ComfyUI-Qwen-TTS 是基于阿里巴巴 Qwen 团队开源项目 Qwen3-TTS 开发的专用自定义节点集,专为 ComfyUI 提供一站式文本转语音、声音克隆、声音设计与多角色对话合成能力,支持高质量、低延迟、多语言的端到端语音生成。
- GitHub:https://github.com/flybirdxx/ComfyUI-Qwen-TTS
- 作者教程:https://space.bilibili.com/5594117?spm_id_from=333.1007.0.0
功能特性
- 高质量语音合成:原生支持高保真文本转语音生成。
- 零样本声音克隆:仅需 5–15 秒参考音频,即可实现零样本音色复刻。
- 自然语言声音设计:通过文本描述直接生成指定风格、音色、情绪的声音。
- 高效推理架构:支持 12Hz、25Hz 双架构语音 Tokenizer,兼顾速度与音质。
- 多语言支持:原生支持中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文共 10 种主流语言。
- 一体化模型加载:无需独立加载器节点,模型按需加载并支持全局缓存。
- 超低延迟生成:基于新一代架构实现快速语音重建与流式输出。
- 多种注意力机制:支持 sage_attn、flash_attn、sdpa、eager,并支持自动检测与优雅降级。
- 灵活显存管理:支持生成后自动卸载模型,释放 GPU 资源。
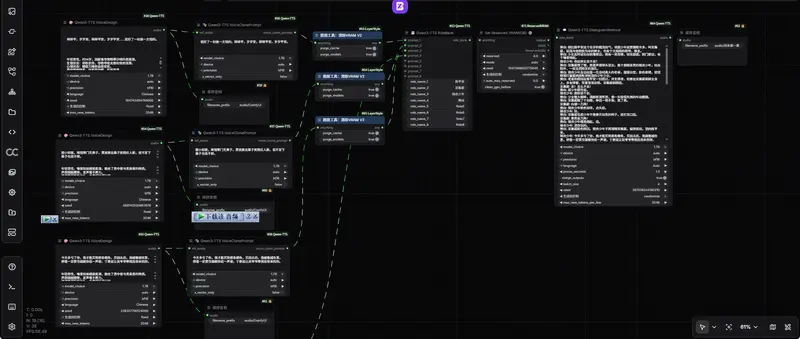
节点功能说明
ComfyUI-Qwen-TTS 提供完整的语音生成、克隆、管理、对话编排节点,覆盖从单句 TTS 到多角色有声书全场景。
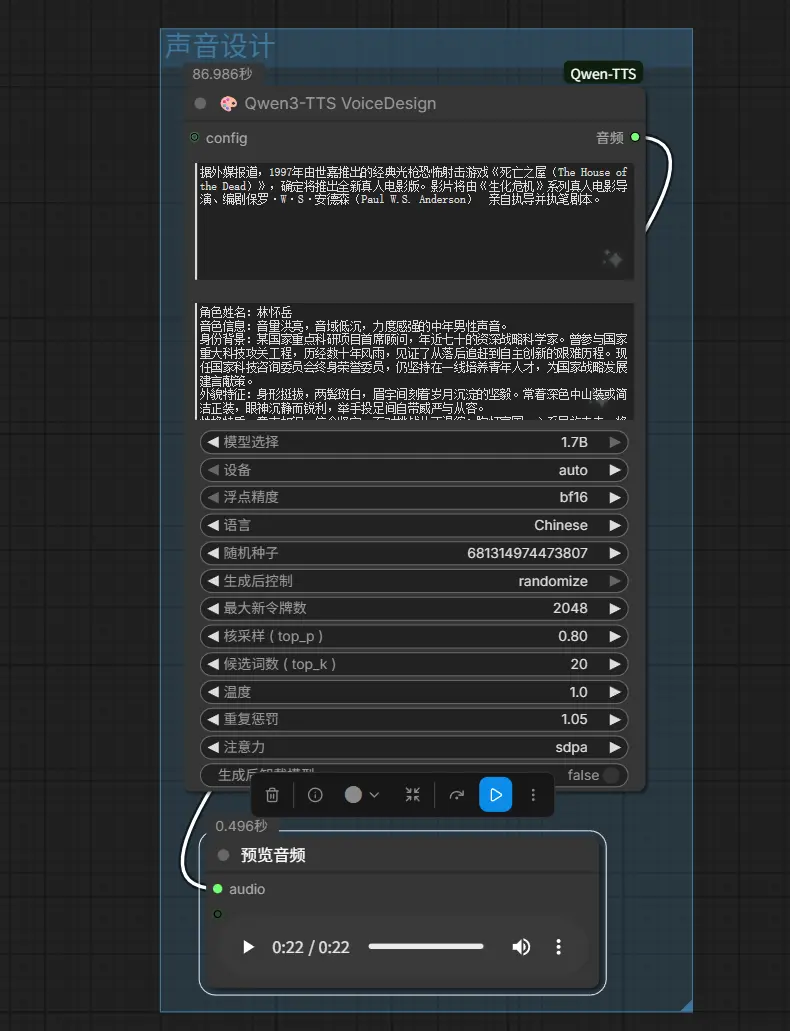
1. Qwen3-TTS 声音设计(VoiceDesignNode)
通过自然语言描述创建专属音色,适合构建虚构角色、特定声线人设。
输入:
text: 要合成的目标文本。instruct: 声音描述指令(例如:"一个温和的高音女声")。model_choice: 目前声音设计功能锁定为 1.7B 模型。attention: 注意力机制 (auto, sage_attn, flash_attn, sdpa, eager)。unload_model_after_generate: 生成后从内存卸载模型以释放 GPU 内存。
能力: 最适合创建"想象中的"声音或特定的人设。
2. Qwen3-TTS 声音克隆(VoiceCloneNode)
从参考音频克隆音色并生成新语音。(建议搭配之前介绍的ComfyUI-QwenASR一起使用)
输入:
ref_audio: 一段短的(5-15秒)参考音频。ref_text: 参考音频中的文本内容(有助于提高质量)。target_text: 你希望克隆声音说出的新文本。model_choice: 可选择 0.6B(速度快)或 1.7B(质量高)。attention: 注意力机制 (auto, sage_attn, flash_attn, sdpa, eager)。unload_model_after_generate: 生成后从内存卸载模型以释放 GPU 内存。
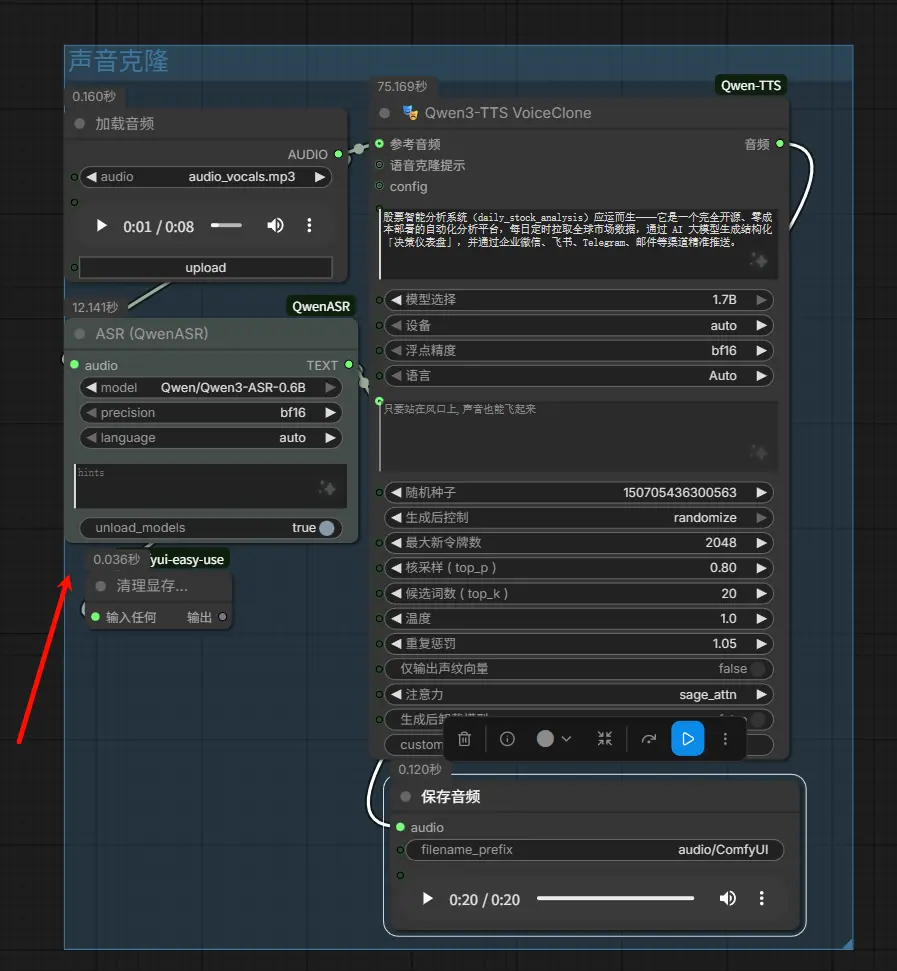
3. Qwen3-TTS 预设声音(CustomVoiceNode)
使用官方预设音色进行标准 TTS 合成。
输入:
text: 目标文本。speaker: 从预设声音中选择(Aiden, Eric, Serena 等)。instruct: 可选的风格指令。attention: 注意力机制 (auto, sage_attn, flash_attn, sdpa, eager)。unload_model_after_generate: 生成后从内存卸载模型以释放 GPU 内存。
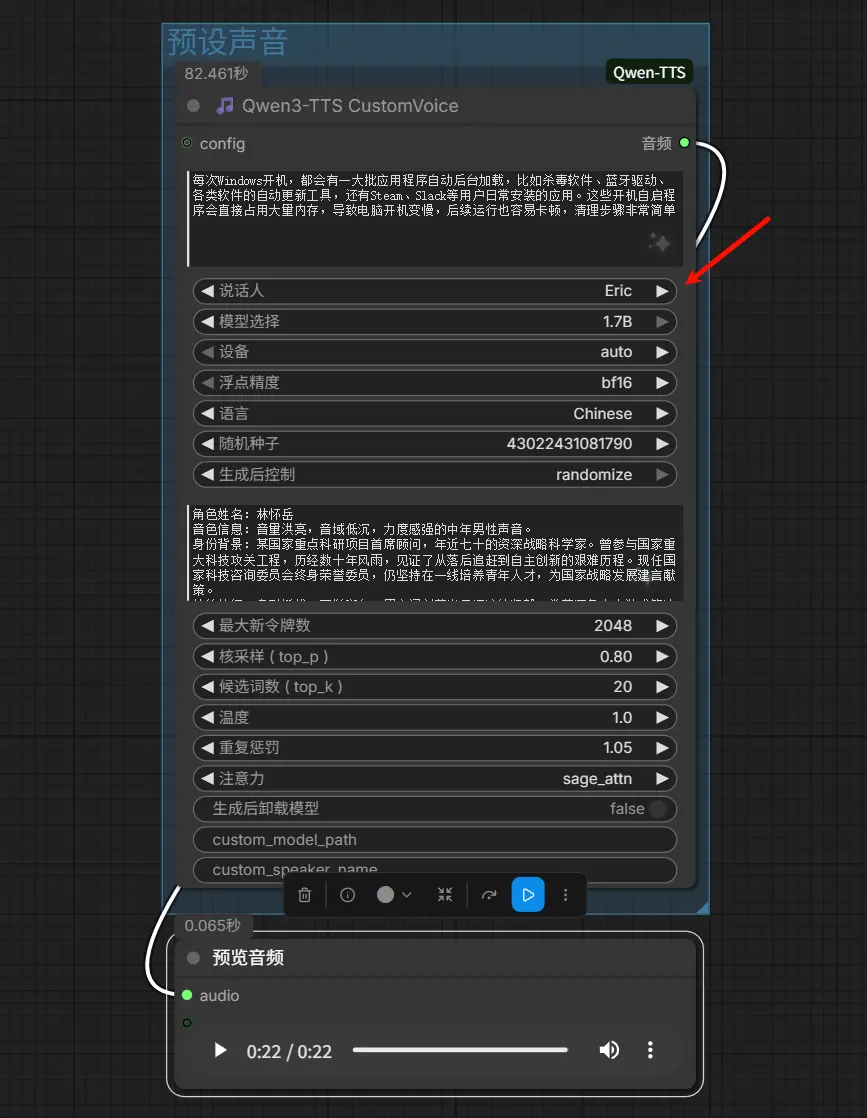
4. Qwen3-TTS 角色银行(RoleBankNode)【新增】
集中管理多个角色声音,用于多角色对话编排。
输入:
最多 8 个角色,每个角色包含:
role_name_N: 角色名称(例如:"Alice", "Bob", "旁白")prompt_N: 来自VoiceClonePromptNode的声音克隆提示
能力: 创建命名的声音注册表,用于 DialogueInferenceNode。每个银行最多支持 8 种不同的声音。
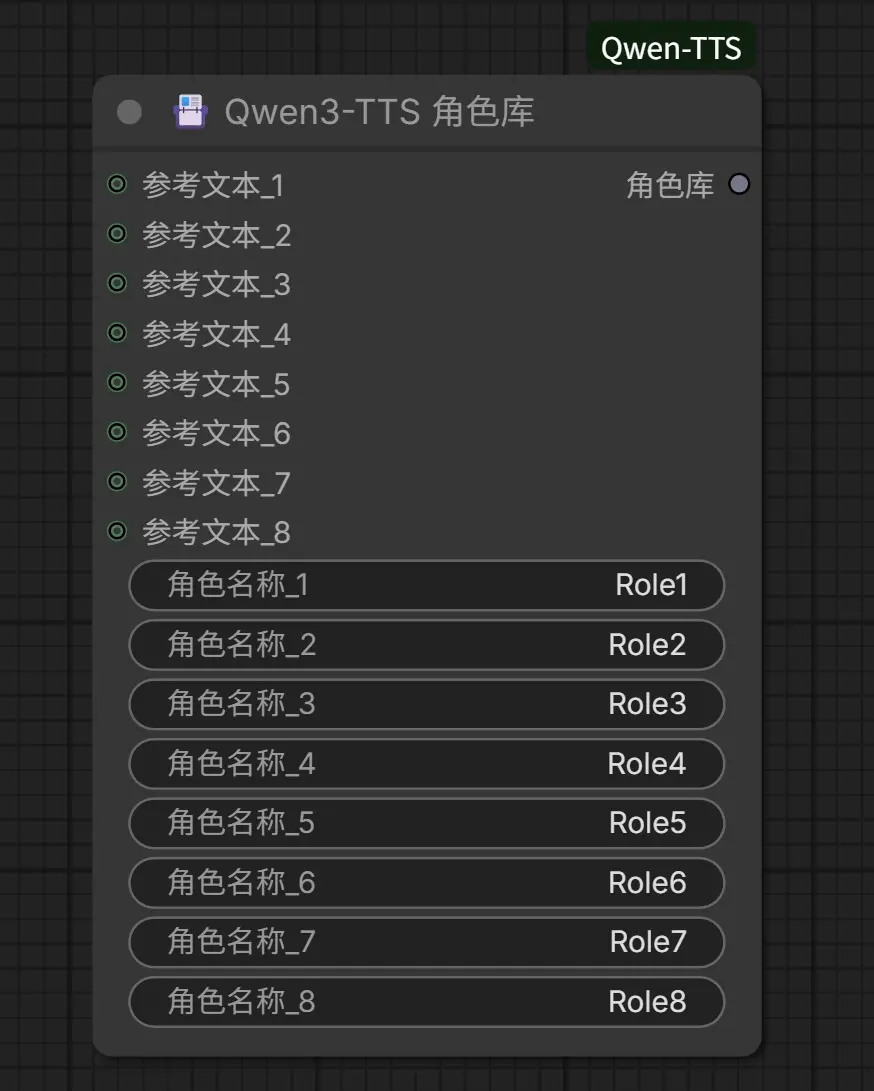
5. Qwen3-TTS 声音克隆 Prompt(VoiceClonePromptNode)【新增】
提取参考音频的声音特征,生成可复用的声音提示。
输入:
ref_audio: 一段短的(5-15秒)参考音频。ref_text: 参考音频中的文本内容(强烈推荐以提高质量)。model_choice: 可选择 0.6B(速度快)或 1.7B(质量高)。attention: 注意力机制 (auto, sage_attn, flash_attn, sdpa, eager)。unload_model_after_generate: 生成后从内存卸载模型以释放 GPU 内存。
能力: 只需提取一次"Prompt 节点",即可在多个 VoiceCloneNode 实例中复用,提高生成效率并保证音质一致性。
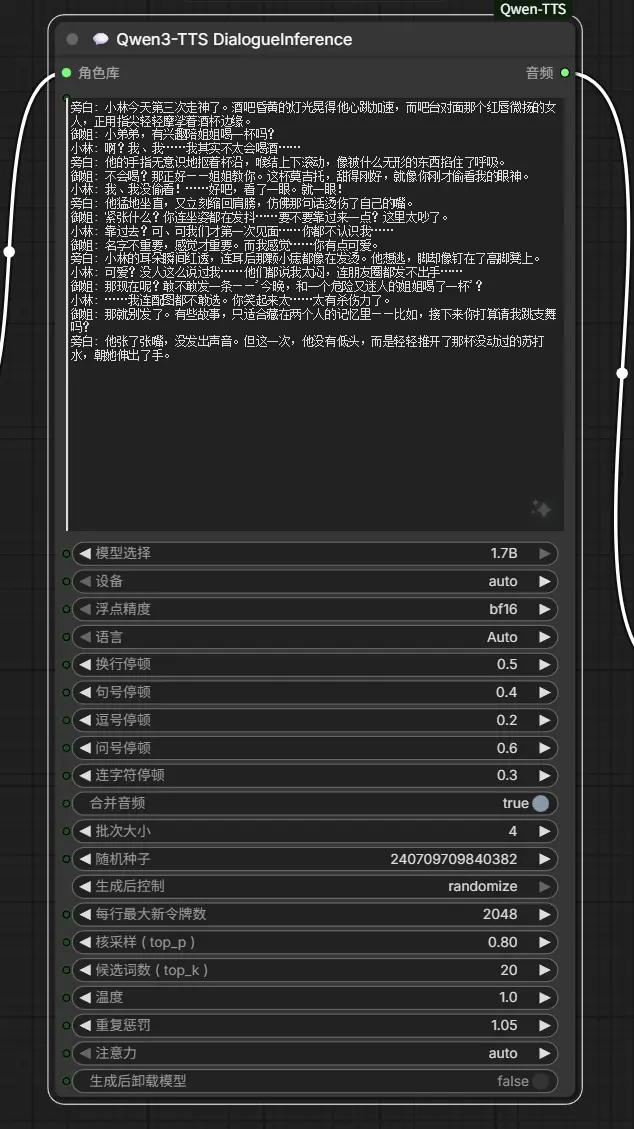
6. Qwen3-TTS 多角色对话(DialogueInferenceNode)【新增】
支持复杂剧本、多角色对话批量合成,适用于有声书、短剧、角色扮演。
输入:
script: 对话脚本,格式为"角色名: 文本"。role_bank: 来自RoleBankNode的角色银行,包含声音提示。model_choice: 可选择 0.6B(速度快)或 1.7B(质量高)。attention: 注意力机制 (auto, sage_attn, flash_attn, sdpa, eager)。unload_model_after_generate: 生成后从内存卸载模型以释放 GPU 内存。pause_seconds: 句子之间的静音持续时间。merge_outputs: 将所有对话片段合并为一段长音频。batch_size: 并行处理的行数(越大越快,但占用更多显存)。
能力: 在单个节点内处理多角色语音合成,非常适合有声书制作或角色扮演场景。
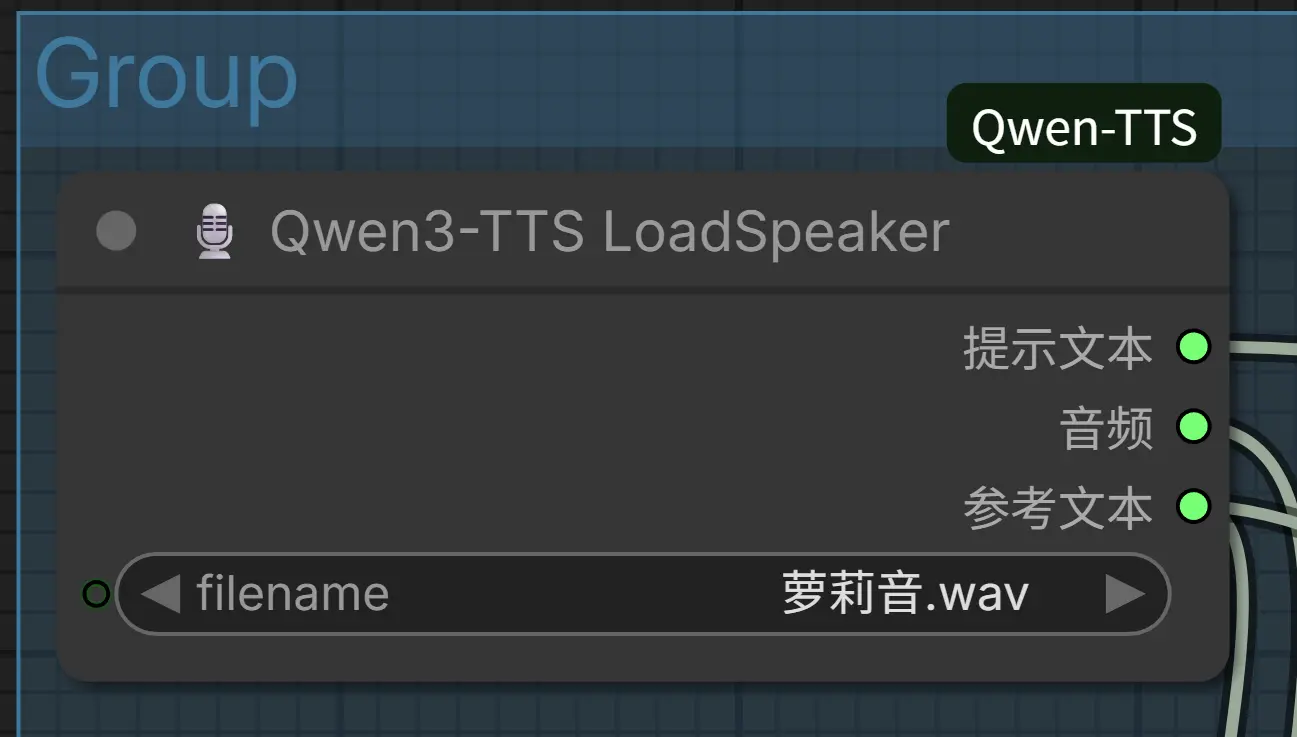
7. Qwen3-TTS 加载声音(LoadSpeakerNode)【新增】
加载已保存的声音特征与参考文本,实现一键复用个人音色库。
- 输入: 选择已保存的
.wav文件。 - 能力: 实现“一键加载”体验,自动同步加载预计算特征和参考文本。
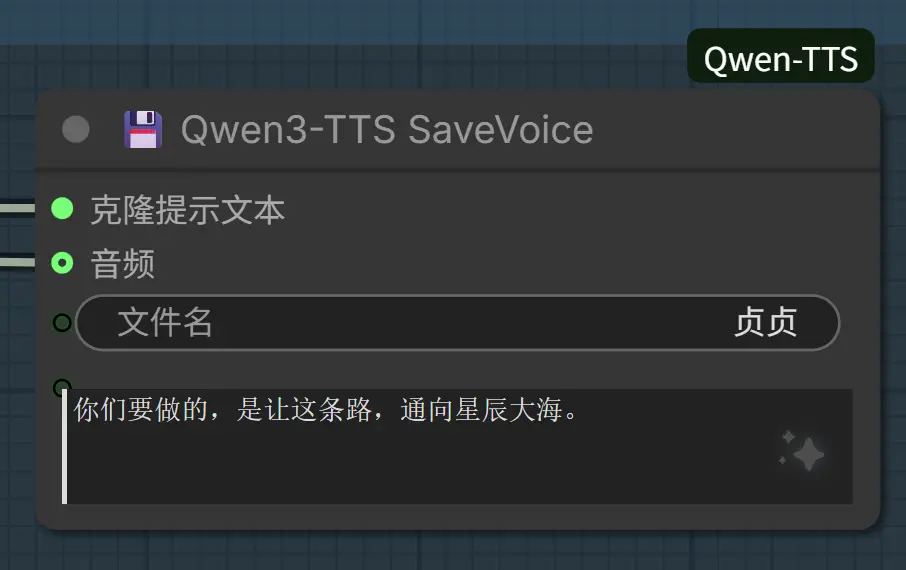
8. Qwen3-TTS 保存声音(SaveVoiceNode)【新增】
将克隆音色、特征与文本永久保存至本地,构建可管理的个人声音库。
- 能力: 建立个性化声音库。保存后可通过
LoadSpeakerNode极速调用。
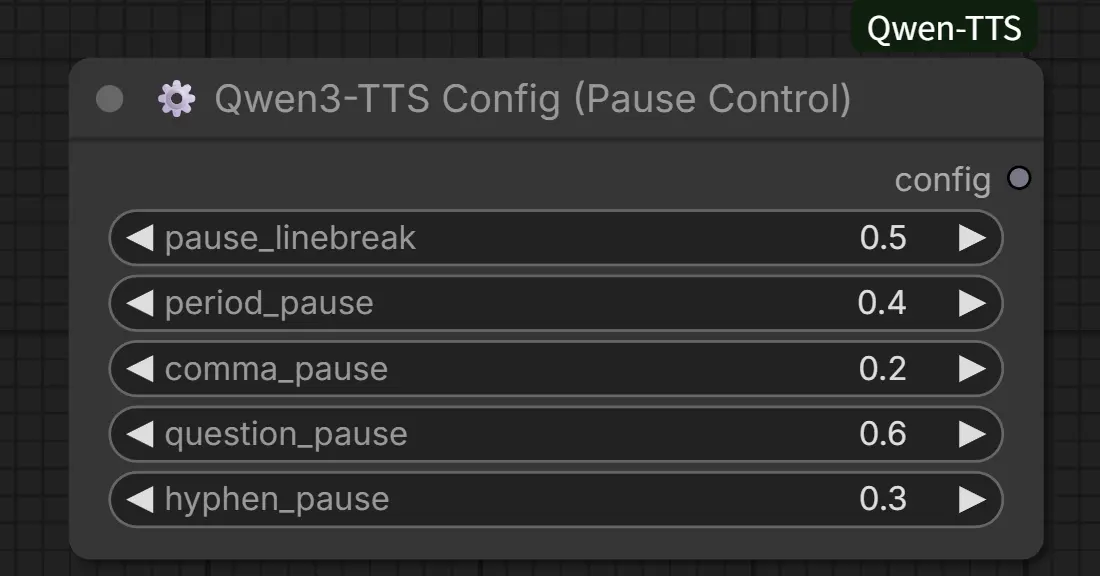
9. Qwen3-TTS 全局配置(QwenTTSConfigNode)【新增】
精细化控制语音节奏与标点停顿,提升自然度。
输入:
pause_linebreak: 换行符处的停顿时间。period_pause: 句号 (.) 后的停顿时间。comma_pause: 逗号 (,) 后的停顿时间。question_pause: 问号 (?) 后的停顿时间。hyphen_pause: 连字符 (-) 后的停顿时间。
用法: 连接到其他 TTS 节点的 config 输入端。
注意力机制与自动选择
所有节点均支持多种注意力加速方案,并具备自动检测与优雅降级能力。
| 注意力机制 | 说明 | 速度 | 依赖安装 |
|---|---|---|---|
| sage_attn | SAGE 注意力 | 最快 | pip install sage_attn |
| flash_attn | Flash Attention 2 | 快 | pip install flash_attn |
| sdpa | PyTorch 内置缩放点积注意力 | 中等 | 内置,无需安装 |
| eager | 标准注意力(兜底) | 最慢 | 内置,无需安装 |
| auto | 自动选择最优方案 | 自适应 | 无需配置 |
自动选择优先级(auto 模式)
sage_attn → flash_attn → sdpa → eager
优雅降级机制
若指定注意力不可用,系统将自动降级至可用方案,并在控制台输出提示与日志。
模型缓存与显存管理
模型缓存
- 缓存按注意力机制区分,不同机制可共存
- 切换注意力会自动清空缓存并重新加载模型
生成后卸载模型(全局开关)
所有节点均提供 unload_model_after_generate 选项:
- 启用:生成后清空缓存、释放 GPU、执行垃圾回收(适合小显存 / 多模型切换)
- 禁用:模型保留缓存,后续生成更快(默认,适合连续生成)
推荐场景
- 显存 < 8GB:建议开启
- 频繁切换不同模型:建议开启
- 同模型连续生成:建议关闭
安装依赖
pip install torch torchaudio transformers librosa accelerate
模型目录结构
插件默认按以下路径自动搜索模型:
ComfyUI/
└── models/
└── qwen-tts/
├── Qwen/Qwen3-TTS-12Hz-1.7B-Base/
├── Qwen/Qwen3-TTS-12Hz-0.6B-Base/
├── Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign/
├── Qwen/Qwen3-TTS-Tokenizer-12Hz/
└── voices/ # 保存自定义音色
也可通过 extra_model_paths.yaml 自定义模型根目录:
qwen-tts: D:\MyAI\Models\Qwen
最佳实践
音质优化
- 声音克隆使用清晰、无噪音、5–15 秒参考音频
- 提供参考文本可显著提升克隆准确度
- 选择对应语言以保证韵律与发音准确
性能与显存
- 小显存(<8GB)建议开启
unload_model_after_generate - 优先使用
attention: auto自动选择最优加速 - 本地预下载模型可避免 HuggingFace 连接超时
- 追求极致速度:安装 sage_attn / flash_attn 可提速 2–3 倍
- 兼容性优先:使用 sdpa(内置无需安装)
- OOM 异常:切换为 eager 并使用 0.6B 模型
多角色对话
- 提高
batch_size可加速生成(占用更高显存) - 调整
pause_seconds优化对话节奏 - 启用
merge_outputs输出完整连续音频
其他同类节点:
- https://github.com/wanaigc/ComfyUI-Qwen3-TTS
- https://github.com/starsFriday/ComfyUI-Qwen3-TTS
- https://github.com/DarioFT/ComfyUI-Qwen3-TTS
- https://github.com/filliptm/ComfyUI-FL-Qwen3TTS
Flash Attention
- https://github.com/sdbds/flash-attention-for-windows
- https://github.com/wildminder/AI-windows-whl
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...