零一万物团队隆重推出Presto——一款专为生成长达15秒的高质量视频而设计的新型扩散模型。Presto旨在克服长时间视频生成中保持场景多样性和一致性的挑战,通过引入分段交叉注意力(Segmented Cross-Attention, SCA)策略和利用LongTake-HD数据集,实现了内容丰富、长时间连贯且动态程度极高的视频生成。

分段交叉注意力(SCA)策略
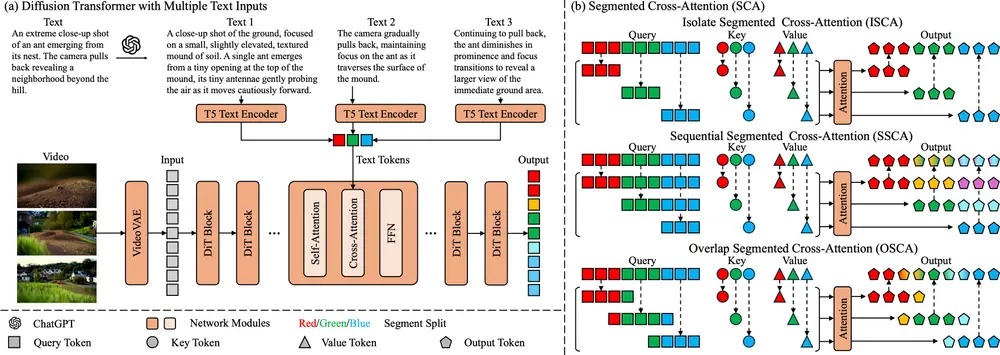
在传统视频生成模型中,维持长时间视频的一致性和多样性是一个棘手的问题。为了应对这一挑战,Presto创新性地采用了SCA策略。该策略将隐藏状态按时间维度分割成多个片段,使得每个片段能够专注于对应的子标题,从而确保了视频内容在不同时间段内的连贯性和相关性。重要的是,SCA并不需要额外增加模型参数,因此可以轻松集成到现有的基于DiT(Diffusion in Time)架构中,提高了模型的灵活性和效率。
LongTake-HD 数据集
为了支持长视频生成的研究,并提供一个可靠的基准,我们构建了LongTake-HD数据集。这个数据集包含了26.1万个高质量的视频片段,每个片段不仅具备场景一致性,还配有总体视频标题和五个渐进的子标题。这些标注信息为训练模型提供了丰富的语义指导,有助于生成更加复杂和细致的视频内容。LongTake-HD数据集的发布,填补了长视频生成领域高质量数据资源的空白,促进了该领域的进一步发展。
主要功能和特点
- 分段交叉注意力(SCA):这是一种新颖的注意力机制,它将隐藏状态沿时间维度分割成多个部分,每个部分与其对应的子标题进行交叉注意力计算,从而提高视频内容的丰富性和长期连贯性。
- LongTake-HD数据集:Presto构建了一个包含261k个内容丰富、场景连贯的视频的数据集,这些视频配有总体视频标题和五个逐步子标题,为生成高质量长视频提供了基础。
- 内容丰富性和长期连贯性:Presto在VBench语义分数上达到了78.5%,在动态度量上达到了100%,超越了现有的最先进视频生成方法,显示出其在内容丰富性和长期连贯性方面的优势。
工作原理
Presto的工作原理基于以下几个关键步骤:
- 文本输入处理:Presto使用T5文本编码器处理输入的文本提示,并将其分解为多个逐步子标题。
- 视频数据编码:使用预训练的自编码器将原始视频数据从像素空间压缩到潜在空间。
- 扩散过程:在训练期间,扩散变换器(DiT)接收带有噪声的视觉输入,并执行去噪过程。在推理期间,从高斯噪声开始,迭代应用扩散过程,逐步精细化输出。
- 分段交叉注意力(SCA):将潜在特征沿时间维度分割,并使每个部分与其对应的子标题进行交叉注意力计算,以生成与子标题相匹配的视频片段。
- 后处理:采用EMA-VFI作为帧插值模型,进一步规范化视频速度并扩展视频长度。
实验结果与性能优势
通过对Presto进行广泛的实验评估,我们发现它在VBench语义评分上达到了78.5%,并且在动态程度指标上达到了满分100%。这意味着Presto不仅能够在长时间内保持视频内容的一致性和多样性,还能精准捕捉复杂的文本细节,生成视觉效果出色的视频。与现有的最先进方法相比,Presto显著提升了视频的内容丰富度和动态表现力,成为长视频生成领域的新标杆。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











