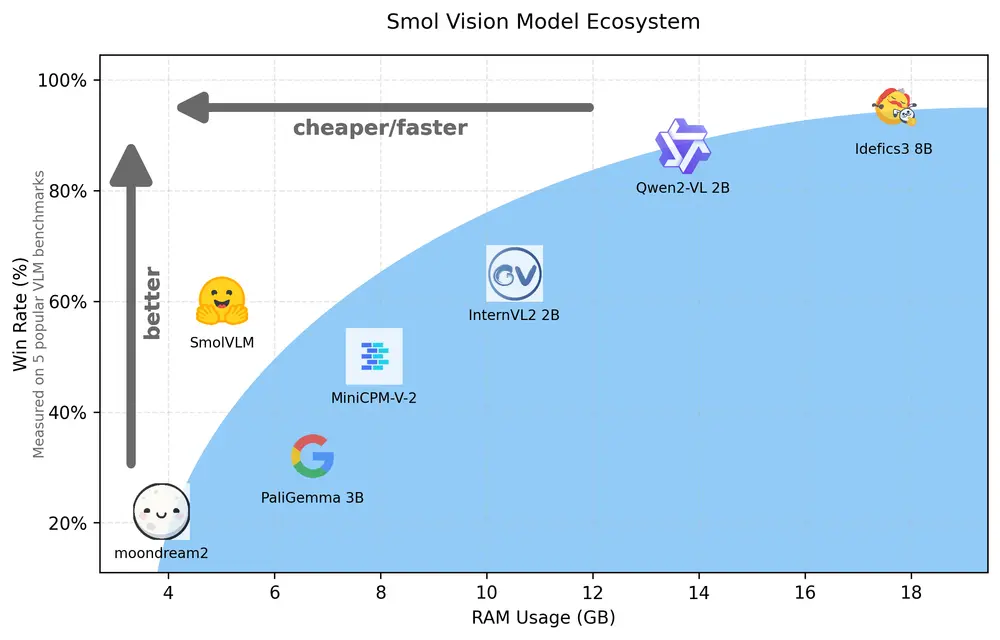
Hugging Face发布一个用于设备上推理的2B参数小型多模态模型SmolVLM近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制...多模态模型# Hugging Face# SmolVLM# 多模态模型1年前02990
深度求索推出新颖自回归框架 Janus: 具有图像生成功能的 13 亿多模态模型多模态AI模型是能够理解和生成视觉内容的强大工具。然而,现有方法通常使用单一视觉编码器来处理这两项任务,这导致了由于理解和生成在本质上不同的需求而表现不佳。理解需要高层次的语义抽象,而生成则关注局部细...多模态模型# Janus# 多模态模型1年前09320
新型多模态原生模型Aria:专门设计来处理和理解多种类型的信息(文本、代码、图像和视频)Rhymes AI推出新型多模态原生模型Aria,这是一个开源的混合专家(MoE)模型,ARIA专门设计来处理和理解多种类型的信息,比如文本、代码、图像和视频,而且它能够像人类一样,不需要特别区分这些...多模态模型# Aria# Rhymes AI# 多模态模型1年前05730
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型1年前05690
新型开源大型多模态模型LLaVA-Critic:用于评估各种多模态任务的性能字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的...多模态模型# LLaVA-Critic# 多模态模型1年前04460
智源研究院推出全新多模态系列模型Emu3智源研究院推出Emu3,这是一个全新的多模态系列模型,它仅使用下一个词元(Token)预测这一建模范式进行训练,达到了最先进的水平。Emu3 通过一个 Transformer 模型在视频、图像和文本令...多模态模型# Emu3# 多模态模型# 智源研究院1年前04270
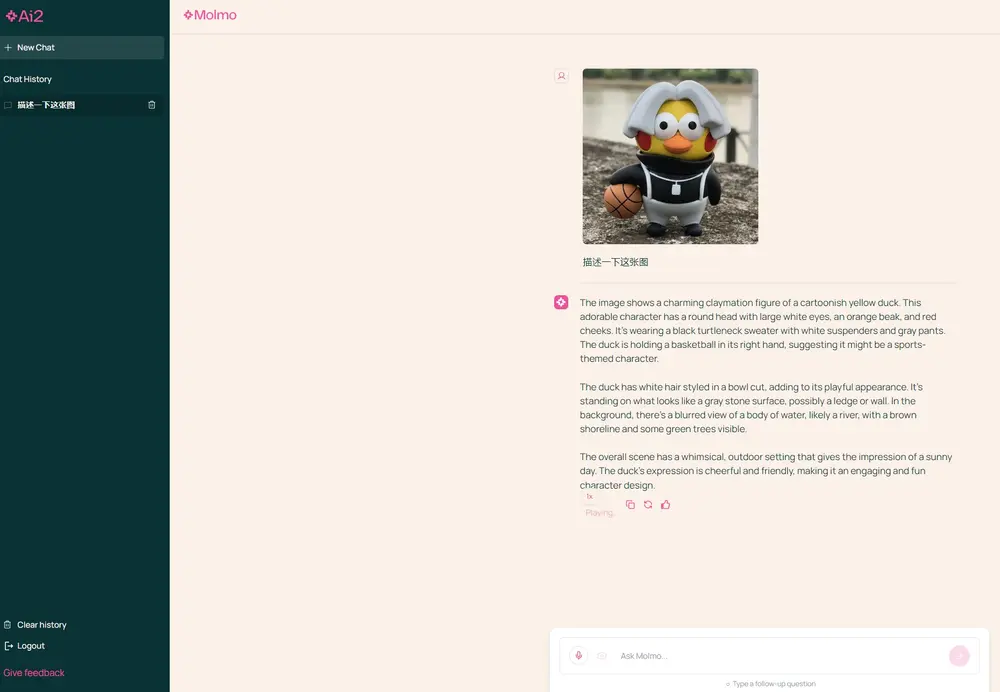
新型多模态模型家族Molmo:专门设计用于理解和处理图像和文本数据华盛顿大学和艾伦人工智能研究所的研究人员推出新型多模态模型家族Molmo,这些模型专门设计用于理解和处理图像和文本数据。Molmo的目标是提供一个最先进的、开放的多模态模型,Molmo的关键创新是一个...多模态模型# Molmo# 多模态模型1年前04600
多模态模型Transfusion:能够同时处理离散数据(如文本)和连续数据(如图像)Meta、Waymo和南加州大学的研究人员推出多模态模型Transfusion,它能够同时处理离散数据(如文本)和连续数据(如图像)。Transfusion的核心思想是将语言模型的下一个词预测(nex...新技术# Transfusion# 多模态模型2年前07640
阿里推出新型大型多模态模型ConvLLaVA:专门设计用于处理高分辨率的视觉数据清华大学和阿里巴巴的研究人员推出新型大型多模态模型ConvLLaVA,它专门设计用于处理高分辨率的视觉数据。多模态模型能够理解和处理多种类型的数据,比如文本、图像和视频,这使得它们在各种应用场景中都非...新技术# ConvLLaVA# 多模态模型# 阿里巴巴2年前07210