ComfyUI-Gemini_Flash_2.0_Exp 是一个ComfyUI 自定义节点,集成了谷歌的 Gemini Flash 2.0 实验模型。它支持在 ComfyUI 工作流中直接进行文本、图像、视频帧和音频的多模态分析,并且现在新增了强大的图像生成功能!(相关:谷歌Gemini 2.0 Flash重磅升级:原生多模态生成,图像编辑进入对话时代)
功能亮点
多模态输入支持
文本分析:对文本内容进行深度分析,提取关键信息。 图像分析:分析图像内容,识别其中的物体和场景。 视频帧分析:从视频中提取关键帧并进行分析。 音频分析:分析音频内容,识别语音和声音。
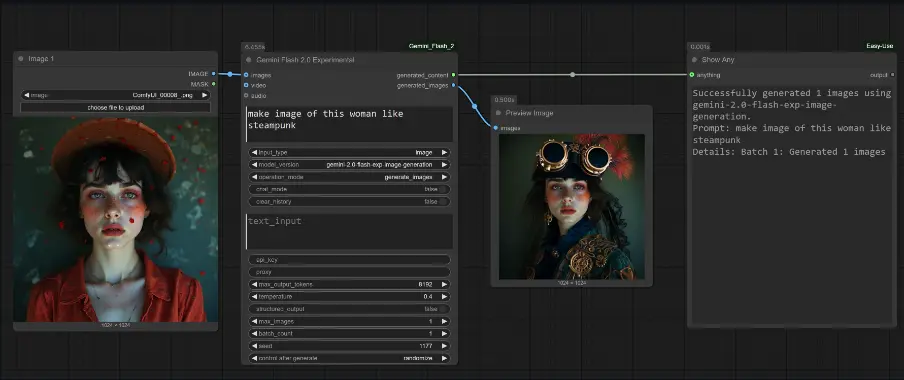
图像生成功能
使用最新的 gemini-2.0-flash-exp-image-generation 模型,根据文本描述或参考图像生成高质量图像。 支持批量生成图像,通过 batch_count 参数控制生成数量。
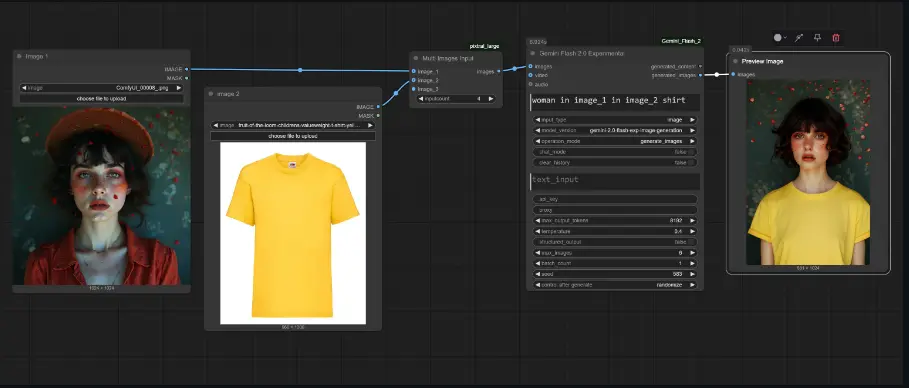
聊天模式
带有对话历史的聊天模式,提供更互动的体验。 支持语音聊天,通过智能音频录制节点实现。
可配置选项
温度和令牌限制控制:调整生成内容的随机性和长度。 代理支持:通过代理服务器进行请求,确保网络稳定。 API 设置:通过 config.json 文件配置 API 密钥和其他参数。
如何获取 API 密钥
访问 Google AI Studio 使用您的 Google 账户登录。 点击“获取 API 密钥”或进入设置。 创建新的 API 密钥。 复制 API 密钥并将其粘贴到 config.json 文件中。
config.json 文件会在首次运行时自动创建。您可以在节点主文件夹中找到并编辑它。
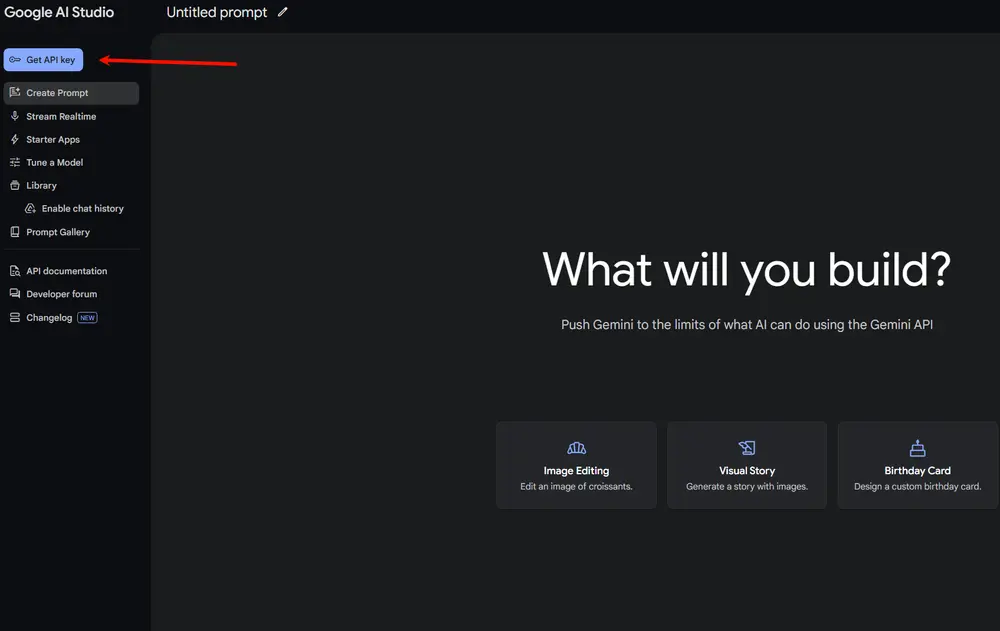
配置指南
API 密钥设置
在节点主文件夹中创建 config.json 文件,格式如下:
{
"GEMINI_API_KEY": "your_api_key_here"
}
节点输入
prompt:主要文本提示,用于分析或生成。 input_type:输入类型,可选值为 ["text", "image", "video", "audio"]。 model_version:选择模型版本,包括新的图像生成模型。 operation_mode:操作模式,可选值为 "analysis" 或 "generate_images"。 chat_mode:布尔值,启用或禁用聊天功能。 clear_history:布尔值,重置聊天历史。
text_input:附加文本输入,用于上下文。 images:多图像输入(IMAGE 类型,list=True)。 video:视频帧序列输入(IMAGE 类型)。 audio:音频输入(AUDIO 类型)。 max_output_tokens:设置最大输出长度(1-8192)。 temperature:控制响应的随机性(0.0-1.0)。 structured_output:启用结构化响应格式。 max_images:处理的最大图像数量(1-16)。 batch_count:生成的图像数量(用于图像生成模式)。 seed:用于可重复图像生成的随机种子。
聊天模式技巧
启用聊天模式:设置 chat_mode: true。聊天历史格式:聊天历史会在调用之间持续存在,直到被清除。 开始新对话:设置 clear_history: true。跨多次交互保持上下文:聊天模式适用于所有输入类型(文本、图像、视频、音频)。 切换话题时清除历史:在切换话题时建议清除历史。
视频帧处理
自动均匀采样:自动从视频中均匀采样帧。 调整帧大小:调整帧大小以提高处理效率。 支持聊天和非聊天模式:视频帧处理支持聊天和非聊天模式。
图像生成功能技巧
使用 "gemini-2.0-flash-exp-image-generation" 模型:为获得最佳效果,使用该模型进行图像生成。 提供清晰、详细的提示:详细描述您想要的图像内容。 连接参考图像:通过参考图像指导生成图像的风格。 使用种子参数:通过种子参数获得可重复的图像生成结果。
错误处理
该节点为常见问题提供清晰的错误信息,包括:
无效的 API 密钥 超出速率限制 无效的输入格式 网络/代理问题
速率限制
默认速率限制(来自 config.json):
每分钟 10 个请求(RPM_LIMIT) 每分钟 400 万令牌(TPM_LIMIT) 每天 1500 个请求(RPD_LIMIT)
音频分析与智能录制
该包包含两个用于音频处理的节点:
音频录制节点:带静音检测的智能音频录制。 Gemini Flash 节点:音频内容分析。
音频录制节点功能
实时麦克风录制:自动检测静音并智能终止录制。 可配置的静音阈值和持续时间:根据需要调整静音检测参数。 可视化录制状态指示器:录制期间提供视觉反馈。 无缝集成:与 Gemini Flash 分析无缝集成。
音频录制设置
输入设备选择:通过 device参数选择输入设备(麦克风)。音频质量设置:通过 sample_rate参数设置音频质量(默认:44100 Hz)。静音检测参数:通过 silence_threshold和silence_duration参数调整静音检测灵敏度和持续时间。
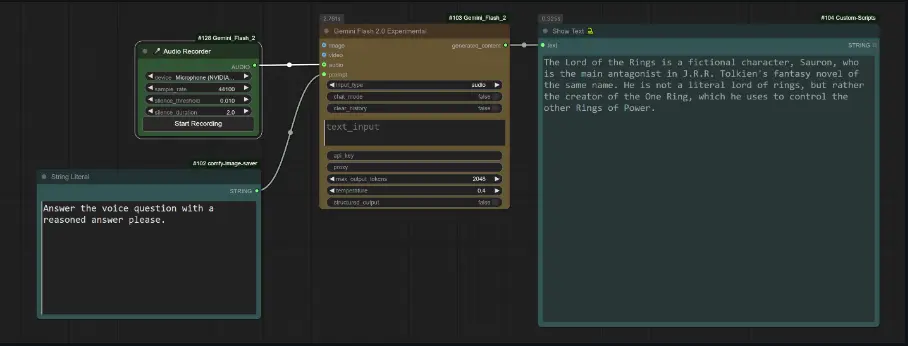
使用语音命令/音频分析
将音频录制节点添加到您的工作流中。 将其连接到 Gemini Flash 节点。 配置录制设置: 选择输入设备。 调整静音检测参数。 根据需要设置采样率。
点击“开始录制”按钮开始录制。 说出您的消息。 检测到静音后自动停止录制。 录制的音频将被处理并发送到 Gemini 进行分析。 录制按钮在 10 秒后重置,准备下一次录制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...