
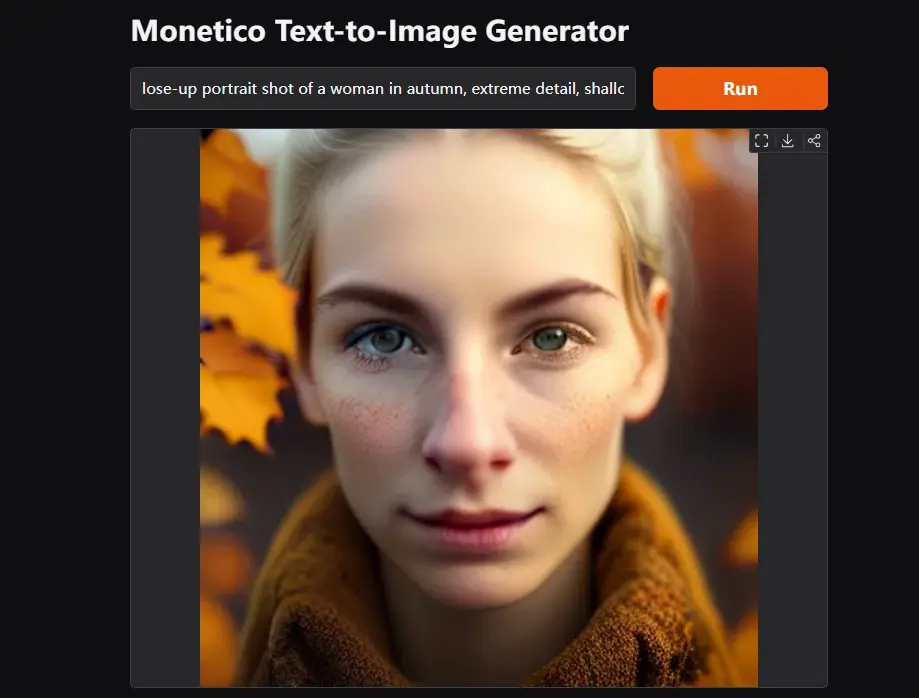
Collov Labs 最近在8块H100 GPU上训练了一周时间,推出了新的非自回归掩码图像建模的文本到图像合成模型——Monetico。这款模型能够生成高分辨率图像,并且被设计为在消费级显卡上高效运行。尽管官方释出的Demo仅能生成512x512图像,但在非自回归模型领域,Monetico仍然具有重要意义。(相关:非自回归 MIM 文生图合成模型Meissonic:生成高质量、高分辨率的图像)
- 模型:https://huggingface.co/Collov-Labs/Monetico
- Demo:https://huggingface.co/spaces/Collov-Labs/Monetico
主要特点
1、非自回归模型
掩码图像建模:Monetico采用非自回归掩码图像建模技术,能够在生成过程中并行处理多个像素,显著提高了生成速度。 高效生成:相比自回归模型,非自回归模型在生成高分辨率图像时速度更快,效率更高。
2、高分辨率图像生成
支持高分辨率:Monetico能够生成高分辨率图像,适用于需要高质量图像的各种应用场景。 消费级显卡支持:模型被设计为在消费级显卡上高效运行,降低了硬件门槛,使得更多用户能够使用这一技术。
3、官方Demo
512x512图像:目前官方释出的Demo仅支持生成512x512分辨率的图像,尽管这一分辨率已经能满足许多应用场景的需求,但对于需要更高分辨率的用户来说,可能还不够实用。
4、与其他模型的对比
Flux和SD3.5:目前主流的开源模型如Flux和SD3.5已经能够生成更高分辨率的图像,Monetico在这一方面暂时处于劣势。然而,Monetico在生成速度和消费级显卡支持方面具有明显优势。
技术细节
训练环境:Monetico在8块H100 GPU上训练了一周时间,这种高性能计算环境确保了模型能够学习到复杂的图像生成模式。 模型架构:采用非自回归掩码图像建模技术,通过并行处理多个像素,显著提高了生成速度和效率。 优化算法:模型经过精心优化,能够在消费级显卡上高效运行,降低了硬件要求,使得更多用户能够受益。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











