
来自西安交通大学的研究团队推出Compress3D,它是一种从单张图片生成三维模型的方法。想象一下,你有一张你最喜欢的动漫角色的图片,你想在虚拟现实游戏中使用这个角色的三维模型。传统上,这需要3D艺术家花费大量时间和努力来手工创建。但是,Compress3D能够通过分析这张图片,自动创建出一个高质量的三维模型。
主要功能和特点:
- 高质量生成: Compress3D能够从单张图片中生成具有丰富纹理和精细几何细节的三维模型。
- 快速生成: 它能够在短短7秒内,仅使用一块A100 GPU就生成一个高质量的3D资产。
- 压缩潜空间: 该技术通过一个称为三平面自编码器的结构,将3D模型压缩到一个紧凑的潜在空间中,有效压缩了3D几何和纹理信息。
- 双阶段生成: 它首先生成形状嵌入,然后基于这个形状嵌入和图像嵌入生成三维模型,这样提高了生成模型的准确性和质量。
工作原理:
- 三平面自编码器: 这是Compress3D的核心,它包括一个编码器和一个解码器。编码器将彩色点云(3D模型的一种表示形式)压缩成一个低维的潜在空间。解码器则从这个潜在空间重构出彩色的3D模型。
- 3D感知交叉注意力机制: 为了增强潜在空间的表现能力,Compress3D使用了一个特殊的注意力机制,它利用低分辨率的潜在表示来查询高分辨率3D特征体积中的特征。
- 扩散模型: 在压缩的潜在空间上训练一个扩散模型,这个模型可以生成高质量的3D内容。
- 形状嵌入和图像嵌入: 通过结合图像嵌入和形状嵌入作为条件,Compress3D能够更准确地生成3D模型。形状嵌入是通过一个扩散先验模型估计得到的,该模型基于图像嵌入生成。
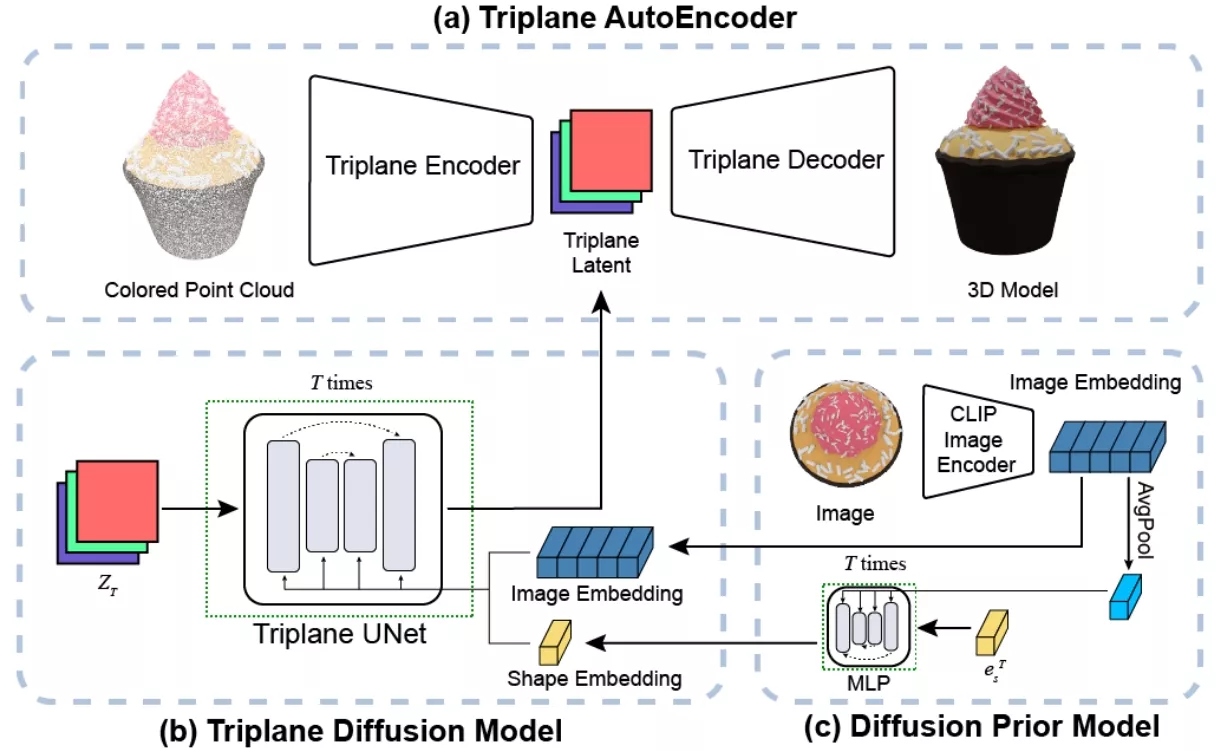
Compress3D是一个强大的工具,它通过先进的机器学习技术,使得从二维图像到三维模型的转换变得快速、高效且高质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











