生成模型通过将随机噪声转换为图像,在图像生成领域取得了显著进展。然而,这些模型的反演任务(即将图像转换回结构化噪声以进行恢复和编辑)面临着忠实性和可编辑性的挑战。扩散模型(DMs)虽然在图像生成建模中占据主导地位,但由于漂移和扩散中的非线性,其反演存在困难。现有的最先进的 DM 反演方法依赖于额外参数的训练或潜在变量的测试时优化,这些方法在实际应用中成本高昂。
- 项目主页:https://rf-inversion.github.io
- GitHub:https://github.com/LituRout/RF-Inversion
- ComfyUI插件:https://github.com/logtd/ComfyUI-Fluxtapoz
德克萨斯大学奥斯汀分校和谷歌的研究人员提出了一种新的方法——RF-Inversion,通过校正流(RFs)和动态最优控制来解决图像反演和编辑的问题。RF-Inversion 利用线性二次调节器(LQR)导出的动态最优控制,生成一个等价于校正随机微分方程(SDE)的向量场。此外,研究团队还将该框架扩展为设计一个 Flux 的随机采样器。RF-Inversion是一种用于图像处理的先进方法,可以对真实世界的图片进行风格转换和编辑。简单来说,这项技术能够让你对一张图片进行各种有趣的变换,比如改变图片中人物的性别、年龄,或者给一张简笔画添加细节,使其变成一张逼真的照片。
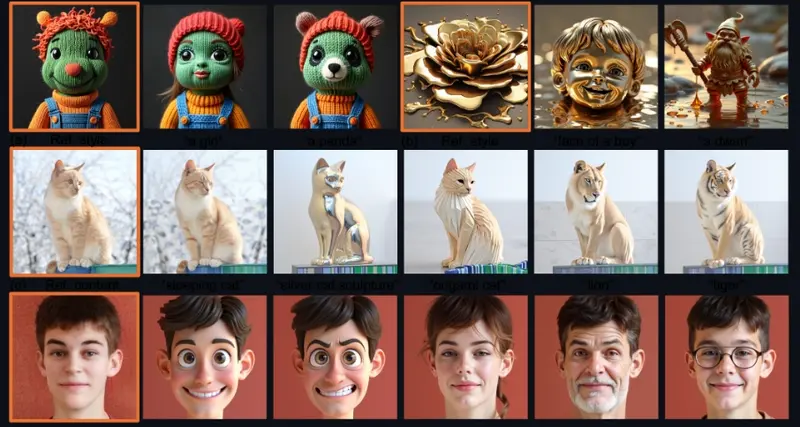
主要功能和特点:
- 图像风格转换:这项技术可以改变图片的风格,比如将一张普通的照片转换成卡通风格或油画风格。
- 图像编辑:它能够根据文本提示对图片进行编辑,比如把图片中的“男人”变成“女人”,或者给图片中的人物添加眼镜。
- 零样本学习:这意味着即使没有经过额外的训练,这项技术也能够理解和应用新的文本提示来进行图像编辑。
- 高效性能:与现有的一些图像生成模型相比,这项技术在保持图像质量的同时,能够更快地进行图像的生成和编辑。
工作原理:
这项技术的工作原理基于一种叫做“Rectified Flows”的模型,它通过控制随机微分方程(SDE)来生成图像。具体来说,它通过以下步骤来实现图像的生成和编辑:
- 初始化:从一个随机噪声样本开始,这个样本通过一个预训练的模型(如Flux)进行处理。
- 控制过程:通过一个称为线性二次调节器(LQR)的优化控制策略,将噪声样本转换成与目标图像一致的结构化噪声。
- 图像重建:使用生成的结构化噪声,通过逆向过程重建出图像,这个过程中可以加入新的文本提示来引导图像的编辑。

具体应用场景:
- 艺术创作:艺术家和设计师可以使用这项技术来快速实现他们的视觉想法,比如将草图转换成精美的艺术作品。
- 数字媒体:在数字媒体领域,这项技术可以用来生成或编辑图片,以适应不同的内容和风格需求。
- 游戏和电影制作:在游戏和电影的制作过程中,这项技术可以用来创建或修改角色和场景的视觉效果。
- 广告和营销:通过这项技术,可以快速地根据广告文案或营销主题来生成或编辑图像,提高工作效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











