
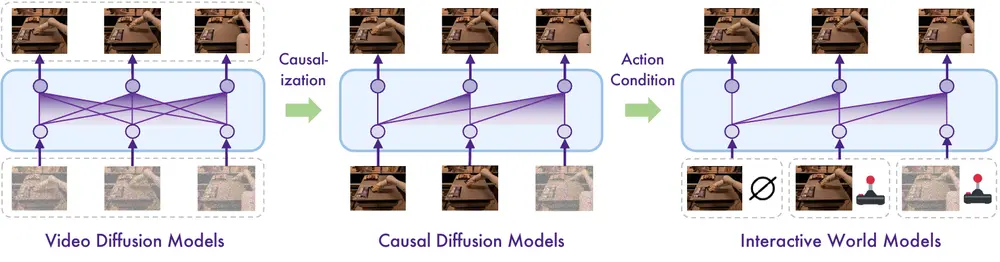
对象插入和主体驱动生成是计算机视觉中的两个重要任务,旨在将给定的对象合成到由图像或文本指定的场景中。具体来说:
- 对象插入:将一个对象无缝地插入到目标场景中,要求合成后的图像在姿态、光照等方面看起来逼真,同时保留对象的身份。
- 主体驱动生成:生成新的对象图像,保持其身份不变,同时改变其姿态、光照等属性。
现有方法在这两个任务上面临的主要挑战包括:
- 逼真合成:确保合成后的对象与场景在光照、阴影、纹理等方面完全一致。
- 身份保留:在合成过程中保持对象的独特特征,避免失真或变形。
- 数据需求:实现这些目标通常需要大规模的监督数据,但手动收集和标注这样的数据成本过高。
ObjectMate 的创新点
谷歌和耶路撒冷希伯来大学的研究人员提出了一种名为 ObjectMate 的新方法,能够在无需微调的情况下,有效地解决上述挑战。该方法的关键在于利用 对象重复先验,即许多批量生产的对象在大型未标注数据集中多次出现,具有不同的姿态、光照和场景条件。通过检索同一对象的多样化视图集,研究人员创建了一个大规模的配对数据集,从而实现了强大的监督信号。
例如,我们有一张椅子的多个视角的照片,以及一个描述目标场景的文本提示,如“一个椅子在客厅里”。ObjectMate能够将椅子的照片合成到一个客厅的场景中,同时确保椅子的姿态、光照与场景协调,且椅子的细节特征得以保留。

主体驱动生成
在主体驱动生成任务中,ObjectMate 利用对象重复先验训练模型,生成新的对象图像,同时准确保留其身份。具体来说,模型通过学习不同姿态和光照条件下的对象表示,能够在测试时生成高质量的对象图像,而无需进行额外的微调。这种方法不仅提高了生成图像的质量,还显著简化了模型的部署过程。
对象插入
对于对象插入任务,研究人员提出了 ObjectDrop,一种从目标图像中移除对象的技术。通过使用 ObjectDrop,他们将对象重复数据集适应于对象插入任务。然后,他们在该数据集上训练 ObjectMate,使其能够根据背景图像和对象参考视图条件化生成。ObjectMate 在合成过程中实现了光照和姿态的逼真协调,同时保留了对象的身份。这使得生成的图像在视觉上更加自然,减少了人工痕迹。
方法论
为了构建包含对象在各种姿态和场景中多个视图的大规模数据集,研究人员采用了以下步骤:
- 数据收集:从包含 4500 万张图像的广泛未标注互联网数据集开始。
- 对象检测与特征提取:使用对象检测算法识别图像中的对象,并计算每个对象的实例检索特征。这些特征被存储在一个数据库中。
- kNN 搜索:通过 kNN 搜索,识别出具有高相似度的对象簇。此过程生成了一个包含 450 万个对象的数据集,每个对象至少关联三个高质量视图。
- 配对数据集构建:利用这些对象簇,构建了一个大规模的配对数据集,用于对象插入和主体生成任务。
大规模配对数据集的作用
拥有大规模配对数据集使得对象插入和主体生成任务变得简单。为了在多个参考图像上条件化生成,研究人员训练了一个模型,该模型接受一个 2×2 的图像网格。该网格包括:
- 三个参考图像:展示对象在不同姿态和光照条件下的视图。
- 一个噪声目标图像:占据网格的左上角,作为生成的起点。
自注意力层在参考图像和噪声目标图像之间传递信息,确保生成的图像在姿态、光照等方面与参考图像一致,同时保留对象的身份。
实验结果
实验表明,ObjectMate 在身份保留和逼真合成方面表现优异,显著优于现有的多参考方法。此外,与其他方法不同,ObjectMate 无需在测试时进行缓慢的微调,大大提高了生成效率和实用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











