
ParaAttention是一种创新的上下文并行注意力机制,旨在通过多个GPU加速FLUX和Mochi模型的推理。通过支持torch.compile和多种并行策略,ParaAttention提供了高效的模型加速解决方案。以下是ParaAttention的主要特点和目标:
主要特点
1、上下文并行注意
Ulysses风格并行:支持Ulysses风格的并行策略,通过将上下文分割成多个块并在多个GPU上并行处理,提高推理速度。 Ring风格并行:支持Ring风格的并行策略,通过环形通信模式在多个GPU之间传递信息,实现高效的并行计算。
2、支持torch.compile
编译优化:ParaAttention完全支持 torch.compile,通过编译优化进一步提升模型的推理性能。
3、易于使用的接口
统一接口:提供一个统一的接口来运行上下文并行注意力,使得用户可以轻松地在不同的并行策略之间切换,同时保持最大性能。
4、高性能实现
Triton实现:ParaAttention在Triton中实现了最快的且准确的注意力机制,特别是在RTX 4090上,比原始的FA2实现快50%。
目标
1、提升推理速度
大幅加速:通过上下文并行和 torch.compile优化,ParaAttention显著提升了FLUX和Mochi模型的推理速度,且无损。
2、保持模型性能
无损加速:在加速推理的同时,确保模型的性能和准确性不受影响。
3、统一接口
灵活使用:提供一个统一的接口,使得用户可以轻松地在不同的并行策略和优化技术之间切换,保持最大的灵活性和性能。
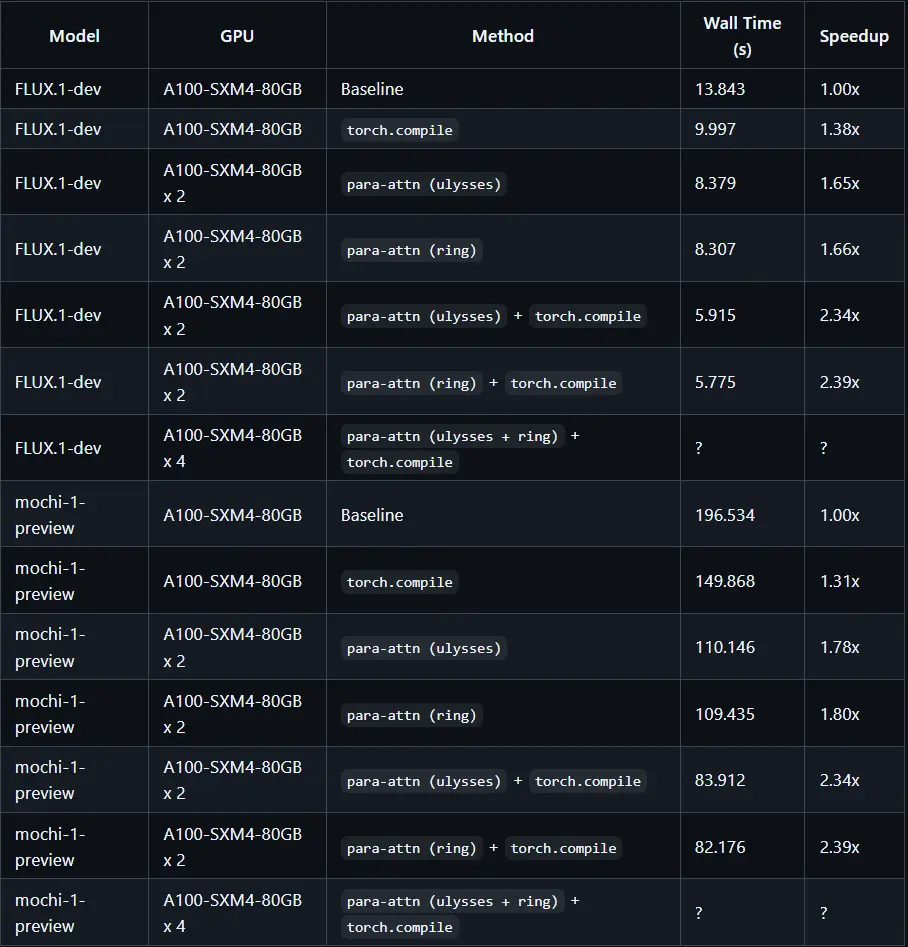
性能和效果
ParaAttention在多个基准测试中表现出色,以下是其主要性能指标:
速度提升:在RTX 4090上,ParaAttention比原始的FA2实现快50%,显著提升了模型的推理速度。 精度保持:在加速推理的同时,ParaAttention保持了模型的精度和性能,确保无损加速。 灵活性:支持多种并行策略和优化技术,使得用户可以根据具体需求选择最适合的配置。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











