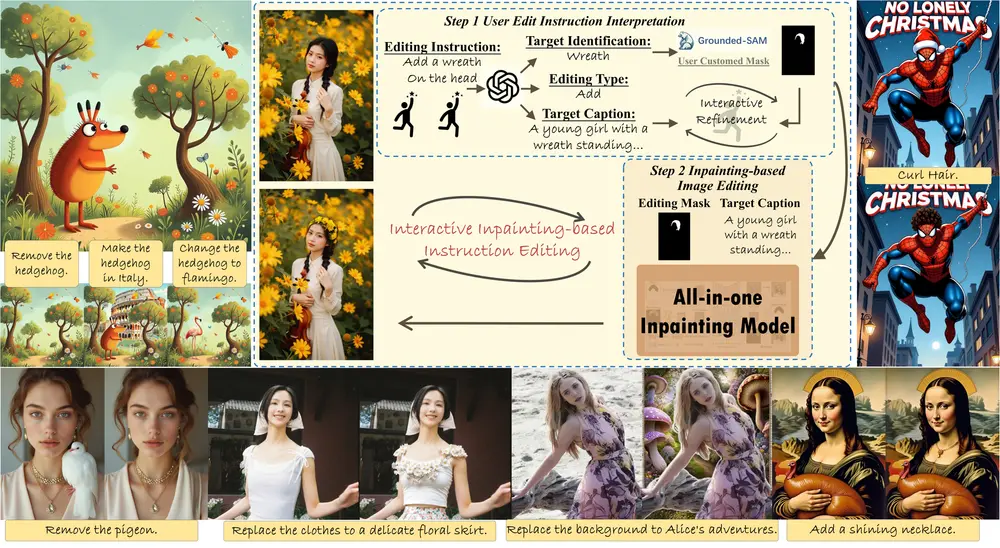
近年来,统一多模态模型(Unified Multimodal Models, UMMs)因其在视觉理解与生成任务中的双重能力而受到广泛关注。这类模型旨在通过单一架构实现对图像和文本的联合建模,既能“看懂”图像内容,也能根据指令生成高质量图像。
然而,传统训练方式依赖于图像-文本配对数据,而这些文本描述往往较为稀疏,难以覆盖图像中丰富的细节信息——即使使用长文本描述简单图像,也常缺失关键的空间结构、材质或局部特征。这导致模型在生成阶段容易丢失原始语义,影响保真度。
- 项目主页:https://reconstruction-alignment.github.io
- GitHub:https://github.com/HorizonWind2004/reconstruction-alignment
- 模型:https://huggingface.co/collections/sanaka87/reca-68ad2176380355a3dcedc068
- Demo:https://huggingface.co/spaces/sanaka87/BAGEL-RecA
- ComfyUI-BAGEL:https://github.com/neverbiasu/ComfyUI-BAGEL
为解决这一问题,来自加州大学伯克利分校与华盛顿大学的研究团队提出了一种简洁高效的后训练策略:RecA(Reconstruction Alignment)。该方法无需额外标注数据,即可显著提升UMM在图像生成与编辑任务中的表现。
核心思想:用“自身理解”指导生成
RecA 的核心创新在于:利用模型自身的视觉理解编码器所提取的嵌入向量,作为密集监督信号来指导图像重建过程。

具体来说:
- 输入一张图像,先由模型的视觉编码器(如CLIP)提取其高层语义嵌入;
- 将该嵌入作为条件输入到生成模块;
- 模型任务变为:以该嵌入为“提示”,尽可能准确地重建原始输入图像;
- 通过自监督损失函数(如L1、感知损失等)优化生成结果与原图之间的差异。
这个过程本质上是在重新对齐模型的“理解”与“生成”能力,使其生成路径更忠实于其内部语义表示。
主要特点
| 特性 | 说明 |
|---|---|
| ✅ 资源高效 | 仅需 27 GPU 小时即可完成后训练,在小型计算资源下也可部署。 |
| ✅ 无需额外数据 | 不依赖人工标注或新图像-文本对,完全基于已有数据进行自监督学习。 |
| ✅ 架构通用 | 支持多种主流UMM架构,包括自回归(AR)、掩码自回归(MAR)和基于扩散(Diffusion-based)的模型。 |
| ✅ 易于集成 | 作为后训练步骤,可无缝接入现有训练流程,无需修改主干网络结构。 |
实验效果:全面性能提升
在多个权威基准测试中,RecA 均展现出显著改进:
| 基准 | 指标 | 提升情况 |
|---|---|---|
| GenEval | 图像生成质量 | 0.73 → 0.90 |
| DPGBench | 细节保真度 | 80.93 → 88.15 |
| ImgEdit | 图像编辑准确性 | 3.38 → 3.75 |
| GEdit | 文本引导编辑能力 | 6.94 → 7.25 |
值得注意的是,经过 RecA 优化的 1.5B 参数模型,在多项指标上甚至超过了更大规模的开源模型,验证了其有效性与性价比。
工作流程简述
- 前向推理:将输入图像送入视觉编码器,获得语义嵌入向量;
- 构建条件输入:将嵌入向量注入生成解码器(可通过交叉注意力等方式);
- 图像重建:模型尝试从该条件出发,复现原始图像;
- 反向传播:通过重建误差更新生成路径参数,强化理解与生成的一致性。
整个过程无需人类参与,完全自动化执行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











