今天,MiniMax 正式推出全新一代大模型——MiniMax M2.5。这款模型依托在数十万个复杂真实世界环境中开展的大规模强化学习训练,实现了能力的全面升级。

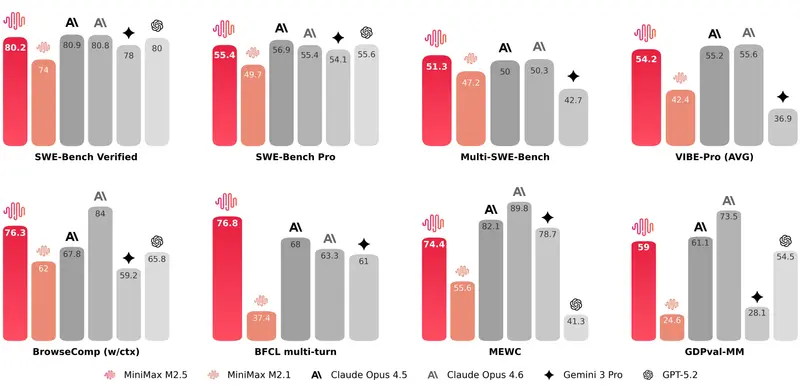
在编程开发、智能体工具使用与信息搜索、办公室日常工作,以及一系列具备实际经济价值的生产类任务中,MiniMax M2.5 均达到了当前行业 SOTA 水平。在行业公认的权威基准测试里,M2.5 分别取得了亮眼成绩:
- SWE-Bench Verified:80.2%
- Multi-SWE-Bench:51.3%
- BrowseComp(带上下文管理):76.3%
在模型设计上,MiniMax M2.5 从训练阶段就以高效推理、最优任务分解为目标,因此在执行复杂智能体任务时,能够展现出极快的响应速度与执行效率。实测数据显示,M2.5 完成 SWE-Bench Verified 评估的速度,相比上一代模型 M2.1 提升了 37%,推理耗时与 Claude Opus 4.6 基本相当。
- 使用地址:https://agent.minimaxi.com
- API:https://platform.minimaxi.com/docs/api-reference/text-anthropic-api
- CodingPlan:http://platform.minimax.io/subscribe/coding-plan
- GitHub:https://github.com/MiniMax-AI/MiniMax-M2.5
- 模型:https://huggingface.co/MiniMaxAI/MiniMax-M2.5
更值得关注的是,MiniMax M2.5 是行业内首个让用户无需担忧使用成本的前沿大模型,真正兑现了“智能廉价到无需计量”的产品理念。官方给出的成本数据十分直观:
- 以每秒 100 token 的速度连续运行模型一小时,成本仅为 1 美元
- 以每秒 50 token 的速度运行时,一小时成本更是低至 0.30 美元
MiniMax 方面表示,希望 M2.5 所具备的极致速度与超高成本效益,能够催生出更多面向真实场景的创新智能体应用,让 AI 更深度地融入各行各业的生产流程。
编程能力:具备架构师级规划,覆盖全栈开发全生命周期
在编程相关的各项评估中,MiniMax M2.5 相比前代模型实现了质的飞跃,整体表现达到 SOTA 水准,尤其在多语言编码任务上展现出突出优势。
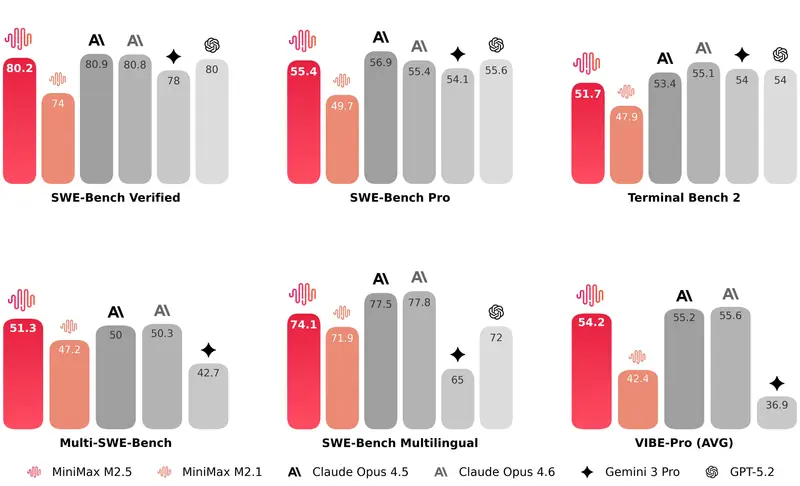
M2.5 相比前代最核心的提升之一,是拥有了像软件架构师一样思考和规划的能力。这一能力在模型训练过程中自然涌现:在正式编写任何一行代码之前,M2.5 就会站在经验丰富的软件架构师视角,主动对项目进行拆解,规划项目功能、整体结构以及 UI 设计方案,而不是直接进入代码编写环节。
为了让模型适配真实工程场景,MiniMax 让 M2.5 在超过 20 万个真实开发环境中完成训练,覆盖的编程语言多达 10 余种,包括:
Go、C、C++、TypeScript、Rust、Kotlin、Python、Java、JavaScript、PHP、Lua、Dart、Ruby 等。
M2.5 能做的远不止简单的代码错误修复,而是可以覆盖一整套复杂系统的完整开发生命周期:
- 从 0 到 1:完成系统设计与开发环境搭建
- 从 1 到 10:开展核心业务系统开发
- 从 10 到 90:持续进行功能迭代与优化
- 从 90 到 100:完成全面代码审查与系统测试
在平台覆盖上,M2.5 支持 Web、Android、iOS、Windows 等多个平台的全栈项目开发,能够完成服务器端 API 开发、业务逻辑实现、数据库设计与交互等核心工作,而不只是停留在前端页面展示层面。
为了更严谨地评估模型的真实编程能力,MiniMax 还将原有的 VIBE 基准测试升级为更复杂、更贴近工业级需求的专业版本,大幅提高了任务难度、领域覆盖范围与评估准确性。从整体结果来看,M2.5 的表现与 Opus 4.5 处于同一梯队。
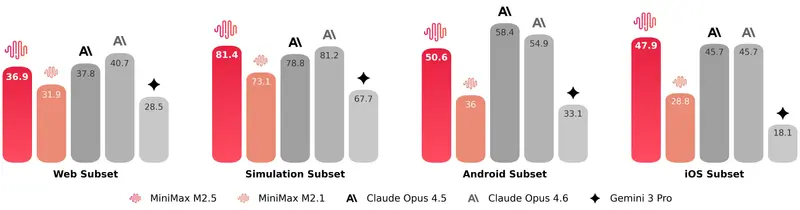
同时,团队重点关注模型在未知框架、陌生环境下的泛化能力,并使用不同的编码智能体框架对 SWE-Bench Verified 评估集进行交叉测试,结果如下:
- 在 Droid 框架上:M2.5 得分 79.7,高于 Opus 4.6 的 78.9
- 在 OpenCode 框架上:M2.5 得分 76.1,高于 Opus 4.6 的 75.9
这意味着 M2.5 不仅在固定基准上表现优秀,在多变的真实开发框架中也具备稳定可靠的输出能力。
搜索与工具调用:专家级信息处理,更少轮次实现更高效率
可靠的工具调用与信息搜索能力,是模型能够自主处理更复杂任务的基础。在 BrowseComp、Wide Search 等行业主流基准测试中,MiniMax M2.5 均取得了行业领先的成绩。同时,模型的泛化能力明显增强,面对不熟悉的框架与环境时,依然能保持稳定输出。
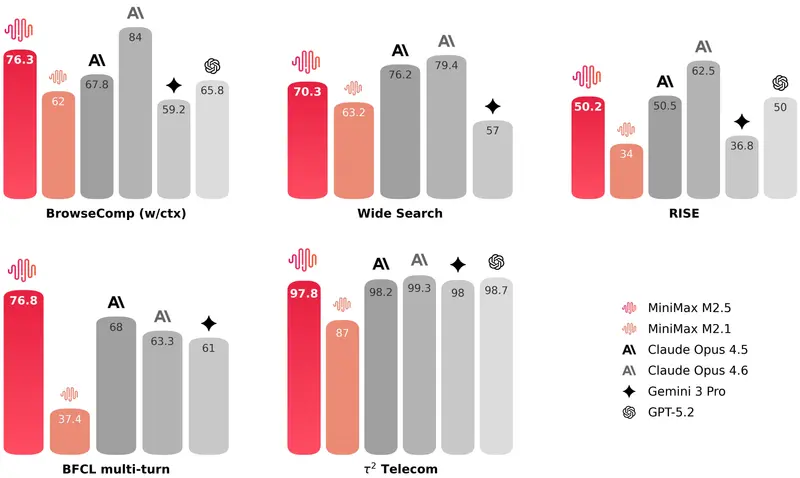
在实际专业场景中,人类专家完成研究任务时,使用搜索引擎只是整个流程中的一小部分,更多时间会花费在信息密集型网页的深度浏览、信息筛选、逻辑梳理上。为此,MiniMax 专门构建了 RISE(真实交互式搜索评估) 基准,用于衡量模型在真实专业任务中的搜索与信息处理能力。结果表明,M2.5 能够在贴近现实世界的专家级搜索任务中保持出色表现。
与前代模型相比,M2.5 在处理智能体任务时拥有更优的决策逻辑:它学会了用更精准的搜索轮次、更高的 token 效率去解决问题。
在 BrowseComp、Wide Search、RISE 等多个典型智能体任务中,M2.5 都能用更少的交互轮次得到更好的结果,整体轮次相比 M2.1 减少了约 20%。这说明模型不再只是简单“找到答案”,而是能通过更高效、更合理的推理路径,更快抵达目标结果。
办公室工作:可直接交付专业成果,高价值场景能力显著提升
MiniMax M2.5 在训练过程中特别针对办公场景进行优化,目标是能够直接生成可落地、可交付的办公成果,而不是仅提供草稿式内容。
为实现这一点,MiniMax 与金融、法律、社会科学等领域的高级专业人士展开深度合作。这些行业专家参与需求设计、效果反馈、评估标准制定,并直接参与训练数据的构建,将大量行业内的隐性知识注入到模型的训练流程中。
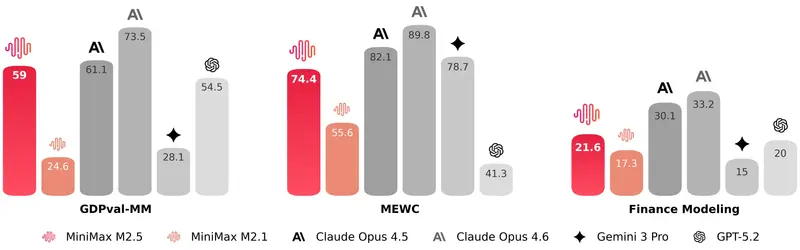
在这样的训练模式下,M2.5 在 Word 文档处理、PPT 制作、Excel 财务建模等高价值办公场景中实现了明显的能力提升。
为科学评估办公能力,团队搭建了内部专用的协同办公智能体评估框架 GDPval-MM。这套框架通过成对比较的方式,评估模型输出成果的质量、智能体执行操作的专业程度,同时全程监控 token 消耗,用来估算模型实际带来的生产力提升。在与其他主流模型的对比中,M2.5 取得了 59.0% 的平均胜率。
执行效率:速度大幅领先,复杂任务耗时显著降低
现实生产环境中, deadlines 与时间限制无处不在,因此任务完成速度是衡量模型实用价值的关键指标。模型完成任务的整体耗时,主要由三方面决定:任务分解效率、token 使用效率、推理速度。
MiniMax M2.5 在这三点上同时实现优化:
- 原生服务速率达到 每秒 100 token,接近其他前沿模型的两倍
- 强化学习机制鼓励模型高效推理、最优分解任务
- 支持并行工具调用,进一步压缩整体耗时
多重优势叠加,让 M2.5 在复杂任务上的耗时显著降低。
以 SWE-Bench Verified 为例:
- M2.5 单任务平均 token 消耗:352 万
- M2.1 单任务平均 token 消耗:372 万
- 端到端平均运行时间:从 31.3 分钟缩短至 22.8 分钟
- 整体速度提升:37%
这一运行速度与 Claude Opus 4.6 的 22.9 分钟基本持平,但 M2.5 单任务总成本仅为 Opus 4.6 的 10%,在速度相当的前提下实现了成本的大幅下降。
使用成本:普惠级定价,前沿能力不再高不可攀
MiniMax 在设计 M2 系列基础模型时,就定下了明确目标:让复杂智能体长期运行不再受成本限制。MiniMax 认为,M2.5 已经非常接近这一目标。
本次官方发布两个版本:M2.5 与 M2.5-Lightning,两者能力完全一致,仅在运行速度上区分:
- M2.5-Lightning:稳定吞吐量 每秒 100 token,速度达到其他前沿模型两倍
- 输入 token:每百万 0.3 美元
- 输出 token:每百万 2.4 美元
- M2.5:吞吐量 每秒 50 token,成本为 Lightning 版本的一半
两个版本均支持缓存功能。从输出价格对比来看,M2.5 的成本仅为 Opus、Gemini 3 Pro、GPT-5 的 十分之一到二十分之一。
官方用非常直观的方式描述成本门槛:
- 每秒 100 token 连续运行一小时:成本 1 美元
- 每秒 50 token 连续运行一小时:成本 0.3 美元
- 10,000 美元,可以支持 4 个 M2..5 实例全年不间断运行
MiniMax 表示,M2.5 以极致的成本优势,为行业内智能体的开发与规模化运营打开了几乎无限的想象空间。对于 M2 系列而言,接下来的核心方向,是持续推动模型能力边界的拓展。
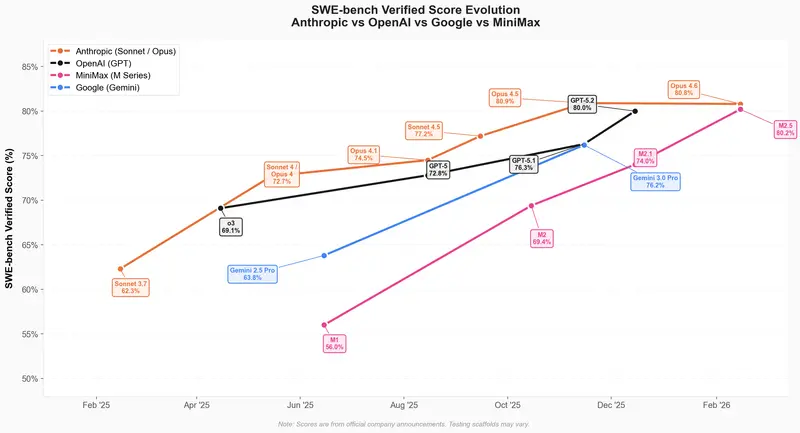
迭代速度:三个半月三连更,进步速度领跑行业
从去年 10 月下旬至今,短短三个半月时间里,MiniMax 连续推出 M2、M2.1、M2.5 三代模型,迭代速度远超最初预期。
在行业认可度极高的 SWE-Bench Verified 基准测试中,M2 系列的提升速度明显快于 Claude、GPT、Gemini 等主流模型系列的同期产品,展现出极强的工程化迭代能力。
RL 扩展:数十万真实环境,支撑强化学习持续升级
M2.5 能够实现快速迭代与能力突破,核心原因之一是强化学习体系的规模化扩展。
在训练模型的同时,MiniMax 也将公司内部绝大多数真实任务与工作环境转化为强化学习的训练环境。截至目前,这样的真实训练环境已经达到数十万个。
与此同时,团队在智能体强化学习框架、底层算法、奖励信号设计、基础设施工程等方向持续投入,为 RL 训练的持续扩展提供稳定支撑。
Forge——智能体原生 RL 框架
MiniMax 内部自研了一套名为 Forge 的智能体原生强化学习框架。
该框架通过引入中间层,将底层训练与推理引擎和上层智能体逻辑完全解耦,支持任意智能体快速接入,同时让模型在不同智能体框架与工具之间的泛化能力得到系统性优化。
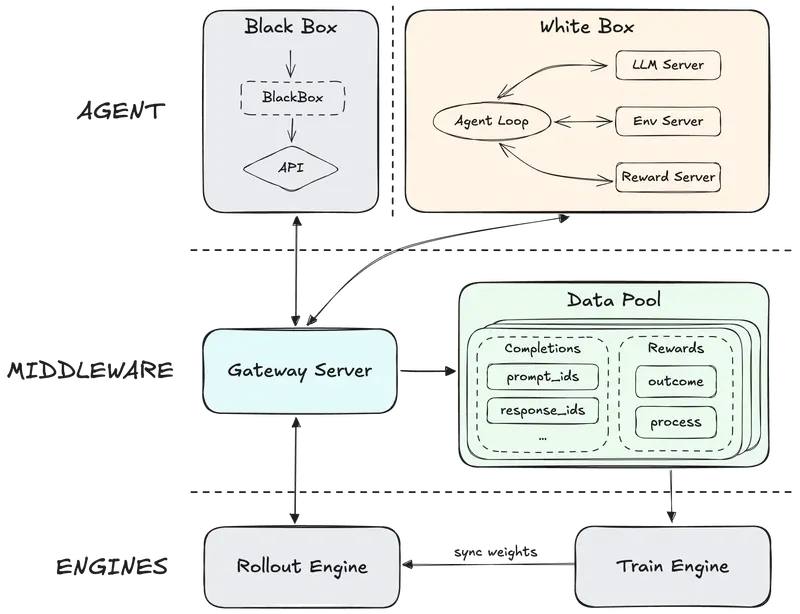
为提升系统吞吐量,团队优化了异步调度策略,在系统吞吐量与样本离策略性之间实现平衡;同时为训练样本设计了树状结构合并策略,最终实现了约 40 倍 的训练加速。
智能体 RL 算法与奖励设计
算法层面,团队继续使用年初提出的 CISPO 算法,保证 MoE 模型在大规模训练过程中的稳定性。
针对智能体执行过程中长上下文带来的信用分配难题,团队引入过程奖励机制,对生成质量进行端到端监控与引导。
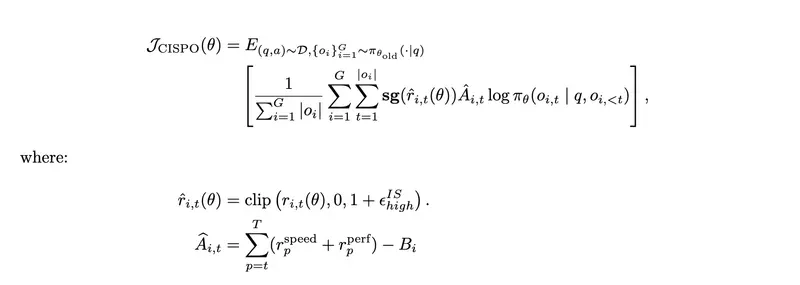
此外,为了更贴合真实用户体验,团队通过智能体执行轨迹评估任务完成时间,在模型能力与响应速度之间找到最优平衡点。
官方表示,关于 RL 扩展的更完整技术细节,将在后续单独的技术博客中详细公开。
MiniMax Agent:把 M2.5 变成专业的“数字员工”
目前,M2.5 已经全面部署在 MiniMax Agent 中,为用户提供当前最优的智能体使用体验。
团队将核心信息处理能力封装成标准化的办公技能,并深度集成到 MiniMax Agent 中。
在 MAX 模式下,当用户处理 Word 排版、PPT 编辑、Excel 计算等任务时,MiniMax Agent 会根据文件类型自动加载对应的办公技能,大幅提升输出结果的规范性与可用性。
在此基础上,用户还可以将通用办公技能与特定行业的专业知识结合,为固定业务场景创建可复用的专家模板。
例如:
- 在行业研究中:将标准化研究框架 SOP 与 Word 技能结合,智能体可以严格按框架自动搜集数据、整理逻辑、输出格式规范的完整研究报告,而不是只输出零散文本
- 在财务建模中:将机构专属建模规范与 Excel 技能结合,智能体可按照指定风控逻辑与计算标准,自动生成并校验复杂财务模型,而不是只生成简单表格
截至目前,用户已经在 MiniMax Agent 上构建了超过 1 万个 自定义专家模板,并且这一数字仍在快速增长。MiniMax 官方也针对办公、金融、编程等高频场景,推出了多套深度优化、开箱即用的专家套件。
MiniMax 自身也是 M2.5 的首批落地用户。
在公司内部日常运营中,有 30% 的整体任务由 M2.5 自主完成,覆盖研发、产品、销售、HR、财务等几乎所有职能部门,且这一渗透率仍在持续上升。
在编程场景中,效果尤为突出:M2.5 生成的代码量占新提交代码的 80%。
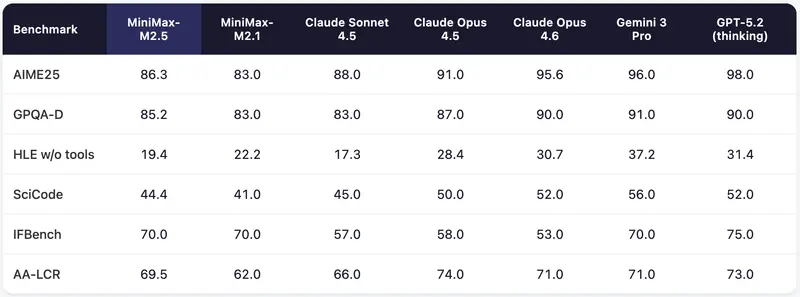
附录:M2.5 更多基准测试结果与评估方法
评估方法说明
SWE 基准
SWE-bench Verified、SWE-bench Multilingual、SWE-bench-pro、Multi-SWE-bench 均在内部基础设施上使用 Claude Code 作为框架测试,采用默认系统提示,结果为 4 次运行平均值。
SWE-bench Verified 同时在 Droid、Opencode 框架使用默认提示完成评估。
Terminal Bench 2
使用 Claude Code 2.0.64 作为评估框架,修改部分问题 Dockerfile 保证正确性,统一沙盒规格 8 核 CPU / 16GB 内存,超时时间 7200 秒,配备基础工具集。
不重试超时任务,对空响应进行异常重试,结果为 4 次运行平均值。
VIBE-Pro
内部基准,使用 Claude Code 自动验证程序交互逻辑与视觉效果,通过统一需求集、容器化部署、动态交互环境计算分数,结果为 3 次运行平均值。
BrowseComp
采用与 WebExplorer (Liu et al., 2025) 相同的智能体框架,token 用量超过最大上下文 30% 时丢弃历史记录。
Wide Search
采用与 WebExplorer (Liu et al., 2025) 相同的智能体框架。
RISE
内部基准,包含人类专家真实问题,评估模型多步信息检索与复杂网页交互能力,在 WebExplorer 基础上增加基于 Playwright 的浏览器工具套件。
GDPval-MM
内部基准,基于开源 GDPval 测试集,使用自定义智能体评估框架,以 LLM 作为评判者进行成对胜负判断,按各厂商官方 API 价格计算平均 token 成本(不含缓存)。
MEWC
内部基准,基于微软 Excel 世界锦标赛 MEWC,包含 2021–2026 年赛事共 179 题,评估模型理解竞赛表格并完成任务的能力,按单元格逐一对标评分。
金融建模
内部基准,由行业专家构建,包含基于 Excel 的端到端研究与分析任务,采用专家设计的评分标准,结果为 3 次运行平均值。
AIME25 ~ AA-LCR
基于 Artificial Analysis 智能指数排行榜的公开评估集与方法,通过内部测试得到结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...