多模态模型RoboBrain:让机器人从抽象指令到具体操作的多模态大脑近年来,多模态大语言模型(MLLMs)在多种场景中展现了卓越的能力,但在机器人领域,尤其是在长时段复杂操作任务中,其表现仍存在显著局限性。这些局限主要源于当前 MLLMs 缺乏三种关键能力:规划能力...多模态模型# RoboBrain# 多模态模型# 机器人11个月前02460
Yo’Chameleon:使大型多模态模型(LMM)实现个性化视觉和语言生成能力威斯康星大学麦迪逊分校和Adobe Research的研究人员推出新型框架Yo’Chameleon,为大型多模态模型(LMMs)实现个性化视觉和语言生成能力。Yo’Chameleon 通过软提示调...新技术# Yo’Chameleon# 多模态模型11个月前04450
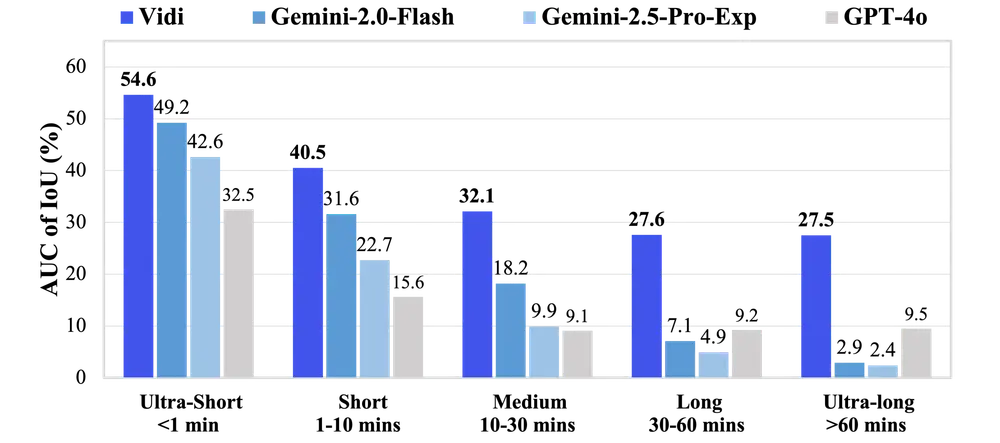
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动11个月前02330
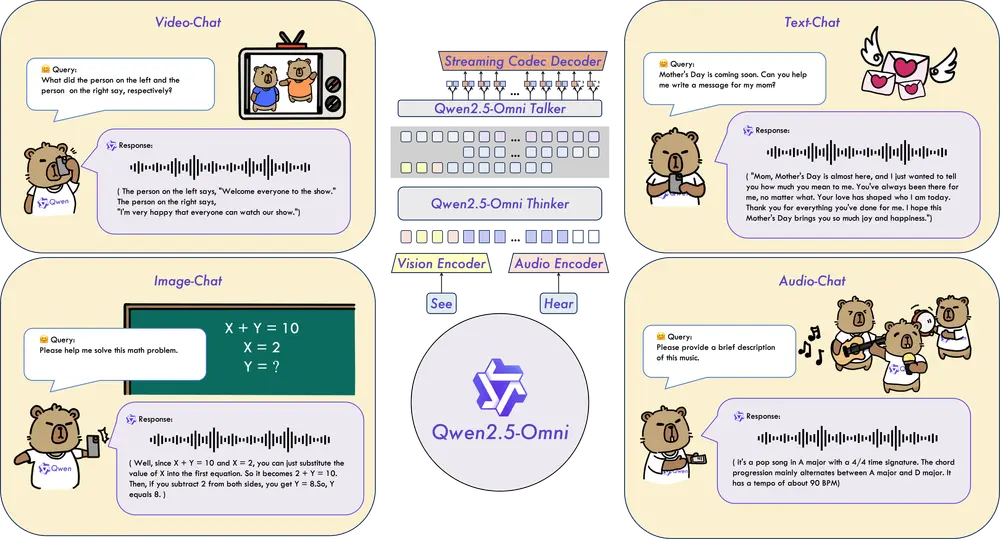
阿里通义实验室发布新一代端到端多模态旗舰模型Qwen2.5-Omni阿里通义实验室发布了 Qwen2.5-Omni,这是 Qwen 模型家族中的新一代端到端多模态旗舰模型。Qwen2.5-Omni 专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入...多模态模型# Qwen2.5-Omni# 多模态模型1年前02670
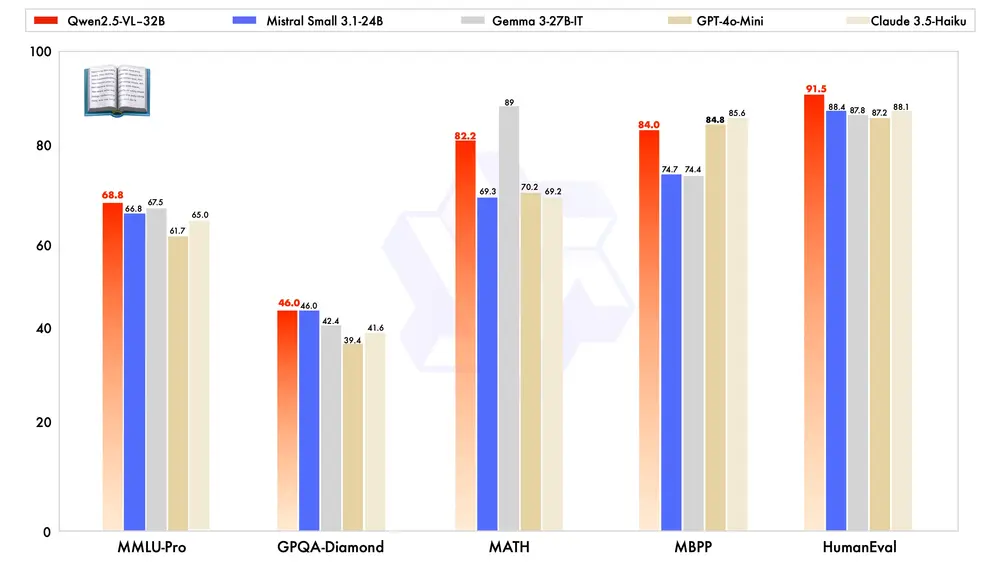
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室1年前03270
新型图像生成框架DREAM ENGINE:结合多模态模型和扩散模型,实现复杂文本-图像交错控制的图像生成任务北京大学、阿里巴巴集团、华盛顿大学、北京理工大学和百安斯实验室的研究人员推出新型图像生成框架 DREAM ENGINE,它通过两阶段训练方法,将 QwenVL 等多模态编码器与扩散模型集成在一起,从而...图像模型# DREAM ENGINE# 图像生成# 多模态模型1年前03480
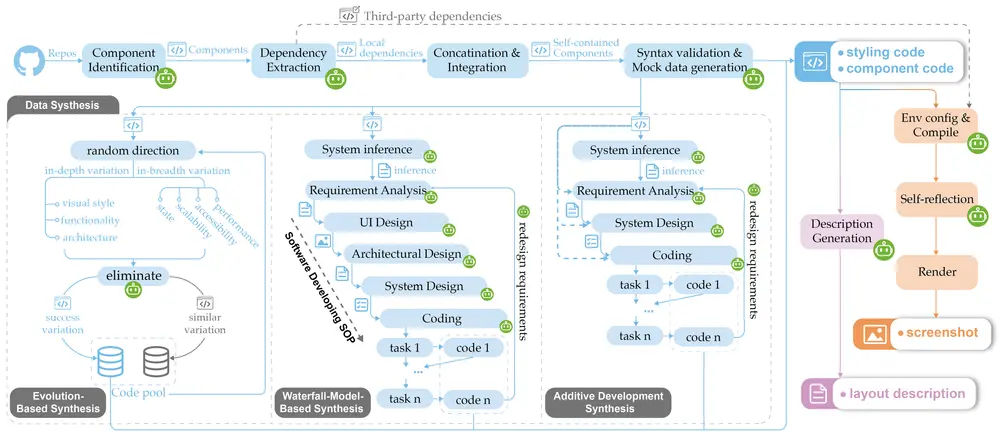
首个截图就能生成现代前端代码的多模态模型Flame尽管前沿的多模态模型(如 GPT-4O)在代码生成上展现了强大的能力,但它们在真实的前端开发场景中仍无法满足现代前端工作流程的动态需求。这些模型虽然能够生成代码,但输出的前端代码通常是静态的,缺乏模块...多模态模型# Flame# 前端代码# 多模态模型1年前04260
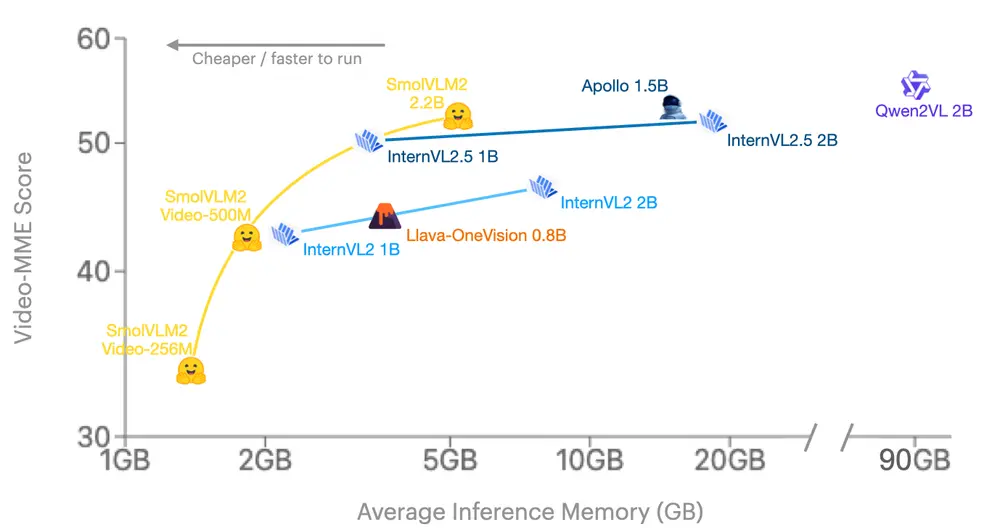
Hugging Face 发布轻量级多模态模型SmolVLM2:专为视频内容分析而设计Hugging Face 最新发布了一款轻量级多模态模型SmolVLM2,专为视频内容分析而设计。该模型以高效性和适应性为核心目标,旨在将视频理解能力扩展到从手机到服务器的各种设备上。SmolVLM2...多模态模型# Hugging Face# SmolVLM2# 多模态模型1年前03160
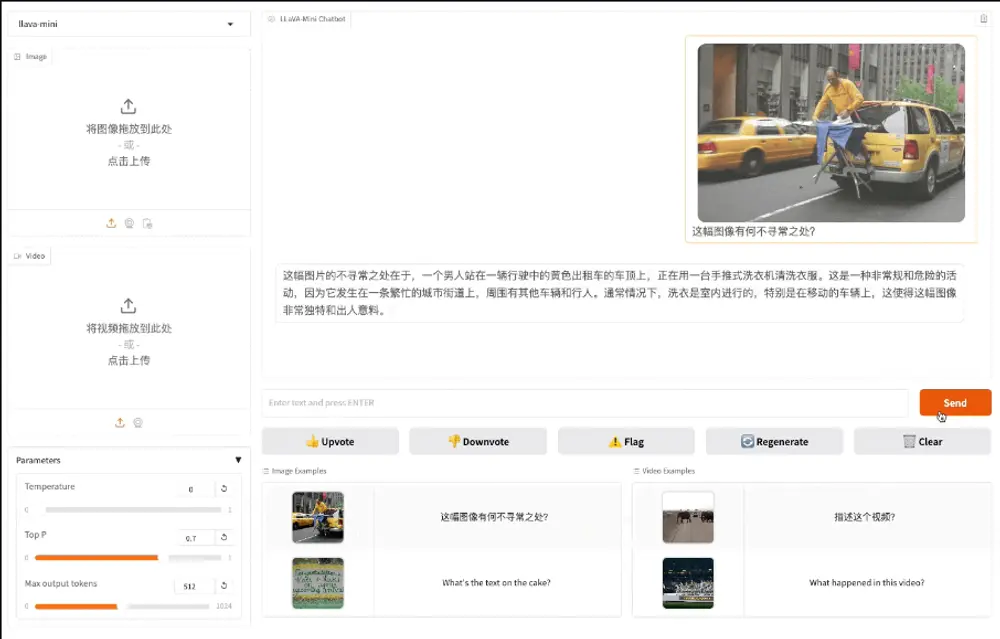
高效大型多模态模型LLaVA-Mini:通过最小化视觉令牌(vision tokens)的数量来提高模型的计算效率和响应速度中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出高效大型多模态模型LLaVA-Mini,旨在通过最小化视觉令牌(visi...多模态模型# LLaVA-Mini# 多模态模型1年前02980
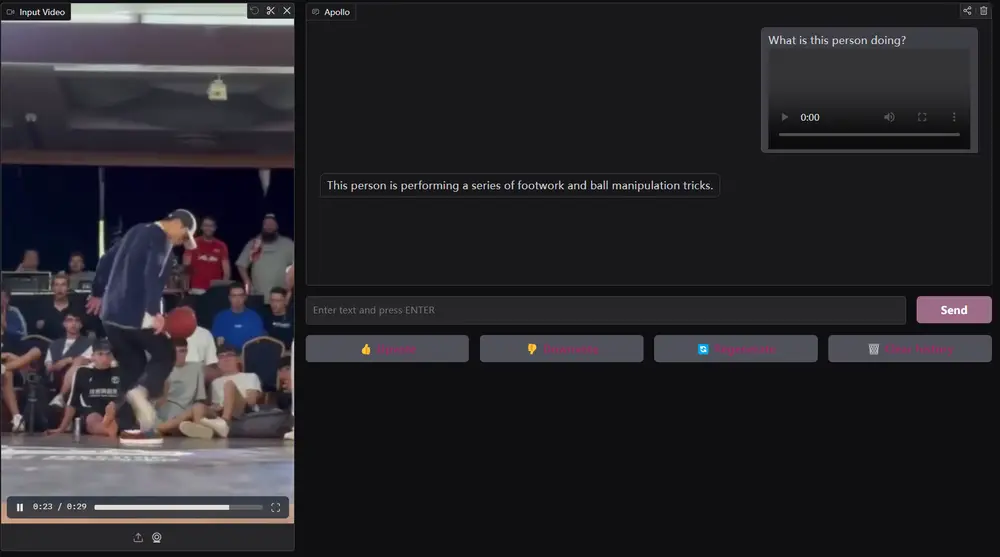
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型1年前03100
StreamChat:增强大型多模态模型(LMMs)与流媒体视频内容的交互能力香港中文大学、英伟达、上海人工智能实验室、InnoHK和香港理工大学的研究人员推出新型方法StreamChat,它旨在增强大型多模态模型(LMMs)与流媒体视频内容的交互能力。在流媒体交互场景中,现有...新技术# StreamChat# 多模态模型1年前03100
Inst-IT:增强大型多模态模型实例级理解能力复旦大学计算机学院、上海创新学院和华为诺亚方舟实验室的研究人员提出了Inst-IT,这是一种通过明确的视觉提示指令调优来增强大型多模态模型(LMMs)实例级理解能力的解决方案。尽管现有的LMMs在整体...新技术# Inst-IT# 多模态模型1年前03070