深度求索推出新颖自回归框架 Janus: 具有图像生成功能的 13 亿多模态模型多模态AI模型是能够理解和生成视觉内容的强大工具。然而,现有方法通常使用单一视觉编码器来处理这两项任务,这导致了由于理解和生成在本质上不同的需求而表现不佳。理解需要高层次的语义抽象,而生成则关注局部细...多模态模型# Janus# 多模态模型1年前09320
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型10个月前09170
多模态模型Transfusion:能够同时处理离散数据(如文本)和连续数据(如图像)Meta、Waymo和南加州大学的研究人员推出多模态模型Transfusion,它能够同时处理离散数据(如文本)和连续数据(如图像)。Transfusion的核心思想是将语言模型的下一个词预测(nex...新技术# Transfusion# 多模态模型2年前07640
阿里推出新型大型多模态模型ConvLLaVA:专门设计用于处理高分辨率的视觉数据清华大学和阿里巴巴的研究人员推出新型大型多模态模型ConvLLaVA,它专门设计用于处理高分辨率的视觉数据。多模态模型能够理解和处理多种类型的数据,比如文本、图像和视频,这使得它们在各种应用场景中都非...新技术# ConvLLaVA# 多模态模型# 阿里巴巴2年前07210
Ollama v0.7.0发布:添加新多模态模型引擎,多模态模型支持全面升级Ollama 最新发布的 v0.7.0 版本带来了对多模态模型的支持,标志着其在本地推理和模型集成能力上的重要突破。此次更新不仅扩展了视觉多模态模型的支持范围,还通过全新的多模态引擎提升了性能、准确性...早报# Ollama# 多模态模型# 多模态模型引擎11个月前05740
新型多模态原生模型Aria:专门设计来处理和理解多种类型的信息(文本、代码、图像和视频)Rhymes AI推出新型多模态原生模型Aria,这是一个开源的混合专家(MoE)模型,ARIA专门设计来处理和理解多种类型的信息,比如文本、代码、图像和视频,而且它能够像人类一样,不需要特别区分这些...多模态模型# Aria# Rhymes AI# 多模态模型1年前05730
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型1年前05690
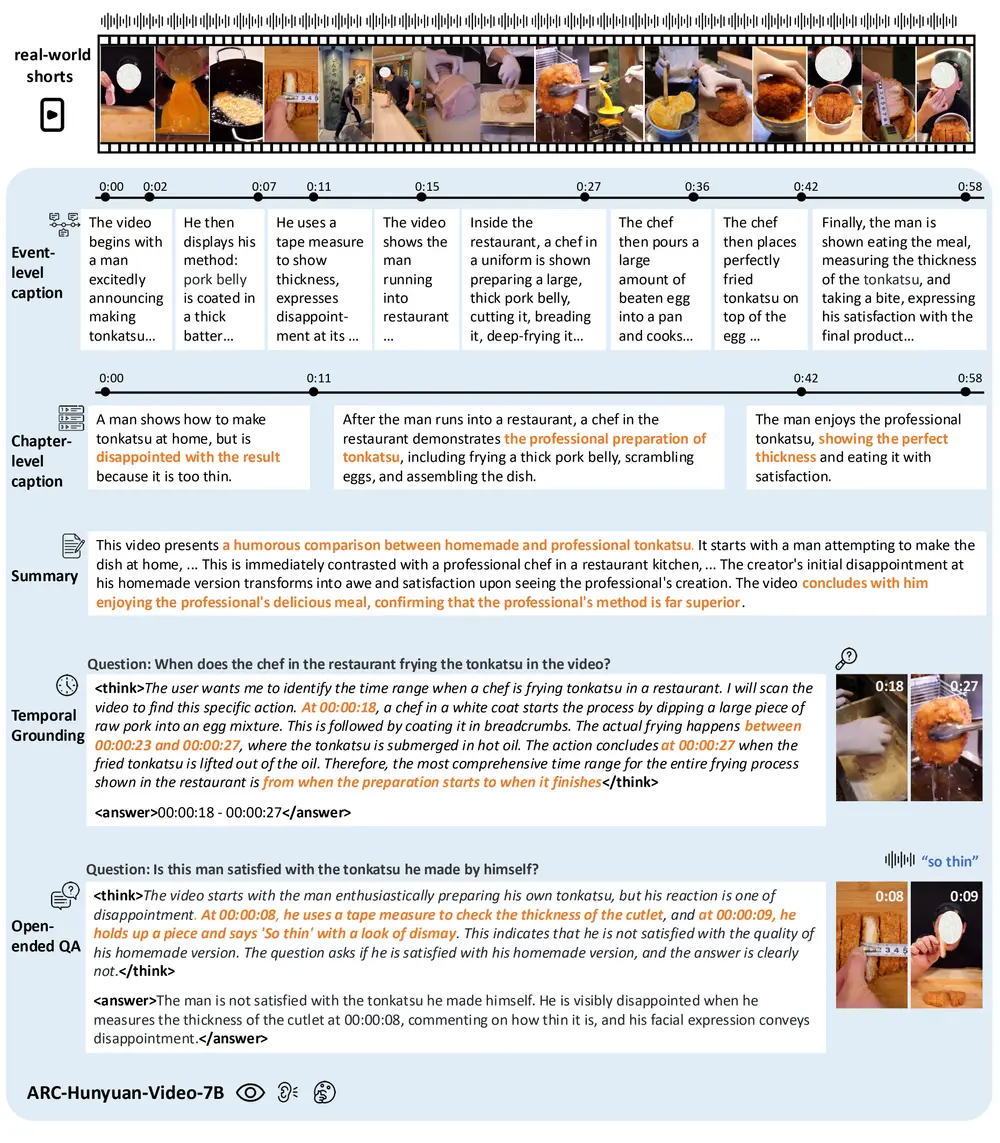
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室8个月前05520
新型多模态模型家族Molmo:专门设计用于理解和处理图像和文本数据华盛顿大学和艾伦人工智能研究所的研究人员推出新型多模态模型家族Molmo,这些模型专门设计用于理解和处理图像和文本数据。Molmo的目标是提供一个最先进的、开放的多模态模型,Molmo的关键创新是一个...多模态模型# Molmo# 多模态模型1年前04600
新型开源大型多模态模型LLaVA-Critic:用于评估各种多模态任务的性能字节跳动和马里兰大学帕克分校的研究人员推出新型开源大型多模态模型LLaVA-Critic,它被设计成一个全能的评估者,用于评估各种多模态任务的性能。多模态任务通常涉及理解和生成与图像、视频和文本相关的...多模态模型# LLaVA-Critic# 多模态模型1年前04460
Yo’Chameleon:使大型多模态模型(LMM)实现个性化视觉和语言生成能力威斯康星大学麦迪逊分校和Adobe Research的研究人员推出新型框架Yo’Chameleon,为大型多模态模型(LMMs)实现个性化视觉和语言生成能力。Yo’Chameleon 通过软提示调...新技术# Yo’Chameleon# 多模态模型11个月前04450
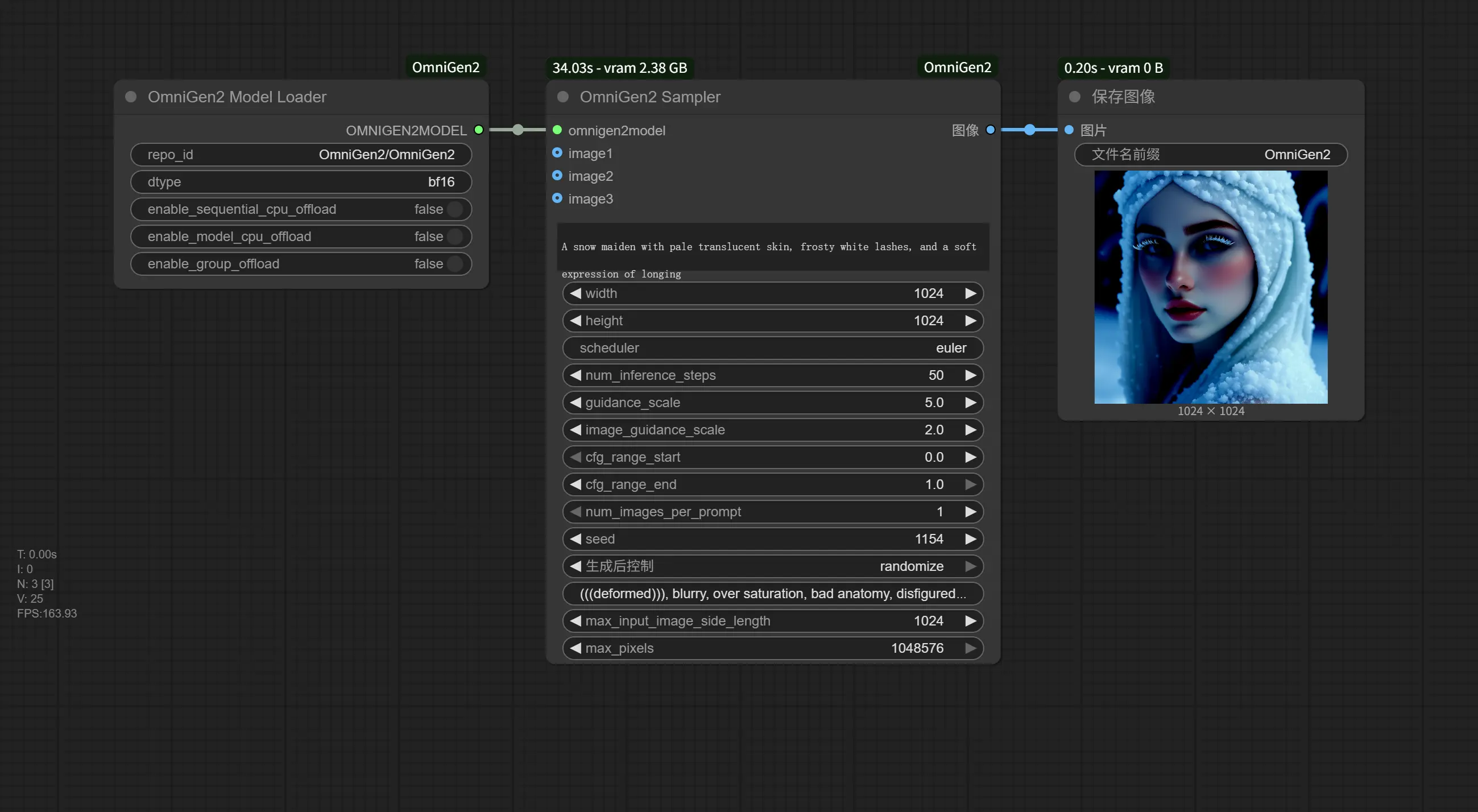
ComfyUI-OmniGen2:为多模态模型OmniGen2 打造的 ComfyUI 自定义节点插件北京AI研究院发布的集成了视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力的统一多模态模OmniGen2,如果你希望在 ComfyUI 中实现图像生成、编辑和视觉理解任务,那么 Com...插件# ComfyUI# OmniGen2# 多模态模型9个月前04420