
生数科技发布创新框架DreamReward,它专注于通过人类偏好反馈来提升从文本到3D内容生成(text-to-3D generation)的质量。它通过结合人类反馈和先进的机器学习技术,极大地提高了文本到3D生成任务的质量和用户满意度。
想象一下,你只需给定一段描述,比如“一只穿着太空服的猫”,DreamReward就能生成一个3D模型,这个模型不仅外观逼真,而且还能根据人类的喜好进行优化。
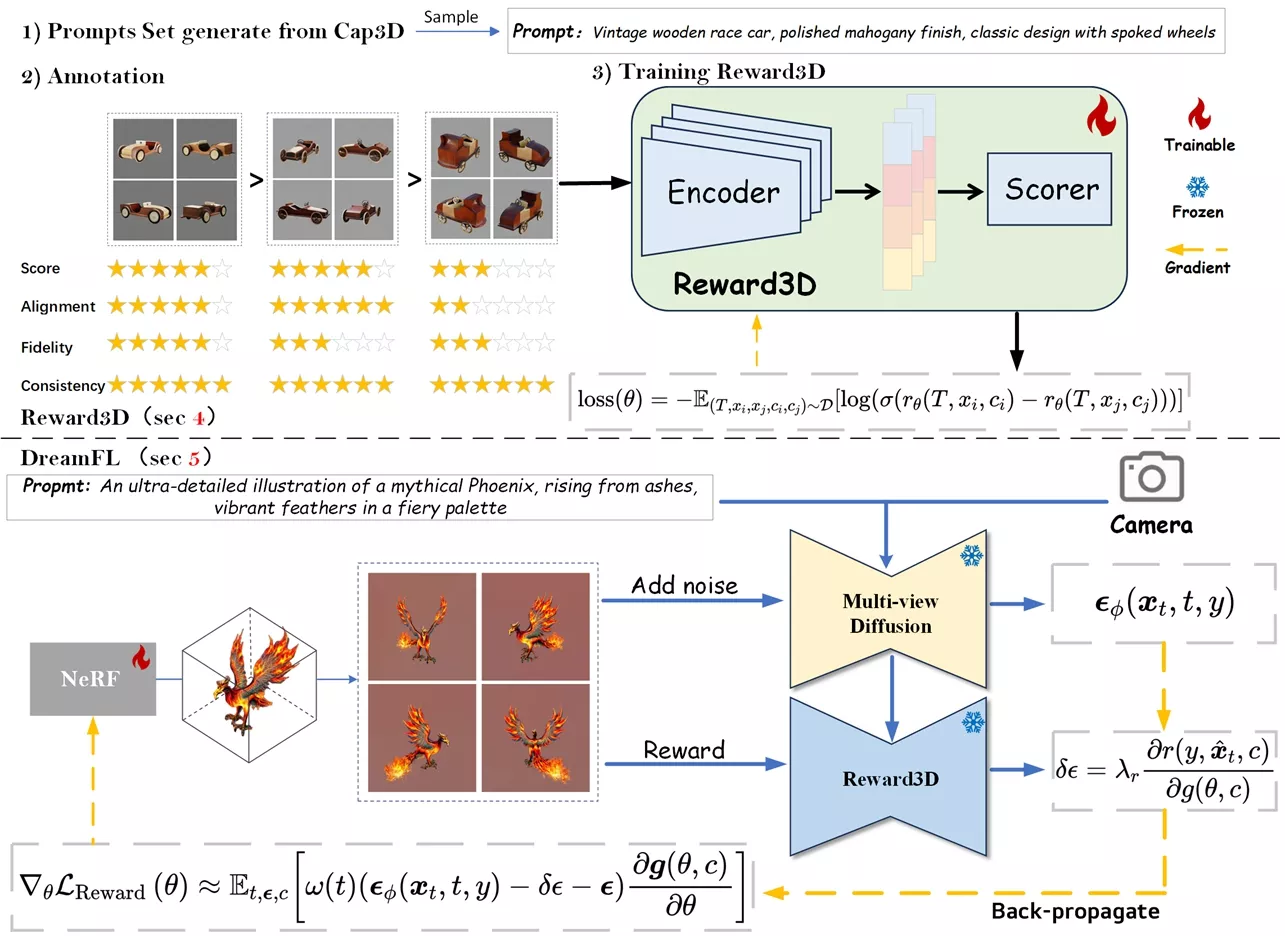
主要功能和特点:
- 人类偏好学习: DreamReward通过收集专家的比较反馈来学习人类的偏好,从而生成更符合用户期望的3D内容。
- 高保真生成: 它能够生成高质量的3D模型,这些模型在视觉上与文本描述高度一致,并且具有多视角一致性。
- 直接调优算法: 论文提出了一种名为DreamFL的直接调优算法,该算法利用重新定义的评分器来优化多视角扩散模型。
工作原理:
- 数据集构建: 首先,研究者们构建了一个包含2530个提示的3D数据集,并对这些数据进行了人类偏好的标注。
- 奖励模型训练: 基于这个数据集,他们训练了一个名为Reward3D的评分模型,该模型能够有效评估生成的3D内容的质量。
- 优化生成模型: 利用Reward3D模型,研究者们进一步提出了DreamFL算法,该算法通过调整生成模型的参数,使得生成的3D模型更符合人类的偏好。
具体应用场景:
- 电影和游戏开发: DreamReward可以用于生成电影或游戏中的3D角色和场景,提高内容的吸引力和真实感。
- 建筑设计: 建筑师可以使用这个框架来根据客户的描述生成建筑物的3D模型,提前预览设计效果。
- 虚拟现实: 在虚拟现实内容的创建中,DreamReward可以帮助开发者快速生成符合用户期望的3D环境和对象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











