
百度飞桨近期完成 PaddleOCR 3.4.0 版本更新,正式推出新一代视觉语言模型 PaddleOCR-VL-1.5。这款面向真实场景的文档解析专用模型,仅0.9B参数量却实现资源高效与性能领先,在多类复杂文档场景中达到SOTA水平,同时新增文本检测识别、印章识别等能力,语言支持扩展至111种,兼顾高精度与轻量化部署需求。
- GitHub:https://github.com/PaddlePaddle/PaddleOCR
- 模型:https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL-1.5
- Demo:https://modelscope.cn/studios/PaddlePaddle/PaddleOCR-VL-1.5_Online_Demo
模型定位与核心定位
PaddleOCR-VL-1.5 是飞桨PaddleOCR-VL系列的迭代升级版本,聚焦真实复杂场景下的文档智能解析,面向扫描件、拍照件、倾斜、弯曲、弱光照、屏摄等各类非标准化文档,提供一体化的版面分析、文本识别、要素提取能力。
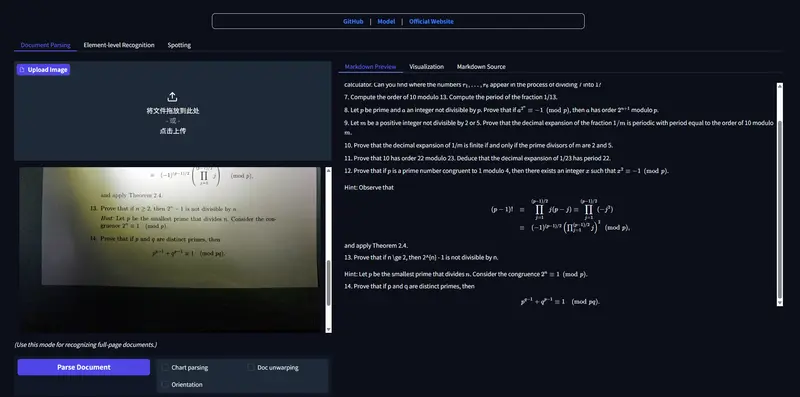
依托自研的 PP-DocLayoutV3 不规则形状版面定位算法,模型能够精准处理扭曲、形变、光照不均的自然文档,解决传统OCR在真实场景中鲁棒性不足的问题。同时,模型保持0.9B紧凑参数量,实现低资源消耗与高性能的平衡,已同步上线HuggingFace,支持官网在线体验与API调用。
核心性能:多场景、多基准全面领先
- 基准测试SOTA表现
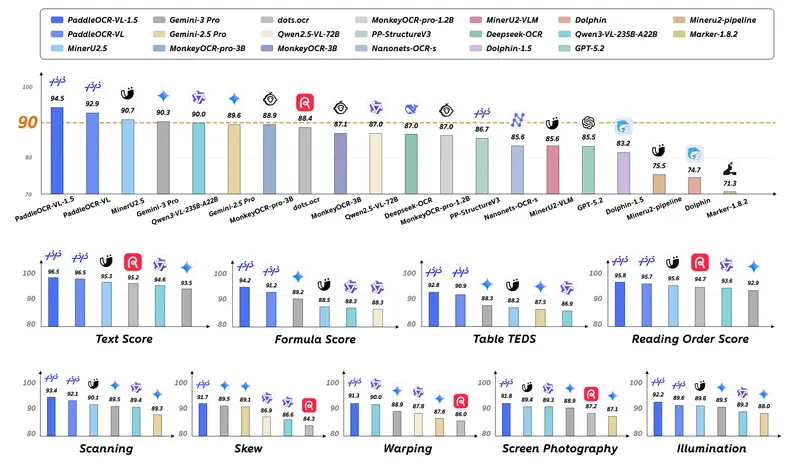
在权威文档解析基准数据集 OmniDocBench v1.5 上,PaddleOCR-VL-1.5 实现 94.5% 的高精度表现,超越多款全球主流通用大模型与专用文档解析模型,在专业赛道上处于领先位置。 - 真实复杂场景全面领先
模型针对日常高频的复杂文档场景做专项优化,也是业界首个支持不规则文档版面定位的方案。在扫描件、弯曲形变、倾斜偏移、屏幕拍摄、复杂光照五大真实场景的评测集上,综合表现全面优于主流开源与闭源方案,对非标准化、非理想化的文档具备更强的适配能力。
关键升级与新增能力
1. 新增两大实用任务能力
- 文本检测识别能力:在原有文档解析基础上,补齐端到端文本检测与识别链路,从版面定位到文字提取形成完整闭环。
- 印章识别能力:新增对印章区域的定位、提取与内容识别,满足政务、财务、合同、档案等场景的合规核验需求。
2. 多元素识别能力全面强化
针对专业文档中的复杂结构与特殊内容,模型做了针对性优化:
- 提升表格、公式、图表、下划线、复选框等结构化元素的识别准确率;
- 增强古籍、特殊符号、多语言混合排版的解析效果;
- 语言支持从原有范围扩展至111种语言,新增藏文、孟加拉语等小语种支持,覆盖更广泛的国际化与民族语言场景。
3. 长文档跨页解析能力
针对多页文档常见的内容碎片化问题,PaddleOCR-VL-1.5 新增跨页处理能力:
- 支持跨页表格自动合并、还原完整表格结构;
- 支持跨页段落、标题的关联识别,保证长文档逻辑完整。
有效解决合同、标书、报告、书籍等长文档在分页扫描、分页拍摄后的解析割裂问题。
4. 轻量化设计,部署友好
模型保持 0.9B 紧凑参数量,在持续扩展能力、提升精度的同时,维持极低的资源消耗,适合在服务器、边缘设备、本地化私有化环境中部署,兼顾性能与落地成本。
版本与使用入口
本次升级整体纳入 PaddleOCR 3.4.0 版本体系,核心亮点为PaddleOCR-VL-1.5视觉语言模型。
- 模型已开源并发布至 HuggingFace 平台,支持开发者下载、二次开发与部署;
- 可通过 PaddleOCR 官方网站 进行在线体验、效果测试;
- 提供标准化 API 接口,方便集成至企业数字化系统、档案管理、票据核验、办公自动化等业务流程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











