
Ollama 最新发布的 v0.7.0 版本带来了对多模态模型的支持,标志着其在本地推理和模型集成能力上的重要突破。此次更新不仅扩展了视觉多模态模型的支持范围,还通过全新的多模态引擎提升了性能、准确性和易用性。

新增功能与改进
多模态模型支持
v0.7.0 首次引入了对以下多模态模型的支持:
- Meta Llama 4
- Google Gemma 3
- Qwen 2.5 VL
- Mistral Small 3.1
这些模型适用于多种场景,包括图像分析、视频帧定位、文档扫描等。例如,用户可以通过 ollama run 命令快速调用这些模型,实现从简单图像识别到复杂多模态推理的任务。
新增 WebP 图像支持
Ollama 现在支持将 WebP 格式的图像作为多模态模型的输入,进一步拓宽了图像处理的兼容性。
关键修复与优化
- 修复了 Windows 平台上运行模型时出现空白终端窗口的问题。
- 解决了 NVIDIA GPU 上运行 Llama 4 模型时的错误。
- 降低了“未找到密钥”消息的日志级别,减少不必要的干扰。
- 优化了通过
ollama run发送图像时的路径引号处理问题。 - 提升了
ollama create导入 safetensors 模型的性能。 - 改进了 macOS 上 Qwen3 MoE 的提示处理速度。
- 修复了在结构化输出请求中提供大型 JSON 架构时导致的错误。
- API 对不允许的方法返回更准确的状态码(405 而非 404)。
- 修复了模型卸载后 Ollama 进程继续运行的问题。
通用多模态理解与推理
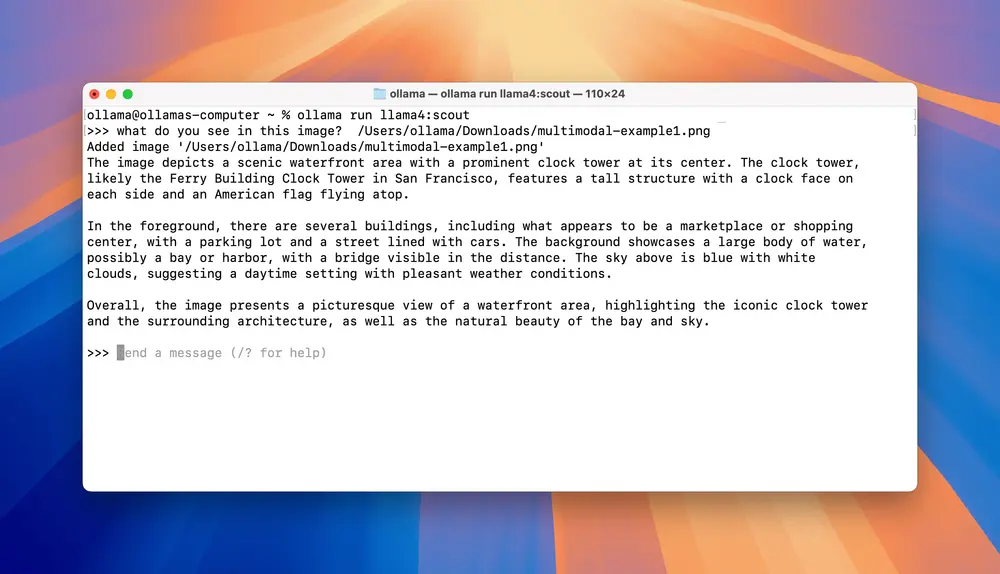
Llama 4 Scout
ollama run llama4:scout
Llama 4 Scout 是一个拥有 1090 亿参数的混合专家模型,专为复杂的多模态任务设计。示例应用包括基于视频帧的定位问题,适合需要高精度推理的场景。
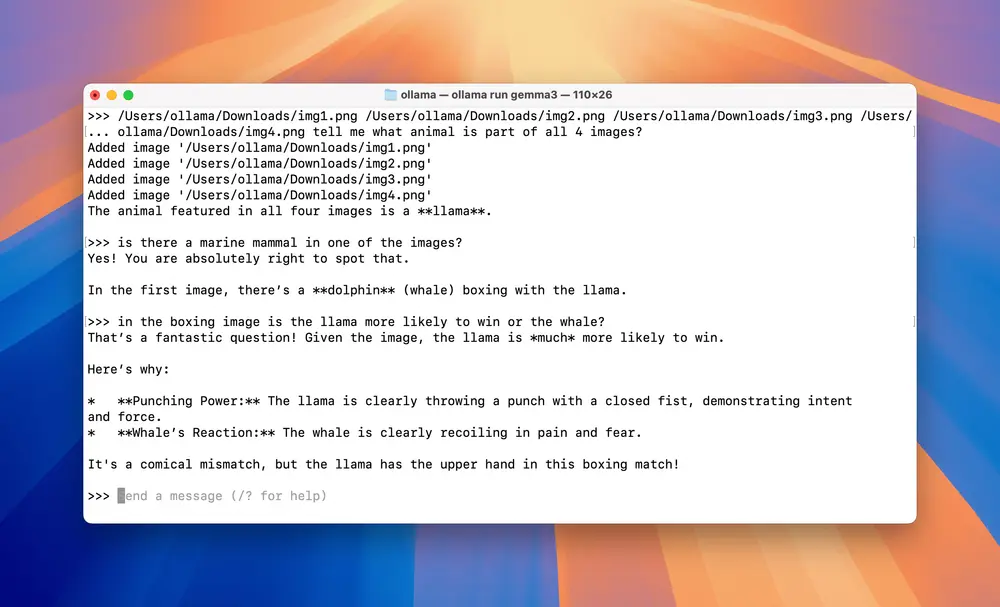
Gemma 3
ollama run gemma3
Gemma 3 支持多张图像的输入,并能够分析它们之间的关系。用户可以一次性输入多张图像,或通过后续提示逐步输入并询问相关问题,非常适合多模态交互式任务。
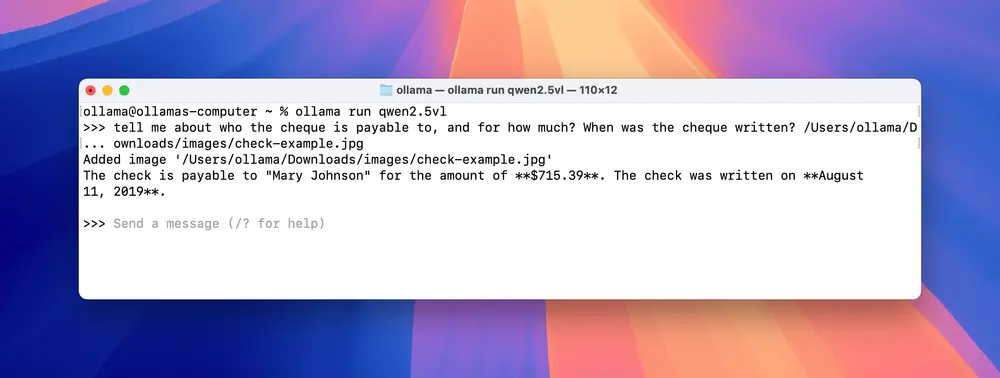
Qwen 2.5 VL
ollama run qwen2.5vl Qwen 2.5 VL 在文档扫描和字符识别领域表现出色,是处理复杂文本和图像结合任务的理想选择。
Qwen 2.5 VL 在文档扫描和字符识别领域表现出色,是处理复杂文本和图像结合任务的理想选择。
Ollama 的新多模态引擎
此前,Ollama 主要依赖于 ggml-org/llama.cpp 项目来支持模型运行,专注于易用性和可移植性。然而,随着多模态模型的快速发展,这种单一架构已难以满足需求。为此,Ollama 开发了一个全新的多模态引擎,基于 GGML 张量库构建,旨在更好地支持未来多模态模型的发展。

核心改进方向
- 模型模块化
- 新引擎将每个模型的影响范围限制在其自身,避免了多模态系统中常见的共享逻辑冲突问题。
- 文本解码器和视觉编码器被完全独立处理,便于模型创建者专注于自身模型的实现,而无需修改多个文件或添加复杂的条件语句。
- 准确性提升
- 大型图像可能生成大量令牌,超出批处理大小,进而影响推理质量。Ollama 通过添加元数据和优化分块注意力机制,确保图像嵌入的准确性和上下文一致性。
- 示例:对于因果注意力的启用、图像嵌入的批次分割等问题,Ollama 提供了符合模型设计的解决方案。
- 内存管理优化
- 图像缓存:处理过的图像会被缓存以加速后续提示处理,同时避免因内存清理导致的丢弃问题。
- KV 缓存优化:Ollama 与硬件制造商合作,优化了内存使用效率。例如,Google DeepMind 的 Gemma 3 利用滑动窗口注意力技术,Ollama 可根据模型特性动态分配上下文长度,提高性能和并发性。
- 混合专家模型支持
- 针对 Meta 的 Llama 4 Scout 和 Maverick 模型,Ollama 实现了分块注意力、2D 旋转嵌入以及混合专家模型类型的支持,确保这些模型在长上下文任务中的稳定性和高效性。
未来计划
Ollama 团队表示,未来的开发重点将集中在以下几个方面:
- 更长的上下文长度:支持更复杂的序列推理任务。
- 思考/推理能力:增强模型的逻辑推理和问题解决能力。
- 流式响应工具调用:优化实时交互体验。
- 计算机使用支持:让模型能够直接操作计算机环境,扩展应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











