腾讯优图实验室近日开源了 Youtu-VL——一款仅有 40 亿参数 的轻量级视觉语言模型(VLM),却能在无需任务专用模块的前提下,同时胜任通用多模态任务与高难度的以视觉为中心的任务(如图像分割、深度估计、目标检测等)。
- GitHub:https://github.com/TencentCloudADP/youtu-vl
- 模型:https://huggingface.co/collections/tencent/youtu
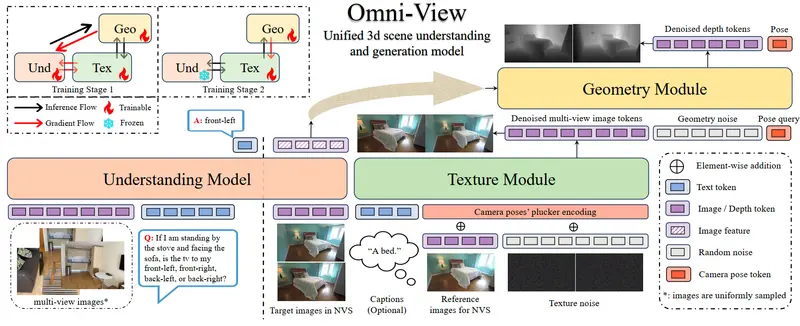
其核心突破在于提出 “视觉语言统一自回归监督”(VLUAS)范式,从根本上改变了传统 VLM 中“视觉仅为输入条件”的局限,让模型真正将视觉信号视为可生成、可预测的一等公民。
为什么 Youtu-VL 值得关注?
传统视觉语言模型通常以文本为中心:图像被编码为特征向量,作为语言模型的上下文输入。这种方式容易丢失细粒度视觉信息,且难以直接输出像素级预测(如分割掩码或深度图)。
而 Youtu-VL 通过 学习到的视觉码书(visual codebook),将图像内容离散化为“视觉词元”,并与文本词表统一。在训练时,模型联合自回归地重建视觉词元和文本词元,从而显式保留密集视觉细节,同时强化多模态语义对齐 。
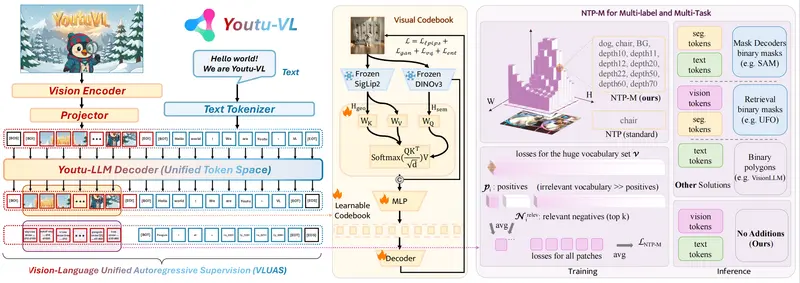
这一设计使得 Youtu-VL 能在标准 Transformer 架构下,直接处理两类任务:
- 通用多模态任务:视觉问答(VQA)、OCR、多图推理、GUI 智能体交互等
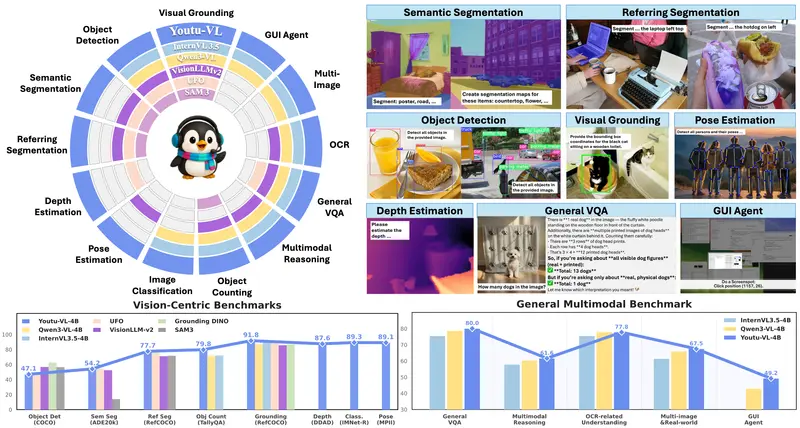
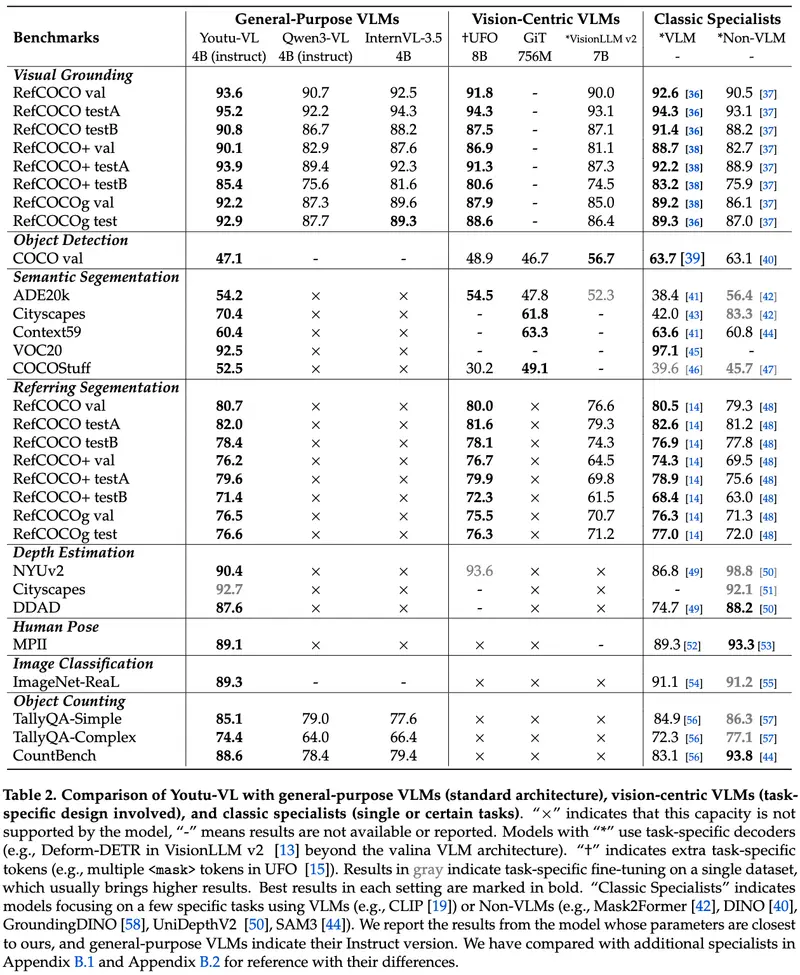
- 以视觉为中心的任务:目标检测、语义分割、参考分割、深度估计、人体姿态估计、目标计数等
换言之,同一个模型,既能回答“图中有几只猫?”,也能输出每只猫的精确边界框或分割掩码——无需额外头(head)或微调。
性能与效率兼顾
尽管参数量仅为 4B(远小于百亿级大模型),Youtu-VL 在多项基准测试中表现极具竞争力:
- 在 通用 VQA 和多模态推理 上达到主流水平
- 在 密集视觉预测任务(如分割、深度估计)上显著优于同规模模型,甚至逼近更大模型的表现
这种“小而强”的特性,使其更适合部署到资源受限的场景,如移动端、边缘设备或需要低延迟响应的应用。
模型已开源,支持多种格式
腾讯已在 Hugging Face 开源两个版本:
| 模型名称 | 格式 | 特点 |
|---|---|---|
Youtu-VL-4B-Instruct | 原生 PyTorch | 支持完整功能 |
Youtu-VL-4B-Instruct-GGUF | GGUF | 兼容 llama.cpp,便于本地 CPU/GPU 推理 |
开发者可直接下载使用,用于构建多模态应用或进行二次研究。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











