
来自中国台湾阳明交通大学的研究人员推出新型神经网络渲染技术Joint-TensoRF,提高神经渲染中相机姿态和场景几何表示的联合优化性能,特别是在处理复杂场景时的鲁棒性,这对于许多3D视觉和图形应用领域都是非常重要的
该算法仅使用2D图像作为监督,就能实现相机姿态和场景几何的精细调整。简单来说,这项技术可以让我们从任意角度看到物体的三维图像,就像真实世界中的物体一样。传统的三维渲染技术通常需要复杂的模型和大量的计算资源,而Joint-TensoRF通过一种更智能、更高效的方式来生成这些图像。
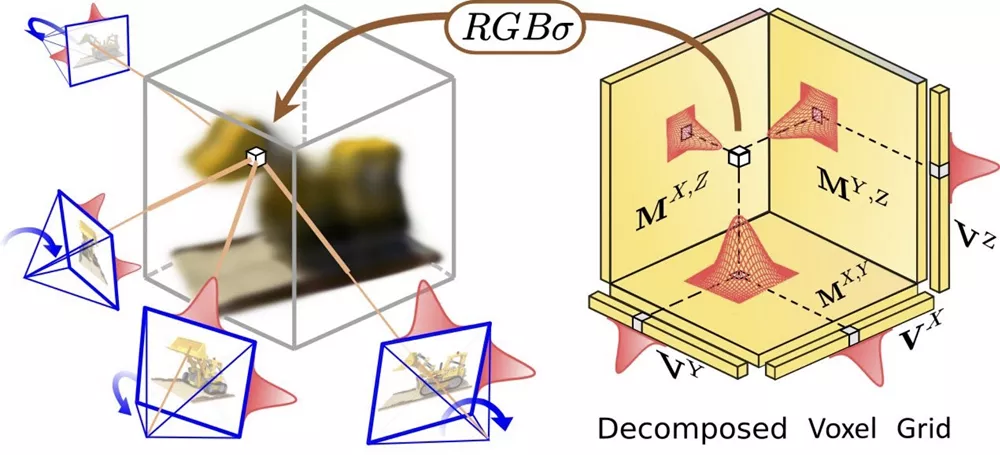
主要功能:
- 提高在神经渲染(neural rendering)中相机姿态和场景几何表示的联合优化的鲁棒性。
- 使用分解的低秩张量来高效地表示和优化3D场景。
主要特点:
- 分解的低秩张量: 使用这种数据结构来减少内存使用并提高计算效率,同时保持高质量的3D场景表示。
- 粗到细的训练策略: 通过控制2D和3D辐射场(radiance fields)上的高斯滤波器,实现从粗到细的训练过程,以优化相机姿态。
- 鲁棒性增强技术: 包括平滑的2D监督、随机缩放的核参数和边缘引导损失掩模(edge-guided loss mask),以提高优化过程的稳定性。

工作原理:
- 1D信号对齐的试点研究: 通过分析1D信号的频谱特性,研究者们发现控制频谱对于姿态对齐至关重要。
- 3D分解低秩张量: 使用这种张量结构来表示3D场景的密度和颜色场,并通过MLP(多层感知器)进行解码。
- 分离的分量式卷积: 提出了一种高效的3D卷积方法,通过在分解的低秩张量的不同分量上分别应用1D和2D高斯滤波器,实现了对辐射场频谱的控制,同时保持了计算效率。
- 鲁棒性增强: 通过平滑2D监督图像、随机缩放核参数和边缘引导损失掩模等技术,增强了优化过程的鲁棒性。

应用场景:
- 高质量新视角合成: 在需要生成高质量3D场景新视角的应用中,如电影制作、游戏开发和虚拟现实(VR)。
- 相机姿态估计: 在需要精确相机姿态估计的场景中,如结构从运动(Structure-from-Motion, SfM)和增强现实(AR)应用。
- 内存和计算效率优化: 在资源受限的环境中,如移动设备或嵌入式系统,需要高效的场景表示和渲染技术。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











