
麻省理工学院和 Adobe 研究中心的研究人员推出DMD2(Distribution Matching Distillation的改进版),这是一种改进图像合成技术,特别是针对大语言模型在图像生成方面的应用,旨在通过高效的一步生成模型来加速图像合成过程,同时保持或甚至超越原始模型的质量。DMD2在ImageNet和COCO 2014数据集上进行了评估,展示了其在图像质量和多样性方面的优势。此外,研究者们还开源了代码和预训练模型,以促进这一领域的进一步研究。
- 项目主页:https://tianweiy.github.io/dmd
- GitHub:https://github.com/tianweiy/DMD2
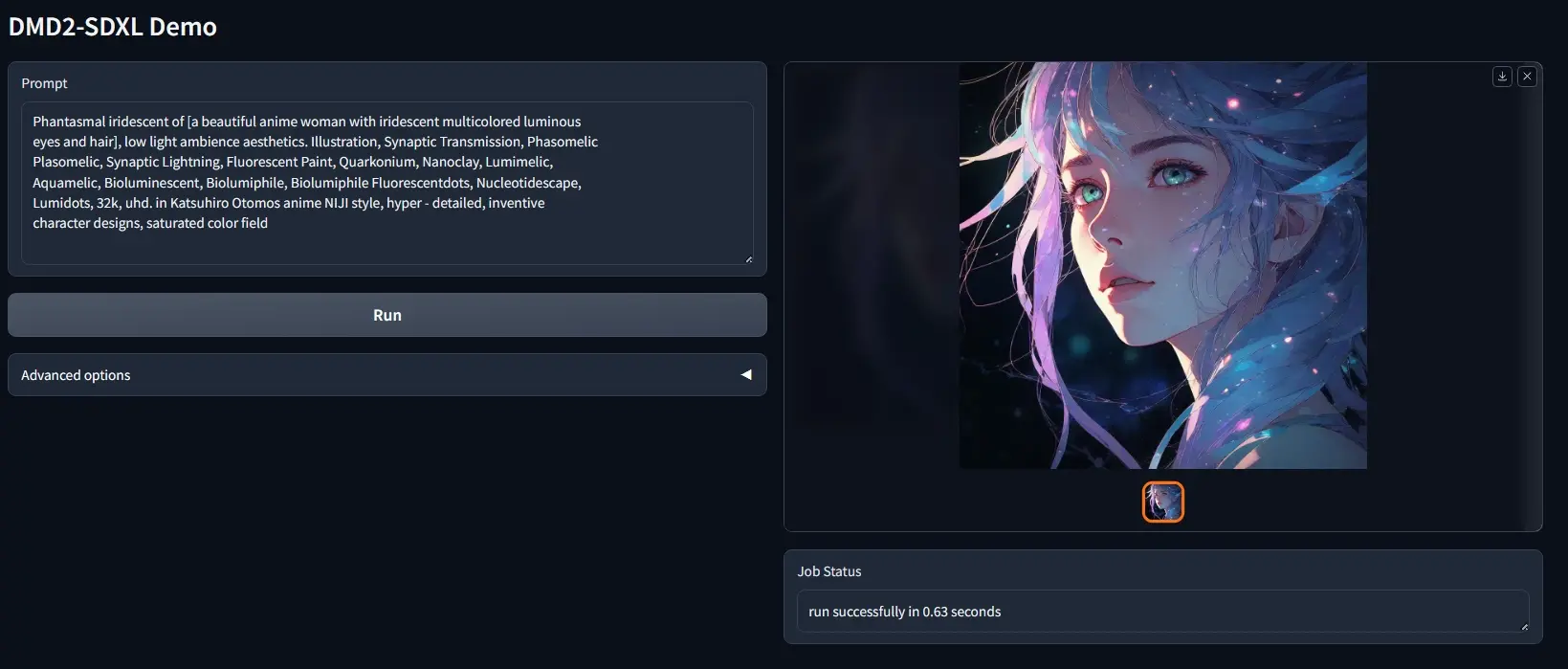
- Demo:https://913f7051c61c070e4e.gradio.live
例如,你是一名游戏设计师,需要快速生成大量独特的游戏环境图像。使用DMD2,你可以通过简单的文本描述来指导模型,一步生成与描述相符的图像,大大加快设计过程。例如,输入文本提示“一个未来主义的城市景观”,DMD2能够迅速生成相应的高质量图像,而不需要传统的多步骤渲染过程。

主要功能和特点:
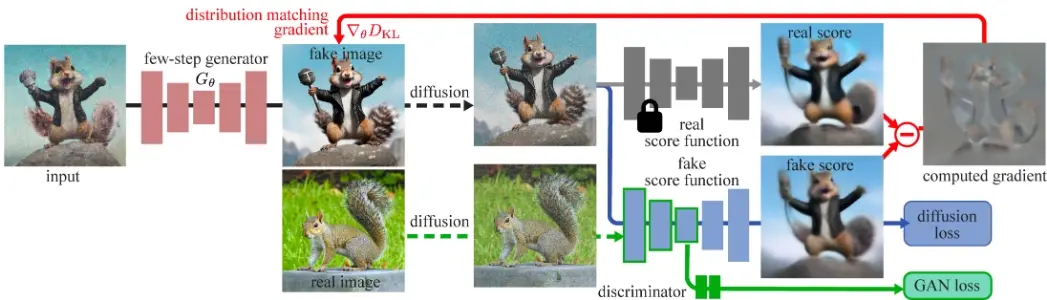
- 一步生成:DMD2能够将复杂的扩散模型(一种通常需要多次迭代去噪步骤来生成图像的模型)转化为只需一步就能生成高质量图像的模型。
- 高效性:相比于原始的扩散模型,DMD2在推理成本上大幅降低,同时保持了图像质量和多样性。
- 多步采样支持:DMD2不仅支持一步生成,还能够支持多步采样,以适应不同的图像生成需求。
- 训练稳定性:通过双时间尺度更新规则(Two Time-scale Update Rule),DMD2在训练过程中更加稳定,不容易出现性能波动。
工作原理:
- 去除回归损失:DMD2去除了DMD中用于稳定训练的回归损失,这使得模型不再受限于原始模型的采样路径,能够更自由地生成图像。
- 双时间尺度更新规则:为了解决去除回归损失后可能出现的训练不稳定性,DMD2采用了双时间尺度更新规则,即以不同的频率更新生成模型和分数估计模型。
- GAN损失整合:DMD2将生成对抗网络(GAN)的损失整合到训练过程中,使得生成的图像不仅与真实图像分布一致,而且能够欺骗GAN判别器。
- 多步生成器模拟:DMD2通过模拟推理时的生成器输入来进行训练,从而避免了训练和推理之间的输入不匹配问题。
具体应用场景:
- 图像合成:DMD2可以用于快速生成高质量的图像,适用于需要大量图像生成的场景,如游戏设计、虚拟现实、电影制作等。
- 文本到图像的合成:DMD2还能够根据文本描述生成相应的图像,这对于自动内容创作、教育工具、广告创意等领域具有潜在的应用价值。
- 艺术创作辅助:艺术家和设计师可以利用DMD2来快速生成草图或概念图,从而加速创作过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











