
在AI领域,“大力出奇迹”似乎已成为一种默认法则:模型参数越大,效果越好。然而,由上海创智学院、复旦大学、中国科学技术大学、上海交通大学、浙江大学、西湖大学、南京大学以及南加州大学的研究人员共同推出的最新成果 DeepGen 1.0,正在挑战这一固有认知。
- 项目主页:https://deepgenteam.github.io
- GitHub:https://github.com/deepgenteam/deepgen
- 模型:https://huggingface.co/deepgenteam/DeepGen-1.0
这款仅有 50 亿参数 的轻量级统一多模态模型,不仅在通用图像生成和编辑任务上表现卓越,更在需要复杂逻辑推理的场景中,击败了参数量大其 3 至 16 倍的顶级模型。DeepGen 1.0 的出现证明:智能的密度比规模的广度更重要,精巧的架构设计与高效的训练策略完全可以战胜蛮力的参数堆砌。

破局:告别“参数迷信”,拥抱高效智能
当前的图像生成 AI 赛道正陷入一场“军备竞赛”。Qwen-Image 拥有 270 亿参数,HunyuanImage 3.0 更是高达 800 亿参数。这些“巨无霸”虽然性能强劲,但高昂的训练成本、巨大的显存占用以及复杂的部署门槛,将绝大多数研究机构和个人开发者拒之门外。此外,许多模型还需分别训练“生成版”和“编辑版”,进一步推高了资源消耗。
与此同时,现有的小模型(如 30 亿参数级别)往往因能力不足而难以胜任复杂任务。DeepGen 团队反其道而行之,探索出一条“高效能而非高参数”的技术路线。他们仅使用约 5000 万训练样本(相比之下,HunyuanImage 3.0 使用了 50 亿样本),就打造出了一个集五大核心能力于一身的全能模型。
全能选手:五大核心能力覆盖全场景
DeepGen 1.0 并非单一功能的工具,而是一个真正的统一多模态系统,在一个模型中完美集成了以下五种能力:
- 通用图像生成 (Text-to-Image)
无论是“一只戴着墨镜的水豚在温泉里”的趣味场景,还是“赛博朋克风格的城市夜景”的宏大构图,模型都能精准理解并高质量还原。 - 推理式生成 (Reasoning Generation)
这是 DeepGen 1.0 的杀手锏。它不仅能听懂字面指令,还能结合世界知识进行深度推理。例如,当用户要求“画一个体现‘守株待兔’成语的场景”时,模型能理解典故背后的寓意,创作出符合文化常识的画面,而非简单的字面拼接。 - 文字渲染 (Text Rendering)
解决了生成式 AI 长期以来的痛点——“乱码”。DeepGen 1.0 能在生成的图像中准确呈现中英文文字,支持多种字体、排版和风格,完美适用于海报、招牌、书籍封面等场景。 - 通用图像编辑 (General Editing)
给定一张图片和指令(如“把白天变成夜晚”、“给人物加上墨镜”),模型能精准修改指定区域,同时严格保持人物身份、背景结构等未修改部分的原貌,实现“指哪打哪”。 - 推理式编辑 (Reasoning Editing)
结合常识进行复杂编辑。例如,指令“把这张图改成春节氛围”,模型会自动联想红灯笼、春联、喜庆色彩等元素并进行合理布局;或指令“让这只动物看起来更有威胁性”,模型能基于动物行为学知识调整姿态和光影。
核心技术:如何让“小脑瓜”拥有“大智慧”?
DeepGen 1.0 之所以能以小博大,归功于其创新的架构设计和训练策略。
1. 双骨干架构:理解脑 + 创作手
模型由两个高效模块组成:
- 视觉语言模型 (VLM):基于 30 亿参数的 Qwen-2.5-VL,充当“艺术总监”,负责深度理解用户指令和参考图片。
- 扩散 Transformer (DiT):基于 20 亿参数的 SD3.5-Medium,充当“王牌画家”,负责执行具体的像素生成。
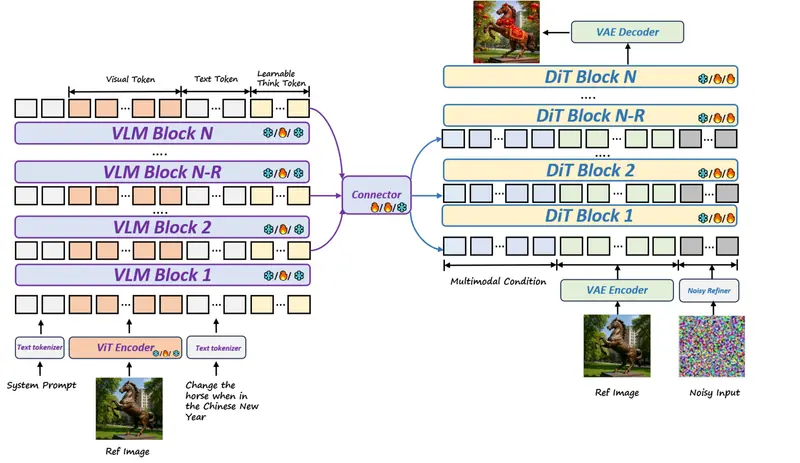
2. 堆叠通道桥接 (SCB):拒绝信息丢失
传统方法通常只提取 VLM 的最后一层输出给 DiT,这如同只听总监的“总结发言”,丢失了大量细节。DeepGen 1.0 创新性地引入了堆叠通道桥接技术:
- 思考令牌 (Thinking Tokens):在输入中插入 128 个可学习的令牌,构建隐式的思维链,引导模型进行深度推理。
- 多层特征融合:同时提取 VLM 的低层(细节)、中层(结构)和高层(语义)特征,通过轻量级连接器融合,确保“画家”能获得从微观纹理到宏观意图的全方位指导。
3. 三阶段渐进训练:步步为营
- 阶段一:对齐预训练。仅训练连接器和思考令牌,利用大规模图文对建立基础感知能力。
- 阶段二:联合监督微调。解冻全模型,使用 LoRA 技术在高质量混合数据(生成、编辑、推理、文字渲染)上进行微调,培养全能身手。
- 阶段三:强化学习优化 (MR-GRPO)。引入混合奖励函数(视觉质量、文字准确性、语义对齐),并独创辅助监督损失机制,防止模型在强化学习中“顾此失彼”或能力退化,确保越练越强。
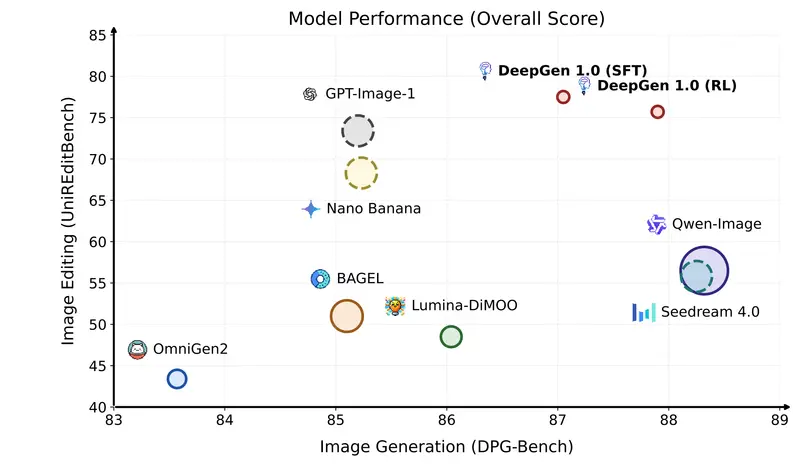
实测成绩:小身材,大能量
在多个权威基准测试中,DeepGen 1.0 交出了一份令人惊艳的成绩单:
- 推理能力碾压巨头:在 WISE 基准(世界知识推理)中,DeepGen 1.0 得分 0.73,位居开源模型第一,比 800 亿参数的 HunyuanImage 3.0(0.57)高出 28%。
- 编辑能力遥遥领先:在 UniREditBench 中,得分 77.5,比 270 亿参数的 Qwen-Image-Edit(56.5)高出 37%。
- 文字渲染精准度提升:经过强化学习优化,文字准确率从 0.66 提升至 0.75,同时保持了极高的语义一致性。
- 综合性能均衡:在 UniGenBench 综合评测中排名第二,证明了其在属性绑定、风格控制等十个维度上的均衡发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











