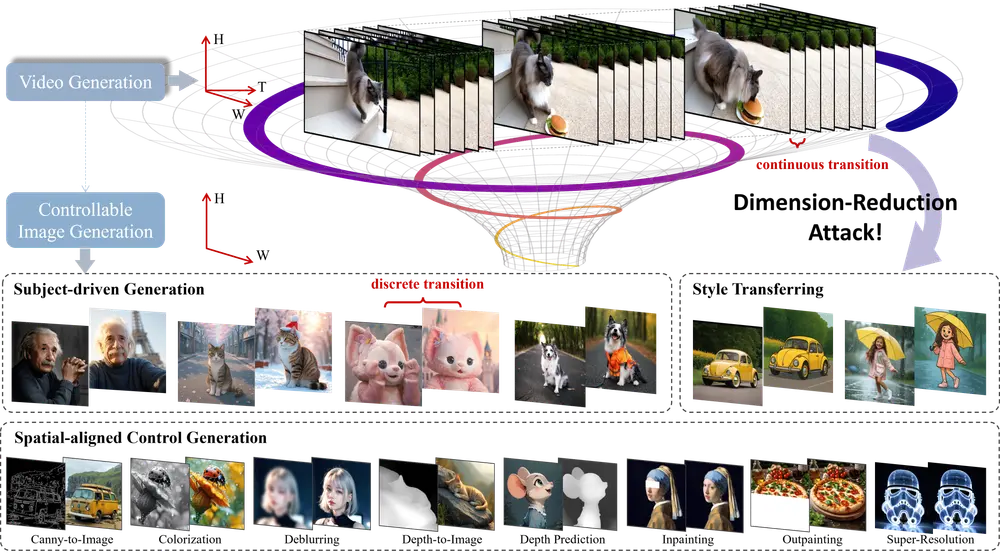
研究背景与动机
传统的图像生成模型(如Stable Diffusion系列)主要专注于静态图像的建模,虽然在可控生成方面已有不少进展,但在主体一致性、结构保持等方面仍存在局限。
相比之下,视频生成模型具备以下优势:
- 长程上下文建模能力;
- 时间全注意力机制;
- 丰富的动态先验信息。
这些特性使得视频模型在处理跨帧连续性、动作演化等任务时表现出更强的能力。因此,研究人员提出一个自然的问题:是否可以将这些视频模型的知识“压缩”下来,用于提升图像生成的效果?
DRA-Ctrl 正是这一思想的体现。

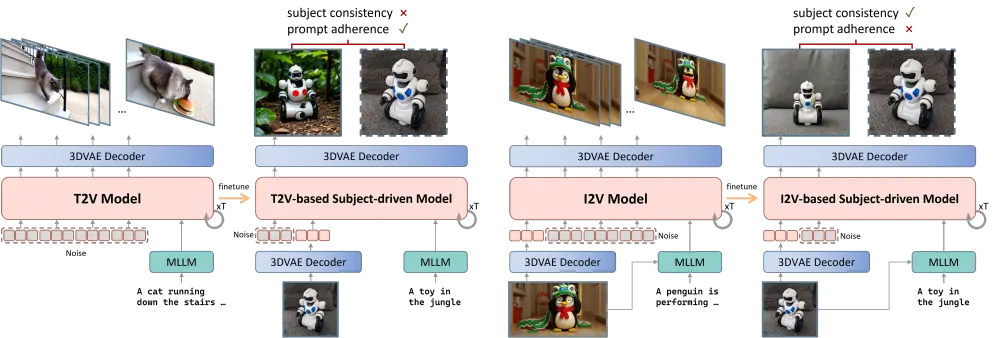
方法概述
DRA-Ctrl 的核心思想是将图像生成任务转化为视频生成任务的一部分,即把条件图像和目标图像当作一段两帧的视频进行建模。具体流程如下:
- 在训练阶段:
- 条件图像保持无噪状态,不参与损失计算;
- 目标图像则被加入噪声,并作为训练信号。
- 在推理阶段:
- 条件图像提供完整的控制信号;
- 模型根据文本提示和图像控制生成高质量的目标图像。
然而,直接使用视频模型进行图像生成面临两大挑战:
- 视频帧之间的连续性 vs 图像生成的离散性;
- 文本提示与图像控制信号之间的对齐问题。
为了解决这些问题,DRA-Ctrl 引入了三项关键技术:
关键技术点
1. 混合过渡策略(Mixup-based Transition Strategy)
由于视频模型擅长生成平滑的帧间过渡,而图像生成往往需要突变或跳跃式的转换,研究人员提出了一种基于混合(mixup)的过渡策略:
- 将条件图像与目标图像视为视频序列的两端;
- 通过加权混合的方式生成中间帧;
- 实现从控制图像到目标图像的平滑过渡,从而更好地适应视频模型的生成机制。
这种方法有效缓解了视频模型对连续性的偏好与图像任务对突变需求之间的矛盾。
2. 帧跳位置编码(Frame Skip Position Embedding, FSPE)
为了减少不必要的帧生成以提高效率,DRA-Ctrl 引入了帧跳位置编码机制:
- 在潜在空间中扩展时间间隔;
- 减少实际生成的帧数;
- 降低计算开销,同时保持模型对时间结构的理解。
3. 注意力掩码机制(Attention Masking Strategy)
为了解决文本提示与图像控制信号之间的对齐问题,DRA-Ctrl 设计了一种注意力掩码机制:
- 防止不同输入序列之间信息混杂;
- 明确区分文本提示与图像控制信号的作用区域;
- 提升模型对控制条件的理解与执行能力。
实验与结果分析
研究人员在多个图像生成任务上评估了 DRA-Ctrl 的性能,包括:
- 主体驱动生成;
- 空间条件生成(如边缘图到图像、深度图到图像);
- 图像修复与风格转换。
1. 空间条件生成任务(COCO2017验证集)
| 方法 | 边缘图→图像 F1 |
|---|---|
| OminiControl | 0.38 |
| DRA-Ctrl | 0.42 |
DRA-Ctrl 在多个子任务中均表现优异,尤其在边缘图到图像生成任务中显著优于现有方法。
2. 主体驱动生成任务(DreamBench数据集)
| 方法 | VL Score | DINO Score | CLIP-I Score |
|---|---|---|---|
| OminiControl | 2.21 | 0.695 | 0.801 |
| DRA-Ctrl | 2.56 | 0.722 | 0.825 |
DRA-Ctrl 在视觉语言一致性、图像相似性和语义匹配方面均取得领先成绩。
3. 风格转换示例
DRA-Ctrl 成功将原始图像转换为 Bitmoji 风格图像,同时保持了原有内容的结构完整性,展现了其强大的风格迁移能力。
总结与展望
DRA-Ctrl 展示了如何有效地将视频生成模型的知识压缩并适配到图像生成任务中。通过引入混合过渡策略、帧跳位置编码和注意力掩码机制,该方法在多种可控图像生成任务中取得了优于专门训练图像模型的表现。
这项工作具有重要意义:
- 资源再利用:为重用大规模视频模型提供了新路径;
- 统一建模:推动了跨模态、跨任务的视觉生成模型发展;
- 未来方向:启发后续研究探索更高层次的通用视觉生成架构。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











