
苹果提出了新的文生图模型架构DiT-Air和DiT-Air-Lite,旨在提高模型的参数效率和生成性能。其论文主要研究了扩散模型(Diffusion Models)在文本到图像生成任务中的架构设计、文本条件策略和训练协议。

研究方法
这篇论文提出了通过优化DiT架构来提高文本到图像生成的参数效率。具体来说,
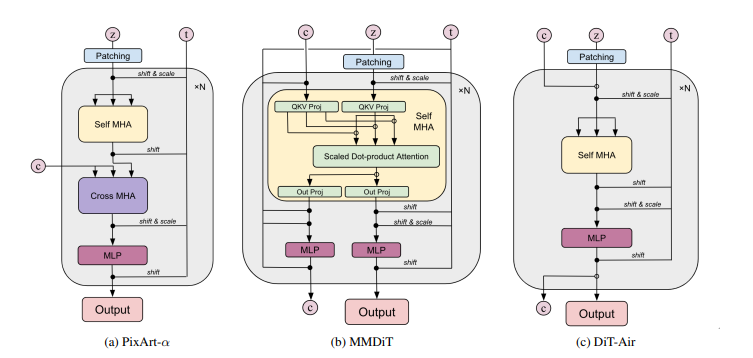
- DiT-Air架构: 文章提出了一种名为DiT-Air的紧凑型DiT架构,采用层级的参数共享策略,减少了模型大小。DiT-Air通过直接处理拼接的文本和噪声输入,消除了模态特定的投影,从而节省了大量参数。
- 参数共享策略: 文章借鉴了NLP模型中的参数共享策略,采用了全块共享和注意力共享方案,以进一步提高参数效率。注意力共享提供了在文本对齐和生成保真度之间的良好权衡。
- 文本编码器和VAE: 文章详细分析了三种主要的文本编码器(CLIP、大型语言模型和T5模型),并引入了一个改进的VAE,以更好地保留视觉细节。
实验设计
- 数据集: 文章使用了一个包含15亿文本-图像对的自有数据集,并通过预训练的生成模型丰富了数据集。为了平衡真实和合成数据,采用了1:9的比例。
- 训练和推理: 所有模型使用相同的变分自编码器(VAE)和CLIP-H模型作为默认文本编码器。模型使用流匹配目标进行训练,优化采用AdaFactor,学习率为1e-4,批量大小为4096,训练步数为100万步。推理时采用Heun SDE求解器,采样步数为50,分类器自由指导比例为7.5。
- 模型扩展: 模型在五个规格上进行扩展:S、B、L、XL和XXL,分别对应12、18、24、30和38个Transformer层。
结果与分析
- 验证损失和扩展行为: DiT-Air在验证损失和基准性能方面表现最佳,显示出更高的参数效率。随着模型规模的增加,DiT-Air的验证损失下降最快,表明其在扩展时的有效性。
- 基准性能: DiT-Air在多个基准测试中表现出色,特别是在FID分数上表现较低,同时在PickScore和GenEval上与MMDiT和PixArt-α相当或更好。
- DiT-Air-Lite: DiT-Air-Lite通过更激进的参数共享进一步减少参数,但注意力共享版本在保持高文本对齐和图像质量的同时,实现了显著的参数节省。
结论
这篇论文系统地研究了DiT架构在文本到图像生成任务中的性能,提出了DiT-Air和DiT-Air-Lite模型,显著提高了参数效率。通过多阶段训练过程,最终模型在关键基准测试中达到了新的最先进水平。研究表明,通过优化扩散架构和训练实践,可以开发出更高效和更具表现力的文本到图像模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











