
清华深圳国际研究生院、北京航空航天大学软件学院、中国人民大学财政金融学院和清华大学自动化系的研究人员推出无训练(training-free)框架Personalize Anything,能够在不进行任何训练或微调的情况下,实现高质量的个性化图像生成。该框架基于DiT架构模型(如Flux模型),通过简单的标记替换和时间步自适应的标记替换策略,实现了从单主体个性化到多主体组合、布局引导生成、视觉叙事等多种应用场景的高效个性化图像生成。
- 项目主页:https://fenghora.github.io/Personalize-Anything-Page
- GitHub:https://github.com/fenghora/personalize-anything
例如,用户希望生成一张包含特定宠物狗的图像,描述为“一只狗在海滩上玩耍”。使用“Personalize Anything”框架,用户只需提供一张该宠物狗的参考图像,框架会自动将参考图像中的狗的特征注入到生成过程中,生成一张与描述相符且包含该特定狗的图像,而无需对模型进行任何训练或微调。
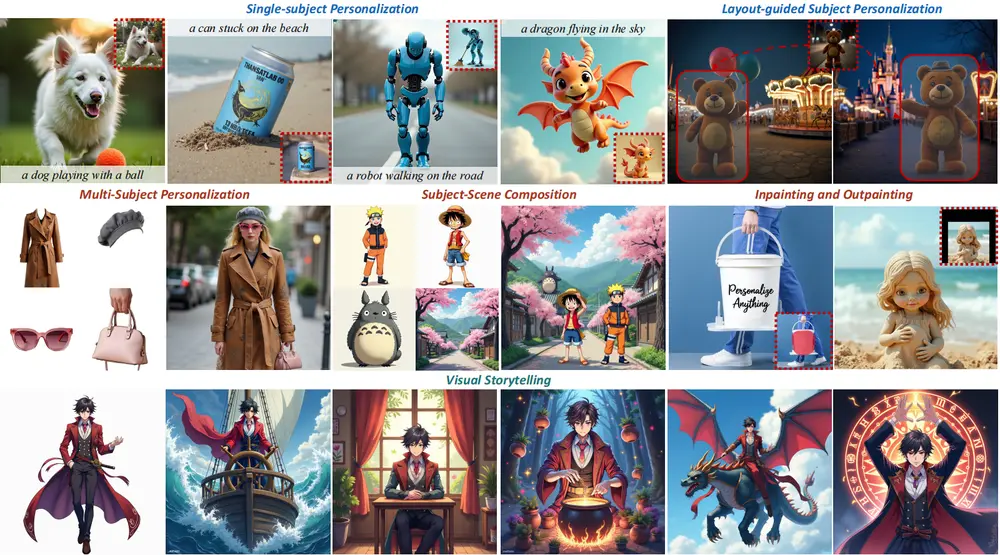
主要功能
- 单主体个性化:生成用户指定概念的高质量图像,同时保持灵活的编辑能力。
- 多主体个性化:支持在同一场景中生成多个不同主体的图像,每个主体都保持其独特的特征。
- 主体-场景组合:将特定主体与特定场景组合,生成自然协调的图像。
- 布局引导生成:通过指定布局,控制主体在图像中的位置。
- 图像修复与扩展:支持基于用户指定掩码的图像修复(inpainting)和扩展(outpainting)。
- 视觉叙事:生成与故事情节相关的连贯图像序列。
主要特点
- 无训练框架:无需对模型进行任何训练或微调,大大提高了计算效率。
- 高保真度:通过简单的标记替换实现高保真度的主体重建,保持主体的一致性和细节。
- 时间步自适应:在去噪过程的早期阶段注入参考主体标记以强制主体一致性,在后期阶段通过多模态注意力增强灵活性。
- 结构多样性:通过局部标记扰动和掩码增强,引入更多的全局外观信息,增强结构和纹理多样性。
- 广泛的适用性:支持多种应用场景,包括单主体、多主体、主体-场景组合、布局引导生成等。
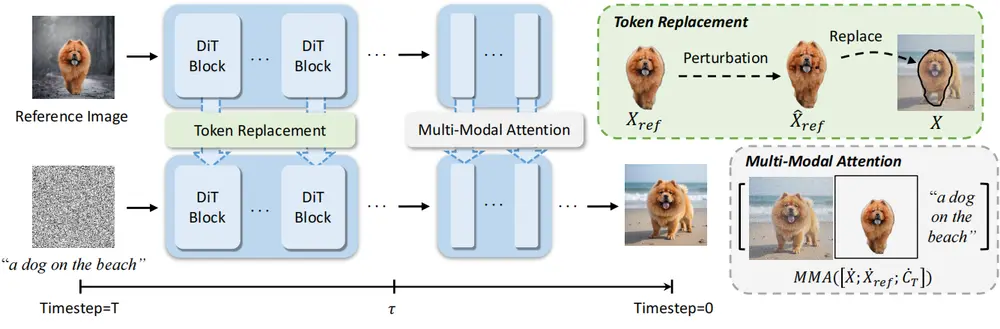
工作原理
- 标记替换:通过将去噪标记替换为参考主体的标记,实现高保真度的主体重建。这种方法利用了扩散变换器(DiT)的位置解耦表示,避免了位置信息的干扰。
- 时间步自适应标记替换:
- 早期阶段:在去噪过程的早期阶段,通过标记替换强制主体一致性。
- 后期阶段:在去噪过程的后期阶段,通过多模态注意力将参考主体标记与文本提示融合,增强灵活性。
- 局部标记扰动:通过局部标记扰动和掩码增强,引入更多的全局外观信息,增强结构和纹理多样性。
- 扩展应用:通过几何编程,支持布局引导生成、多主体组合和图像编辑等复杂场景。
应用场景
- 广告制作:生成包含特定品牌标志或产品的高质量图像,用于广告宣传。
- 视觉叙事:生成与故事情节相关的连贯图像序列,用于电影、游戏或漫画制作。
- 图像修复与编辑:对图像进行修复或扩展,填补缺失部分或扩展图像边界。
- 多主体组合:在同一场景中生成多个不同主体的图像,用于艺术创作或虚拟场景设计。
- 布局引导生成:通过指定布局,控制主体在图像中的位置,用于设计和规划。
- 视频和3D生成:扩展到视频和3D生成领域,通过空间操作实现可控的合成。
总结
“Personalize Anything”框架通过简单的标记替换和时间步自适应策略,实现了高效、高质量的个性化图像生成。该框架无需训练或微调,具有广泛的适用性和强大的灵活性,为个性化图像生成领域提供了一种新的高效解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











