智谱AI开源的超强多模态OCR模型GLM-OCR,刚推出就迎来重磅支持——Ollama已第一时间完成适配,仅需升级至Ollama 0.15.5预发布版,就能用极简的命令行,实现复杂文档、表格、图表的快速识别,轻量又高效。
GLM-OCR作为专为复杂文档理解打造的模型,基于GLM-V编码器-解码器架构构建,核心组件拉满:集成大规模图文预训练的CogViT视觉编码器、高效令牌下采样的轻量级跨模态连接器,搭配GLM-0.5B语言解码器,兼顾识别精度与推理速度,是目前业界表现顶尖的OCR模型之一。
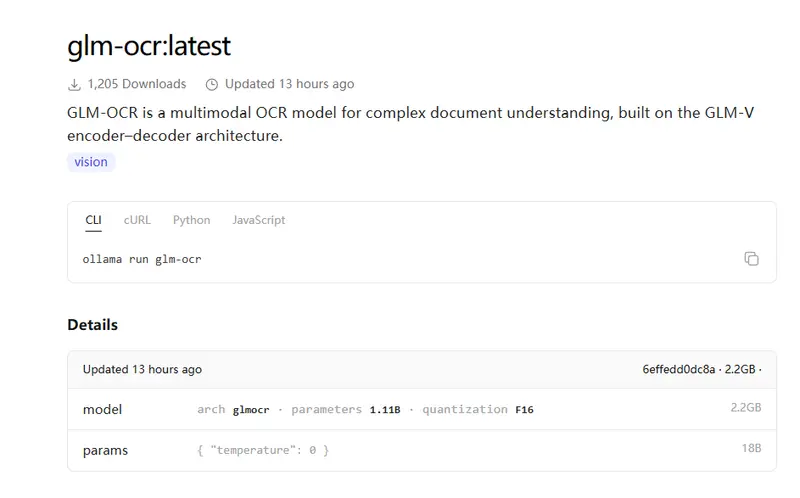
重要前提:升级Ollama至0.15.5预发布版
使用Ollama调用GLM-OCR有个关键要求——必须将Ollama升级到0.15.5版本,该版本目前为预发布版,需先完成升级才能正常加载模型,这是调用的基础前提。
极简使用!三类核心识别场景,一行命令直达
无需复杂配置、不用搭建环境,升级后直接在终端输入命令,即可实现不同类型的文档识别,图片路径直接跟在命令后,新手也能秒上手。
1. 文本识别(通用文档/带印章/代码文档均可)
ollama run glm-ocr 文本识别: ./图片.png
2. 表格识别(复杂表格结构精准还原)
ollama run glm-ocr 表格识别: ./图片.png
3. 图表识别(图表内文字/数值高效提取)
ollama run glm-ocr 图表识别: ./图片.png
再敲重点:GLM-OCR的4大核心优势
能让Ollama火速适配,核心还是GLM-OCR本身的硬实力,轻量、能打、易用、适配性强,覆盖个人开发到企业生产全场景:
- 业界顶尖性能:在OmniDocBench V1.5权威基准测试中拿下94.62分,综合排名第一,公式识别、表格识别、信息提取等核心文档理解任务均达当前最优水平;
- 真实场景拉满:专为实际业务优化,面对复杂表格、代码密集型文档、带印章官方文件等挑战性版式,识别效果依然稳健,不挑场景;
- 轻量高效推理:仅9亿参数,轻量化设计大幅降低推理延迟和计算成本,还支持vLLM、SGLang、Ollama多方式部署,高并发服务、边缘部署都能轻松hold住;
- 开源易用易集成:完全开源,配套完整SDK和推理工具链,安装简单、调用便捷,还能无缝融入现有生产流水线,无需大量二次开发,落地成本极低。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...