智源研究院推出全新多模态系列模型Emu3智源研究院推出Emu3,这是一个全新的多模态系列模型,它仅使用下一个词元(Token)预测这一建模范式进行训练,达到了最先进的水平。Emu3 通过一个 Transformer 模型在视频、图像和文本令...多模态模型# Emu3# 多模态模型# 智源研究院1年前04270
首个截图就能生成现代前端代码的多模态模型Flame尽管前沿的多模态模型(如 GPT-4O)在代码生成上展现了强大的能力,但它们在真实的前端开发场景中仍无法满足现代前端工作流程的动态需求。这些模型虽然能够生成代码,但输出的前端代码通常是静态的,缺乏模块...多模态模型# Flame# 前端代码# 多模态模型1年前04260
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动9个月前04040
昆仑万维天工项目组推出多模态模型Skywork UniPic:能够统一处理图像理解、文本到图像生成和图像编辑等多种任务昆仑万维天工项目组推出多模态模型Skywork UniPic,它是一个参数量为15亿的自回归模型,能够统一处理图像理解、文本到图像生成和图像编辑等多种任务,而无需针对每个任务单独适配或连接模块。 Gi...多模态模型# Skywork UniPic# 多模态模型8个月前03850
新型图像生成框架DREAM ENGINE:结合多模态模型和扩散模型,实现复杂文本-图像交错控制的图像生成任务北京大学、阿里巴巴集团、华盛顿大学、北京理工大学和百安斯实验室的研究人员推出新型图像生成框架 DREAM ENGINE,它通过两阶段训练方法,将 QwenVL 等多模态编码器与扩散模型集成在一起,从而...图像模型# DREAM ENGINE# 图像生成# 多模态模型1年前03480
阿里巴巴 Qwen 推出紧凑型多模态模型 Qwen3-VL 4B/8B,支持 FP8 低显存部署阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reas...多模态模型# Qwen3-VL 4B# Qwen3-VL 8B# 多模态模型6个月前03390
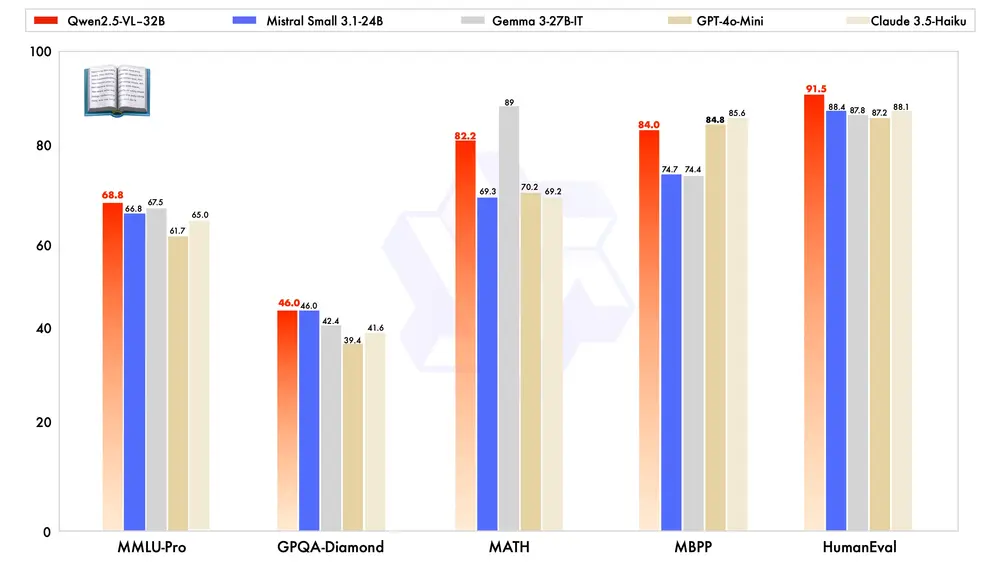
阿里通义实验室开源32B参数的多模态模型 Qwen2.5-VL-32B-Instruct今年一月底,阿里通义实验室推出了 Qwen2.5-VL 系列模型,凭借其卓越的性能和广泛的应用潜力,迅速获得了社区的广泛关注和积极反馈。在此基础上,团队通过强化学习持续优化模型,并于近期开源了备受期待...多模态模型# Qwen2.5-VL-32B-Instruct# 多模态模型# 阿里通义实验室1年前03270
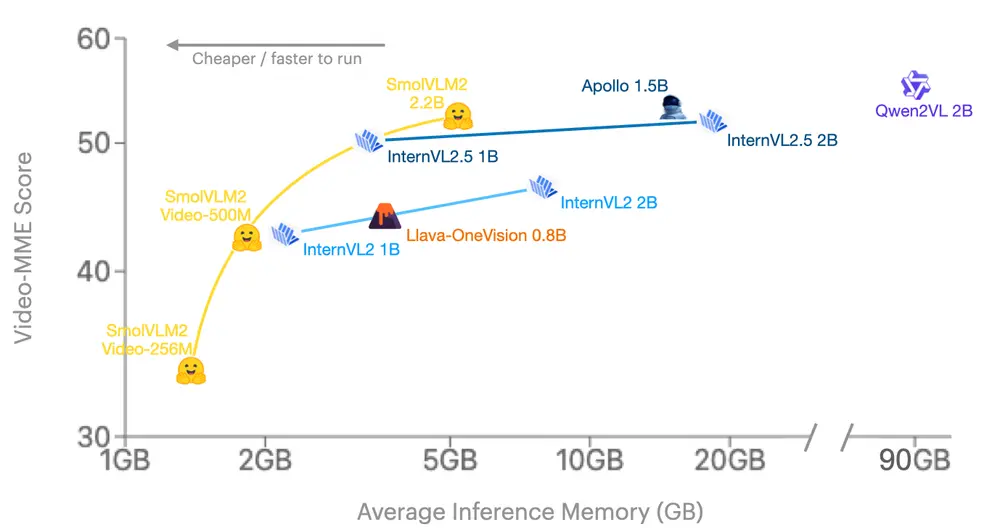
Hugging Face 发布轻量级多模态模型SmolVLM2:专为视频内容分析而设计Hugging Face 最新发布了一款轻量级多模态模型SmolVLM2,专为视频内容分析而设计。该模型以高效性和适应性为核心目标,旨在将视频理解能力扩展到从手机到服务器的各种设备上。SmolVLM2...多模态模型# Hugging Face# SmolVLM2# 多模态模型1年前03160
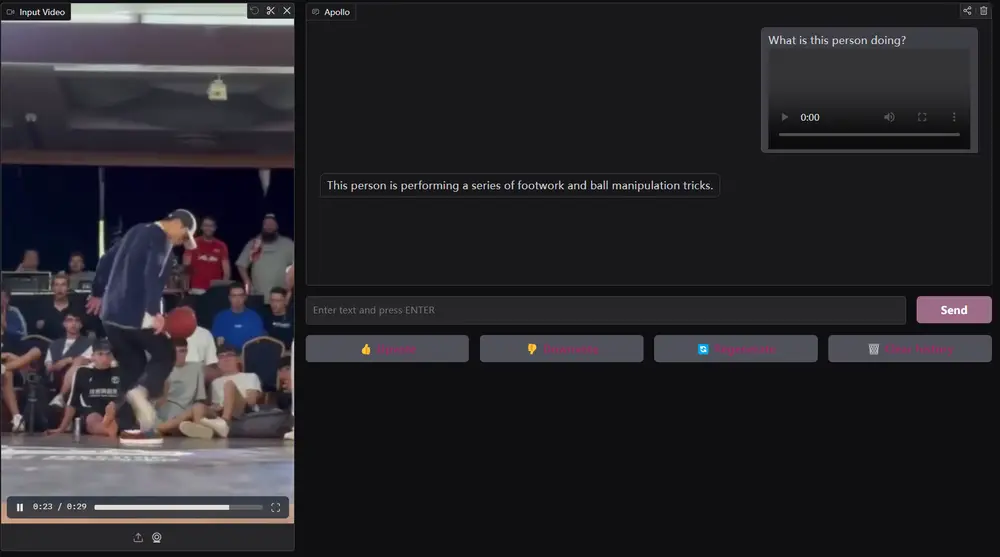
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型1年前03100
StreamChat:增强大型多模态模型(LMMs)与流媒体视频内容的交互能力香港中文大学、英伟达、上海人工智能实验室、InnoHK和香港理工大学的研究人员推出新型方法StreamChat,它旨在增强大型多模态模型(LMMs)与流媒体视频内容的交互能力。在流媒体交互场景中,现有...新技术# StreamChat# 多模态模型1年前03100
Inst-IT:增强大型多模态模型实例级理解能力复旦大学计算机学院、上海创新学院和华为诺亚方舟实验室的研究人员提出了Inst-IT,这是一种通过明确的视觉提示指令调优来增强大型多模态模型(LMMs)实例级理解能力的解决方案。尽管现有的LMMs在整体...新技术# Inst-IT# 多模态模型1年前03070
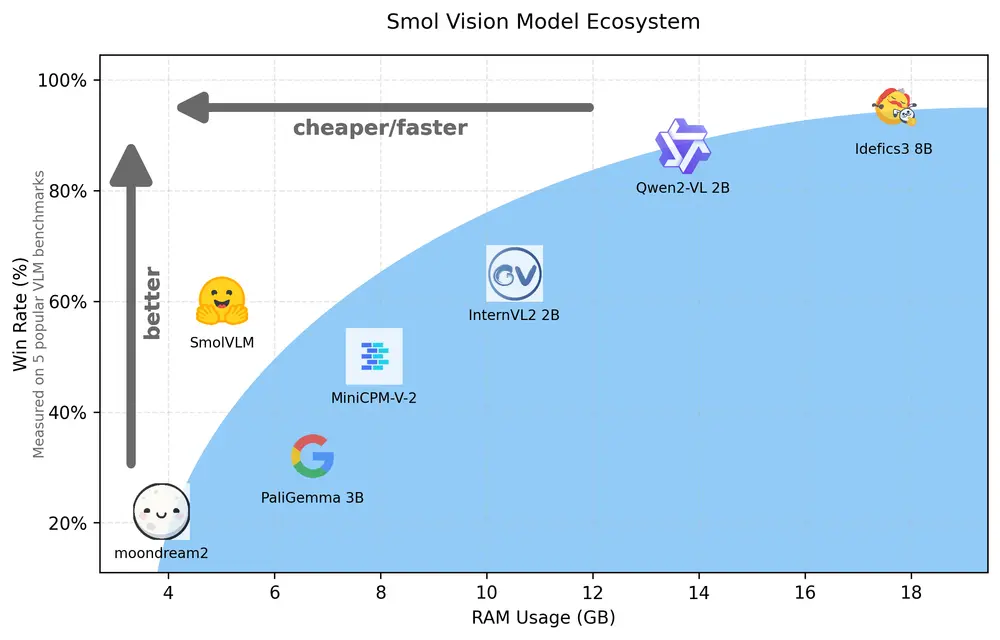
Hugging Face发布一个用于设备上推理的2B参数小型多模态模型SmolVLM近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制...多模态模型# Hugging Face# SmolVLM# 多模态模型1年前02990