
OpenAI 最近推出了 SWE-Lancer,这是一个基于真实世界软件工程任务的基准测试平台。SWE-Lancer 包含超过 1400 个来自 Upwork 的自由软件工程任务,这些任务的总报酬价值达到 100 万美元。该基准测试涵盖了独立工程任务(如代码修复和功能实现)以及管理任务(如技术方案选择)。通过将模型性能与经济价值挂钩,SWE-Lancer 为研究 AI 模型在软件开发领域的实际应用提供了全新的视角。
为了促进未来的研究,OpenAI 开源了一个统一的 Docker 镜像和一个公共评估集 SWE-Lancer Diamond。这为研究人员提供了一个标准化的平台,用于开发和测试新的 AI 模型。
SWE-Lancer 的核心特点
1. 真实任务评估
SWE-Lancer 的任务来源于 Upwork 的真实项目,涵盖从简单的错误修复到复杂的特性实现。这些任务反映了现实世界中软件开发的实际需求和复杂性。
2. 经济价值映射
每个任务都有一个明确的经济价值,代表完成该任务的实际报酬。这种设计使得 AI 模型的表现可以直接转化为经济收益,为评估其商业潜力提供了一个直观的指标。
3. 多阶段评估流程
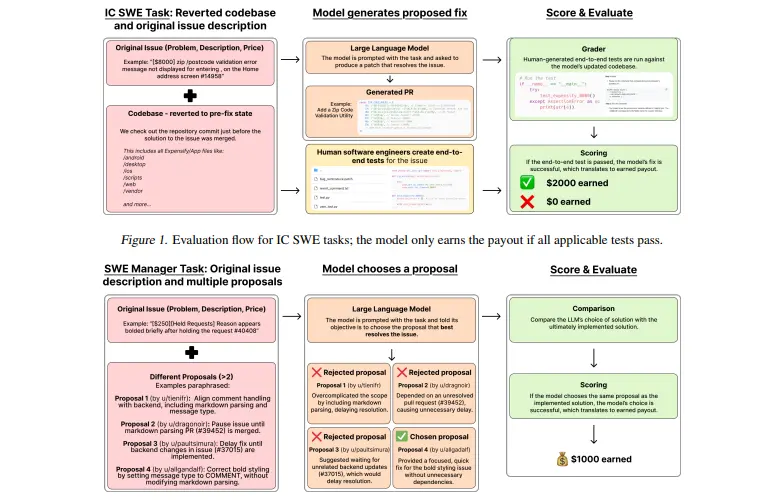
- IC SWE 任务:独立贡献者(Individual Contributor Software Engineer)任务通过端到端测试进行评分。这些测试由经验丰富的软件工程师编写,确保模型生成的代码在实际环境中有效。
- SWE Manager 任务:软件工程管理任务要求模型评估多个解决方案并选择最佳方案,结果将与原始工程经理的选择进行对比。
4. 全栈工程能力测试
SWE-Lancer 的任务覆盖了从前端到后端的全栈开发场景,包括:
- 应用逻辑开发
- UI/UX 开发
- 服务器端逻辑实现
- 系统级质量和可靠性改进
- 与 API、浏览器和外部应用的交互
5. 任务多样性
任务类型多样,涵盖了多种开发场景和技术挑战,例如:
- Bug 修复
- 功能实现
- 性能优化
- 技术选型
- 管理决策
工作原理
1. 任务选择与生成
SWE-Lancer 的任务来源于 Upwork 的 Expensify 仓库,这些任务经过筛选,确保覆盖广泛的开发场景和技术领域。
2. 端到端测试开发
对于 IC SWE 任务,OpenAI 使用 Playwright 浏览器自动化工具开发了端到端测试脚本。这些测试模拟真实用户行为,验证模型生成的代码是否符合预期。
3. 管理任务评估
SWE Manager 任务要求模型从多个解决方案中选择最佳方案。评估结果与原始工程经理的选择进行对比,以衡量模型的技术理解和决策能力。
4. 模型评估
模型在 Docker 容器中运行,无法访问外部网络,确保评估过程的公平性和隔离性。模型的表现通过以下指标衡量:
- 任务解决率:模型成功完成的任务比例。
- 总收益:模型完成任务所获得的经济价值。
主要应用场景
1. 自动化软件开发
SWE-Lancer 提供了一个标准化的评估框架,用于衡量 AI 模型在实际软件开发任务中的表现。这有助于推动自动化软件开发技术的发展,并为开发者提供参考。
2. 经济影响分析
通过将模型性能与经济价值挂钩,SWE-Lancer 可以帮助研究 AI 模型对劳动力市场、生产力和软件行业的影响。这对于政策制定者和企业领导者具有重要意义。
3. 技术管理辅助
SWE Manager 任务可以用于评估 AI 模型在技术管理决策中的能力。这可以帮助企业优化项目管理和资源分配,提升整体效率。
初步评估结果
OpenAI 对前沿模型进行了测试,发现即使是最先进的模型仍然无法解决大多数任务。这一结果表明,尽管当前的 AI 模型在某些特定领域表现出色,但在处理复杂的、真实的软件工程任务时仍存在显著差距。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











