ComfyUI AudioSR 是专为 ComfyUI 打造的原生音频超分辨率节点,基于先进的潜在扩散模型 AudioSR 实现,可将任意低质量音频上采样至 48kHz,并增强高频细节、修复压缩失真,实现音质显著提升。
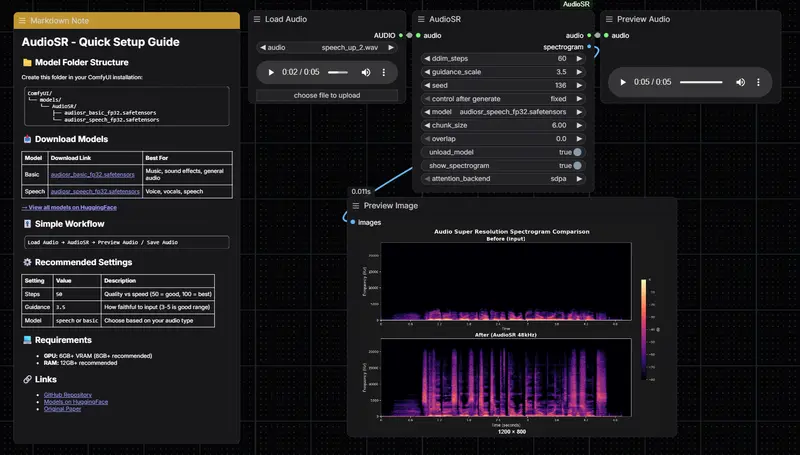
核心功能特性
- 音频超分辨率增强:将低采样率、低码率音频上采样至标准 48kHz,补充高频成分,提升清晰度与饱满度。
- 原生 ComfyUI 集成:与加载音频、预览音频、保存音频等官方节点无缝衔接,工作流搭建简单。
- 频谱图可视化对比:内置增强前后频谱图输出,直观展示频率修复效果,带时间轴与频率轴。
- 自适应采样率处理:支持 8kHz–48kHz 任意输入采样率,自动重采样与适配。
- 完整声道支持:同时支持单声道与立体声音频,左右声道独立处理。
- 超长音频支持:采用智能分块 + 重叠交叉淡化机制,理论支持无限时长音频处理。
- 模型缓存机制:模型加载后常驻内存,重复生成速度大幅提升。
- torch.compile 加速:可选开启 PyTorch 编译优化,推理速度提升 20%–30%。
- 灵活显存管理:支持生成后自动卸载模型,释放 GPU 显存,适配小显存设备。
- 过程可中断:支持 ComfyUI 原生中断按钮,可随时取消处理。
- 实时进度显示:分块处理进度条实时展示,长音频处理更透明。
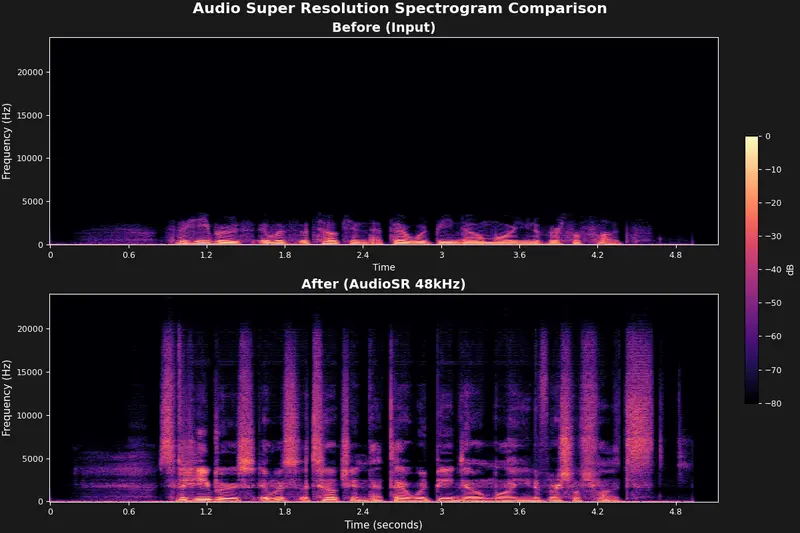
性能优化详解
1. torch.compile 加速模式
节点提供 use_torch_compile 开关,启用后对模型执行编译优化。
速度收益
- 首次运行需 10–30 秒编译开销
- 后续推理速度提升 20%–30%
- 与 FP32 模型搭配效果最佳
适用场景
- 同一会话批量处理多个音频
- 长音频分块重复推理
- 追求稳定高速输出
- FP32 模型优先开启
注意事项
- 仅支持 FP32 模型,FP16/FP8 会自动跳过编译
- 一次性快速测试不推荐启用
- 模型或参数变更后会自动重新编译
2. 优化默认参数
节点对分块、重叠、注意力机制进行了针对性调优,显著提升长音频速度:
| 参数 | 默认值 | 优化效果 |
|---|---|---|
| chunk_size | 15.0s | 分块数量大幅减少,长音频速度提升约 60% |
| overlap | 0.0s | 无重叠基础模式,处理更快 |
| attention_backend | sdpa | 使用 PyTorch 原生最高效注意力实现 |
3. 底层优化与安全增强
- 移除冗余张量格式转换
- 智能模型缓存 + 自动重编译检测
- 优化量化模型数据类型识别
- 安全除法与数值稳定性修复
- 内存高效的交叉淡化重叠算法
- 模型加载使用
weights_only=True,防止恶意代码执行 - 加载前校验张量数据类型,提升稳定性
系统要求
- 最低显存:6GB
- 推荐显存:8GB 及以上
- 依赖项自动安装,无需外部工具
安装方法
方法 1:ComfyUI 管理器(推荐)
- 打开 ComfyUI Manager
- 搜索
AudioSR - 点击安装
- 重启 ComfyUI
方法 2:手动安装
cd ComfyUI/custom_nodes
git clone https://github.com/Saganaki22/ComfyUI-AudioSR.git
cd ComfyUI-AudioSR
pip install -r requirements.txt
Windows 便携版嵌入式 Python:
..\python_embeded\python.exe -s -m pip install -r requirements.txt
模型下载与存放路径
模型需手动下载并放入指定目录:
下载地址:https://huggingface.co/drbaph/AudioSR/tree/main/AudioSR
必须目录结构
ComfyUI/
└── models/
└── AudioSR/
├── audiosr_basic_fp32.safetensors
└── audiosr_speech_fp32.safetensors
模型说明
audiosr_basic_fp32:通用音频(音乐、音效、环境声)audiosr_speech_fp32:语音专用(人声、对话、录音增强)
显存占用说明
| 模式 | 显存占用 | 适用设备 |
|---|---|---|
| 标准模式 | ~6GB | RTX 3060 及以上 |
| 开启 unload_model | 空闲仅 ~0.5GB | 小显存/多模型切换环境 |
最低:6GB
推荐:8GB+
AudioSR 节点完整参数说明
核心功能
将任意输入音频上采样至 48kHz,修复高频缺失、压缩伪影、模糊听感,适用于老旧录音、低码率 MP3、直播录音、视频配音等场景。
输入参数
必需参数
- audio:AUDIO 输入(来自加载音频节点)
- ddim_steps:扩散去噪步数(10–500)默认 50
- guidance_scale:CFG 引导强度(1.0–20.0)默认 3.5
- seed:随机种子,0 为随机
可选参数
- model:选择 basic / speech 模型
- chunk_size:分块时长(2.56–30s)默认 15s
- overlap:分块重叠时长(0–5s)默认 0s
- unload_model:生成后卸载模型释放显存
- show_spectrogram:输出增强前后频谱图
- attention_backend:sdpa / eager
- use_torch_compile:启用编译加速(仅 FP32)
输出
- audio:48kHz 超分增强音频
- spectrogram:对比频谱图(可关闭)
典型工作流示例
基础快速上采样
加载音频 → AudioSR → 预览/保存音频
默认参数即可获得明显提升。
高质量模式(推荐成品输出)
- ddim_steps: 100
- guidance_scale: 5.0
- model: speech(人声)/ basic(音乐)
- overlap: 2.0
- show_spectrogram: True
小显存兼容模式
- unload_model: True
- ddim_steps: 50
- chunk_size: 10s 或更低
长音频专业模式
- chunk_size: 20–30s
- overlap: 2.0–3.0s
- use_torch_compile: True(FP32)
高级参数调优指南
ddim_steps(质量–速度平衡)
- 10–30:快速预览,质量一般
- 50:默认,平衡可用
- 100:高质量输出
- 200+:最高质量,极慢
guidance_scale(忠实度)
- 1.0–2.0:创造性强,可能偏离原始音色
- 3.0–4.0:默认平衡,最通用
- 5.0–8.0:高度忠实输入,修复更保守
- 10.0+:过于严格,易生硬不自然
chunk_size(分块时长)
- 2.56–5:小显存安全,慢
- 15:默认,平衡
- 20–30:大显存优选,速度最快
overlap(重叠平滑)
- 0.0:最快,可能出现接缝
- 2.0:推荐通用值
- 3.0–5.0:最平滑,处理耗时增加
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...