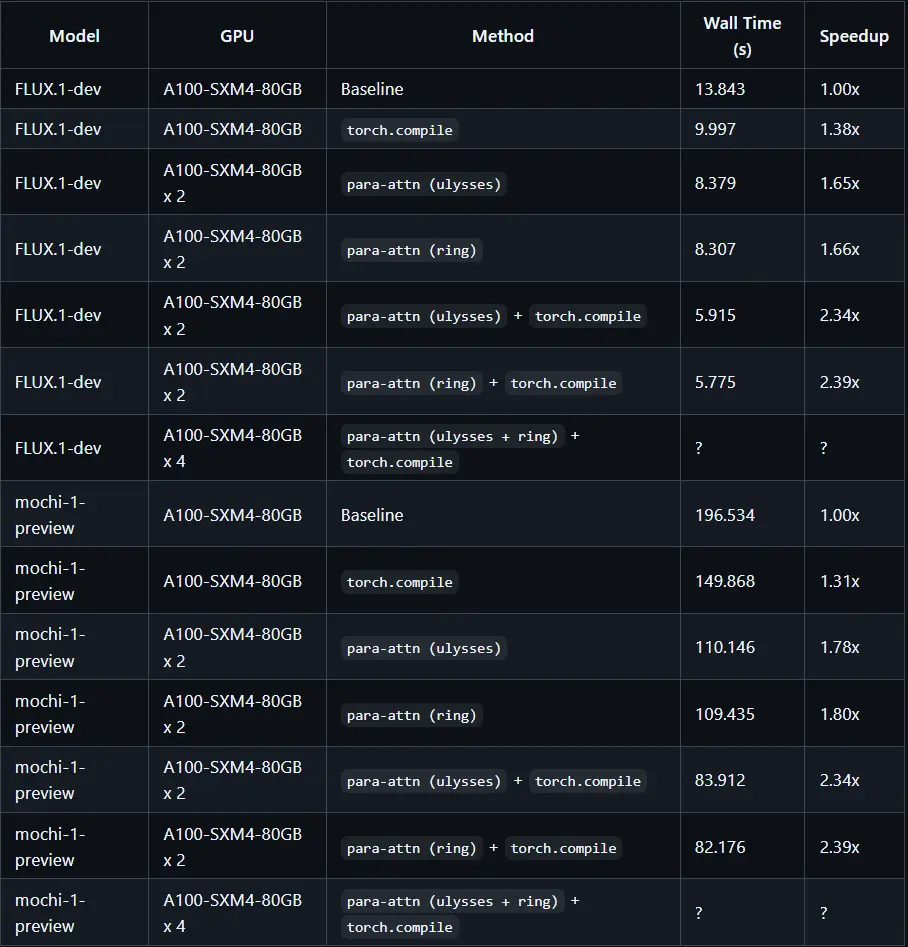
ParaAttention:通过上下文并行注意力机制,使用多个GPU加速FLUX和Mochi模型的推理ParaAttention是一种创新的上下文并行注意力机制,旨在通过多个GPU加速FLUX和Mochi模型的推理。通过支持torch.compile和多种并行策略,ParaAttention提供了高效...新技术# ParaAttention# 推理加速1年前04120