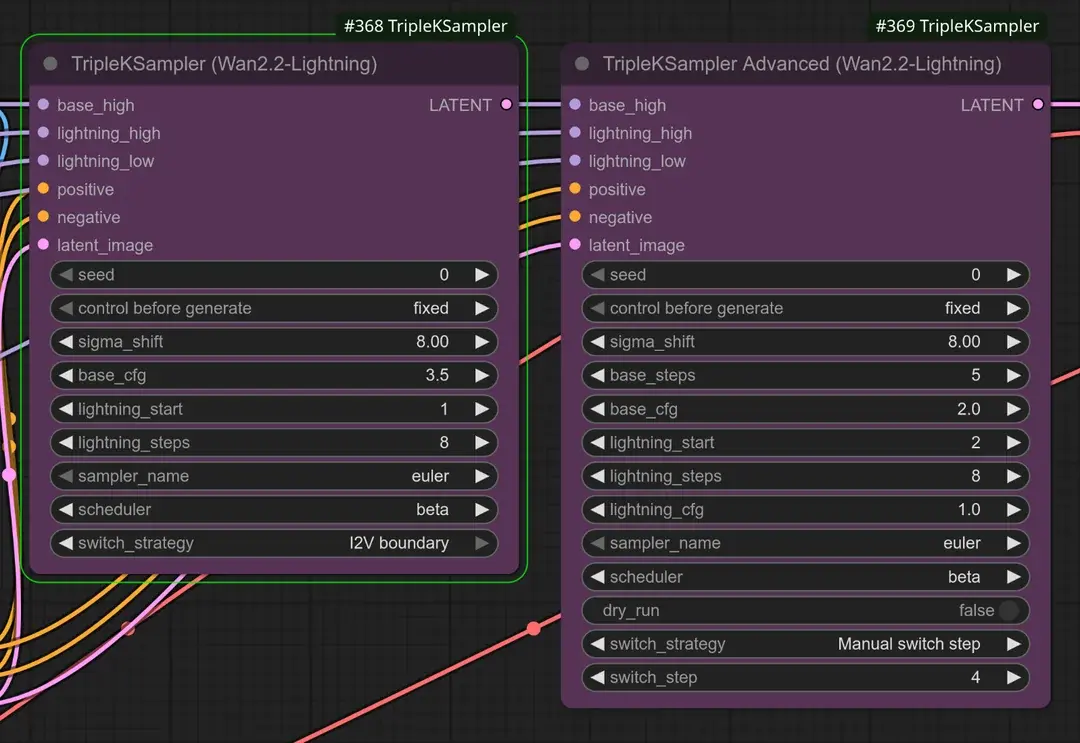
ComfyUI-CSM-Nodes为ComfyUI实现的自定义节点,集成了CSM模型,用于文本到语音的生成。CSM模型为Sesame 团队推出新一代语音模型,目前仅支持英文。(相关:Sesame 团队推出新一代语音技术 CSM:让语音助手更像真人)
功能
ComfyUI-CSM-Nodes提供了以下三个核心节点,用于实现文本到语音的生成:
- 节点 Load CSM Checkpoint
- 功能:从
ComfyUI/models/sesame/目录加载CSM模型 - 用途:加载预训练的CSM模型权重,为后续的语音生成任务做准备
- 功能:从
- 节点 Load CSM Tokenizer
- 功能:从
ComfyUI/models/sesame_tokenizer/目录加载分词器 - 用途:加载分词器文件,用于将文本输入转换为模型可处理的格式
- 功能:从
- 节点 CSM Text-to-Speech
- 功能:使用CSM-1B模型将文本输入转换为音频输出
- 用途:将用户提供的文本内容生成高质量的语音文件,支持实时语音合成
系统要求
在使用ComfyUI-CSM-Nodes之前,请确保满足以下条件:
- 已安装的ComfyUI:确保你已经安装并运行了ComfyUI框架。
- Python版本:需要Python 3.10或更高版本。
- 硬件要求:推荐使用支持CUDA的GPU,以加速模型推理过程。
- 注意:虽然GPU不是必须的,但使用CPU运行可能会显著降低推理速度。
- 模型权重文件:需要从
sesame/csm-1b获取模型权重文件(ckpt.pt),并将其放置在ComfyUI/models/sesame/目录下。 - 分词器文件:需要分词器文件(例如,来自Llama-3.2-1B的分词器),并将其放置在
ComfyUI/models/sesame_tokenizer/<tokenizer_dir>/目录下。 - 依赖项:安装
requirements.txt中列出的依赖项。- 注意:
requirements.txt中列出的依赖项版本是固定的,可能会与ComfyUI中其他插件的依赖项冲突。请仔细检查并解决潜在的冲突。
- 注意:
注意事项
- 依赖项冲突:
requirements.txt中列出的限定了依赖项版本,可能会与ComfyUI中其他插件的依赖项冲突。如果遇到冲突。 - 性能优化:推荐使用支持CUDA的GPU来加速模型推理过程。如果使用CPU运行,可能会导致推理速度较慢。
- 模型支持语言:目前CSM模型仅支持英文,不支持其他语言。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











