
智象未来(HiDream-ai)近期开源了其交互式图像编辑大模型 HiDream-E1 及其升级版本 HiDream-E1.1,为图像生成与编辑领域提供了完整的端到端解决方案。
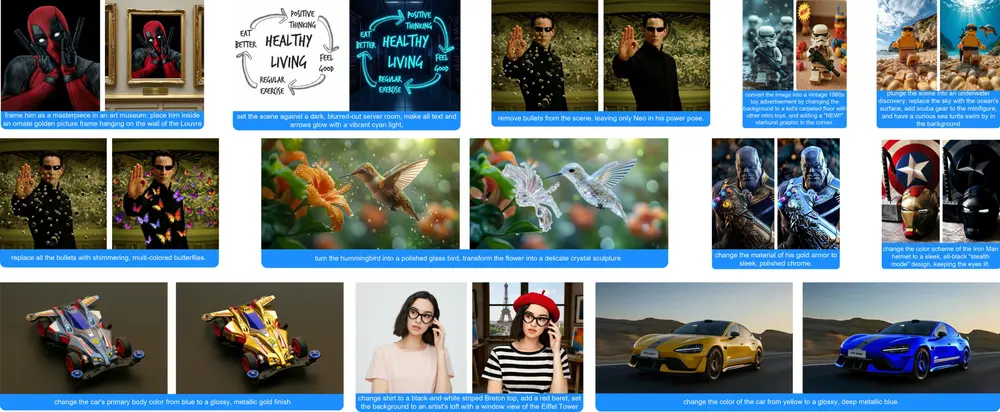
作为基于 HiDream-I1 构建的图像编辑分支,E1 系列模型支持通过自然语言指令对已有图像进行语义级修改,涵盖对象增删、风格迁移、细节增强等常见编辑任务。该系列模型采用 MIT 许可证开源,允许用于个人项目、科研实验以及商业用途。
本文将详细介绍如何在 ComfyUI 中部署并运行 HiDream-E1 和 E1.1 的原生工作流,帮助用户快速上手这一新一代交互式图像编辑工具。
模型概览:E1 与 E1.1 的核心差异
| 名称 | 发布时间 | 推理步数 | 分辨率支持 | HuggingFace 仓库 |
|---|---|---|---|---|
| HiDream-E1-Full | 2025-04-28 | 28 | 固定 768×768 | 🤗 E1-Full |
| HiDream-E1.1 | 2025-07-16 | 28 | 动态分辨率(约100万像素) | 🤗 E1.1 |
✅ 推荐使用 E1.1:相比初代版本,E1.1 在编辑精度、上下文理解能力与多尺度适应性方面均有显著提升。
- GitHub 开源地址:HiDream-E1 GitHub
环境准备:确保你的 ComfyUI 支持最新功能
由于 HiDream-E1 系列依赖较新的节点和数据处理方式,在加载工作流前,请确认以下几点:
- 使用的是 ComfyUI 最新 nightly(开发版);
- 非桌面稳定版或 release 版本(可能缺少动态图像缩放等功能);
- 启动时所有自定义节点已成功注册,无报错信息。
若出现节点缺失或加载失败,请先更新至最新 commit 并检查插件兼容性。
- 模型地址:https://huggingface.co/Comfy-Org/HiDream-I1_ComfyUI
- 魔塔地址:https://www.modelscope.cn/models/Comfy-Org/HiDream-I1_ComfyUI/summary (国内用户请从此下载)
- FP8版本:https://huggingface.co/gorillaframeai/HIDream_E1-1
- GGUF版本:https://huggingface.co/ND911/HiDream_E1_1_bf16_ggufs
所需模型文件清单
以下为 E1 与 E1.1 共用的基础组件。你无需同时下载两个 diffusion 模型,建议优先选择 E1.1。
1. Diffusion Model(二选一)
hidream_e1_1_bf16.safetensors(✅ 推荐,34.2GB)hidream_e1_full_bf16.safetensors(34.2GB)
2. Text Encoder(共四个)
clip_l_hidream.safetensors—— 236.12MBclip_g_hidream.safetensors—— 1.29GBt5xxl_fp8_e4m3fn_scaled.safetensors—— 4.8GBllama_3.1_8b_instruct_fp8_scaled.safetensors—— 8.46GB
⚠️ 注意:此组合采用四编码器架构,需全部正确加载。
3. VAE 解码模块
ae.safetensors(319.77MB)此为 Flux 系列通用 VAE,若曾使用 Flux 工作流,可能已存在本地缓存。
HiDream-E1.1 工作流操作指南
E1.1 最大特点是支持 动态百万像素输入,系统会自动调整图像总像素至约 100 万,适配不同比例图片。
1. 工作流文件及模型下载
- 从工作流模板中点击加载工作流,工作流文件中已包含模型下载信息,加载后会提示下载对应模型。
- 如果使用 E1.1 模型,推荐下载 hidream_e1_1_bf16.safetensors 文件,该模型对显存占用要求较高。
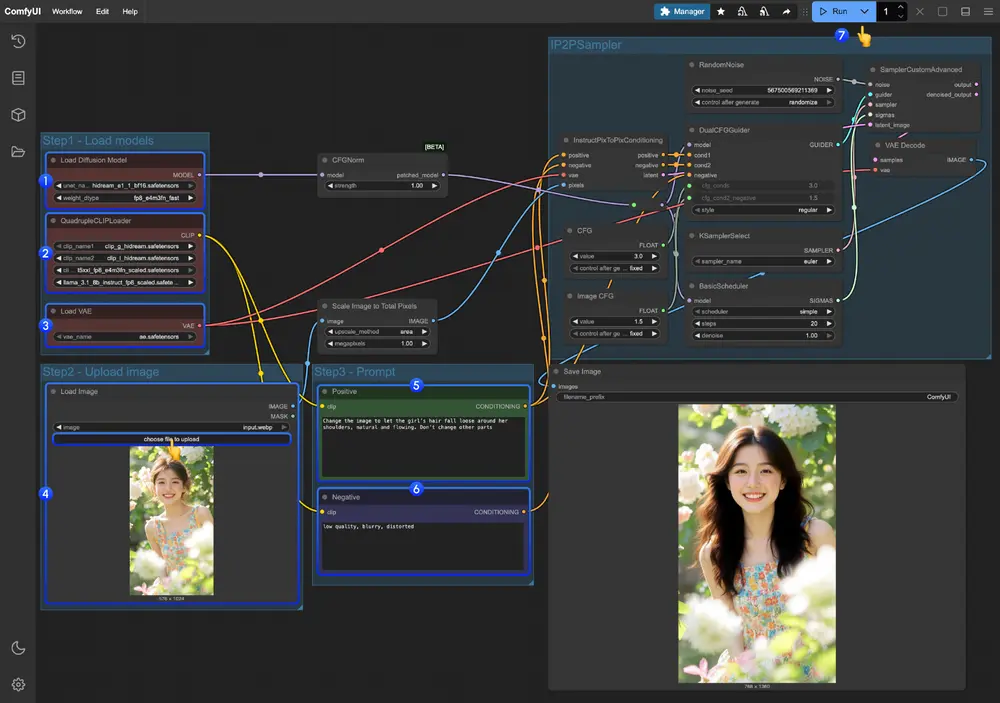
2. 工作流运行步骤
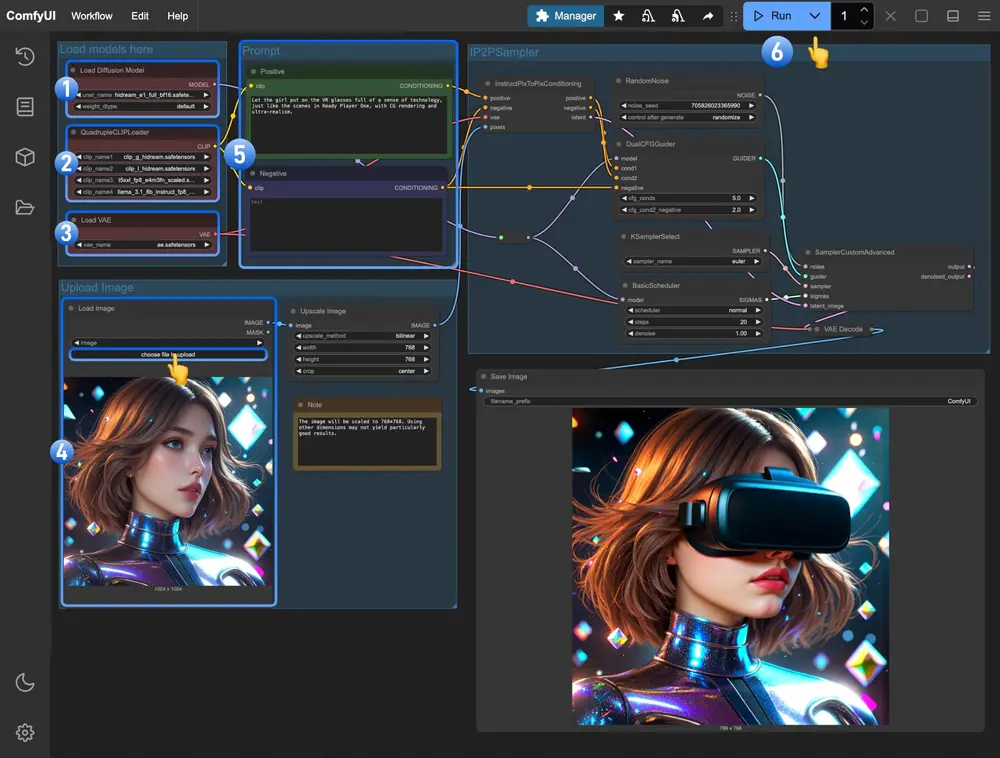
- 确保
Load Diffusion Model节点加载了 hidream_e1_1_bf16.safetensors 模型。 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载。 - 确保
Load VAE节点中使用的是 ae.safetensors 文件。 - 在
Load Image节点中加载输入图片。 - 在
Empty Text Encoder(Positive)节点中输入想要对图片进行的修改。 - 在
Empty Text Encoder(Negative)节点中输入不想要在画面中出现的内容。 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成。
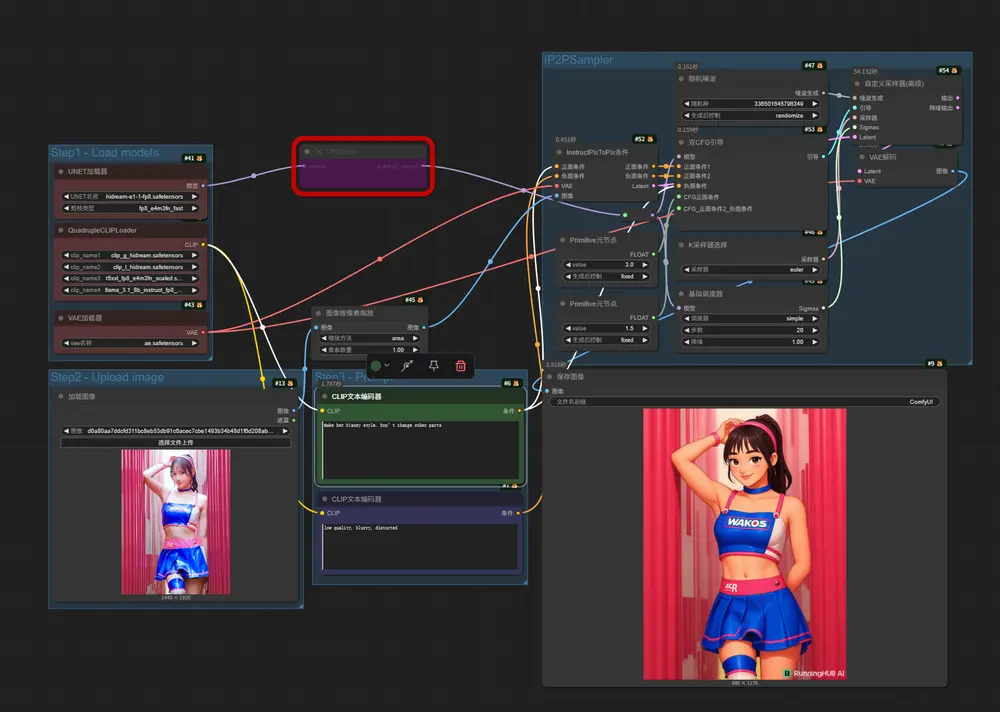
3. 工作流补充说明
- HiDream-E1.1 支持动态总像素为一百万像素输入,工作流使用了
Scale Image to Total Pixels节点来将所有输入图片进行处理转化,可能会导致比例尺寸相对于输入图片有所变化。 - 使用 fp16 版本的模型,在 A100 40GB 和 4090D 24GB 时使用完整版本会 Out of memory,所以工作流默认设置了使用 fp8_e4m3fn_fast 来进行推理。
4. 配置关键节点
请逐一核对以下设置:
| 节点 | 正确配置 |
|---|---|
| Load Diffusion Model | 加载 hidream_e1_1_bf16.safetensors |
| QuadrupleCLIPLoader | 四个文本编码器均需匹配对应 .safetensors 文件 |
| Load VAE | 使用 ae.safetensors |
| Load Image | 导入你的原始图像 |
| Empty Text Encoder (Positive) | 输入编辑指令,如:“给这个人加上墨镜” |
| Empty Text Encoder (Negative) | 输入排除内容,如:“不要模糊、变形” |
🔍 显存占用参考(实测)
| 设备 | 精度模式 | VRAM 占用 | 首次耗时 | 第二次耗时(含缓存) |
|---|---|---|---|---|
| A100 40GB | FP16 完整版 | ~95% | 211s | 73s |
| RTX 4090D 24GB | FP16 完整版 | ❌ OOM | 不可用 | —— |
| RTX 4090D 24GB | FP8_e4m3fn_fast | ~98% | 120s | 91s |
💡 建议:对于 24GB 显存设备,务必使用 FP8 量化版本以避免显存溢出,或者可以使用第三方的FP8优化版和GGUF版本模型来降低显存需求。
如果你的显存不足,也可使用第三方云平台来体验这款模型:
HiDream-E1 工作流说明(旧版)
⚠️ 适用于仅需 768×768 固定分辨率场景,不推荐新项目使用。
1. 工作流文件及模型下载
- 从工作流模板中点击加载工作流,工作流文件中已包含模型下载信息,加载后会提示下载对应模型。
- 如果使用 E1 模型,下载 hidream_e1_full_bf16.safetensors 文件。
2. 工作流运行步骤
- 确保
Load Diffusion Model节点加载了 hidream_e1_full_bf16.safetensors 模型。 - 确保
QuadrupleCLIPLoader中四个对应的 text encoder 被正确加载。 - 确保
Load VAE节点中使用的是 ae.safetensors 文件。 - 在
Load Image节点中加载输入图片。 - 在
Empty Text Encoder(Positive)节点中输入想要对图片进行的修改。 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行图片生成。
3. 工作流补充说明
- 可能需要修改多次提示词或者进行多次生成才能得到较好的结果。
- 这个模型在改变图片风格上比较难保持一致性,需要尽可能完善提示词。
- 由于模型支持的是 768x768 的分辨率,在实际测试中调整过其它尺寸,在其它尺寸下图像表现能力不佳,甚至差异较大。
特性限制
- 仅支持固定分辨率输入(768×768),非标准尺寸需手动裁剪或填充;
- 在其他分辨率下表现不稳定,可能出现结构错乱或语义偏差;
- 编辑风格一致性较弱,需精细撰写提示词。
性能参考(Google Colab L4,22.5GB VRAM)
- 采样步数:28
- 首次运行:约 500 秒
- 第二次运行(含缓存):约 370 秒
总结与建议
| 维度 | 推荐方案 |
|---|---|
| 新项目启动 | ✅ 优先选用 HiDream-E1.1 |
| 显存 ≥32GB | 可尝试 BF16 完整精度 |
| 显存 ≤24GB | 必须使用 FP8 量化模式 |
| 编辑复杂度高 | 建议多次微调提示词+分步编辑 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











