
视觉概念生成工具 Piece it Together(PiT):将用户提供的部分视觉组件无缝集成到一个连贯的整体概念中,并同时生成缺失的部分,以生成一个完整且合理的概念
特拉维夫大学和Bria AI的研究人员推出一款创新的视觉概念生成工具 Piece it Together(PiT),能够将用户提供的部分视觉组件无缝集成到一个连贯的整体概念中,并同时生成缺失的部分,以生成一个完整且合理的概念。这种方法特别适用于创意设计领域,例如产品设计、角色概念化和玩具设计等。
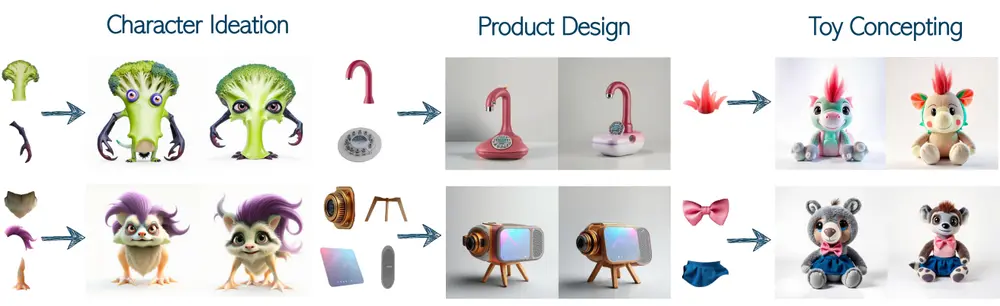
例如,你是一名设计师,正在设计一个全新的角色。你有一些灵感碎片,比如一个独特的翅膀结构或一个特定的发型,但这些只是概念的一部分。使用 Piece it Together(PiT),你可以将这些碎片输入模型,模型会自动补全缺失的部分,生成一个完整的角色设计。例如,输入一个翅膀的图片和一个发型的图片,模型可以生成一个完整的角色,包含身体、面部等其他必要的部分。
主要功能
- 部分到整体的生成:将用户提供的部分视觉组件(如物体的某个部分、草图等)整合成一个完整的概念。
- 缺失部分的补全:自动推断并生成缺失的部分,使最终生成的概念在目标领域内合理且完整。
- 语义操作:在生成的概念上进行语义编辑和操作,例如调整角色的风格、情绪等。
- 文本条件的恢复:通过 IP-LoRA 技术,恢复生成概念的文本条件控制能力,使生成的图像能够更好地适应不同的场景或风格。

主要特点
- 基于 IP+ 空间的表示:使用 IP-Adapter+ 的内部表示空间,相比 CLIP 空间,能够更好地保留视觉细节,同时支持语义操作。
- 轻量级流匹配模型:通过训练一个轻量级的流匹配模型(IP-Prior),能够基于特定领域的先验知识生成连贯的组合。
- 灵活的输入形式:支持多种输入形式,包括图像片段、草图等,为用户提供更大的灵活性。
- 多样的输出结果:对于相同的输入,模型可以生成多种合理的输出,帮助设计师探索不同的创意方向。
工作原理
- 表示空间的选择:
- 选择 IP-Adapter+ 的内部表示空间(IP+ 空间)作为模型的输入表示。该空间在保留视觉细节的同时,支持语义操作。
- 将输入的图像片段通过 IP-Adapter+ 编码为 IP+ 向量。
- IP-Prior 模型训练:
- 使用生成的数据训练 IP-Prior 模型。数据通过预训练的文本到图像模型(如 Flux-Schnell)生成,包含目标领域的多样化样本。
- IP-Prior 模型基于流匹配技术,学习如何将输入的图像片段组合成一个完整的概念,并生成缺失的部分。
- 语义操作:
- 在 IP+ 空间中,通过计算不同语义方向的向量(如“可爱”到“可怕”),对生成的概念进行语义编辑。
- 文本条件的恢复:
- 使用 LoRA(Low-Rank Adaptation)技术,通过少量样本训练一个适配器,恢复生成概念的文本条件控制能力。
应用场景
- 角色设计:
- 设计师可以输入角色的部分特征(如翅膀、眼睛等),模型生成完整的角色设计,并支持进一步的语义编辑,如调整角色的情绪或风格。
- 生成的角色可以进一步放置在不同的场景中,通过文本条件控制背景。
- 产品设计:
- 输入产品的部分设计元素(如形状、材质等),模型生成完整的产品设计,并支持风格调整。
- 生成的产品设计可以用于虚拟展示,帮助评估设计在不同环境中的效果。
- 玩具概念化:
- 输入玩具的部分特征(如动物的头部、服装等),模型生成完整的玩具设计。
- 生成的玩具设计可以用于市场调研,评估消费者对不同设计的反应。
- 创意绘画:
- 输入草图或部分绘画元素,模型生成完整的绘画作品,并支持风格调整。
- 生成的作品可以用于艺术展览或进一步的创作灵感。
通过这些功能和特点,Piece it Together 为创意设计提供了一个强大的工具,能够帮助设计师更高效地探索和实现他们的创意。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











