
开发当代多模态大语言模型(MLLMs)的标准做法是将视觉编码器的特征输入到大型语言模型(LLM)中,并通过自然语言监督进行训练。然而,这种方法存在一个潜在的局限性:仅依赖自然语言监督对于MLLM的视觉理解能力是次优的。为了克服这一问题,佐治亚理工学院和微软雷德蒙德研究院的研究人员提出了OLA-VLM(Optimizing Language-Adaptive Visual Embeddings for Vision-Language Models),这是第一种从一组目标视觉表示中提取知识到LLM隐藏表示的方法,它通过辅助嵌入蒸馏(auxiliary embedding distillation)来增强模型的视觉理解能力。
- 项目主页:https://praeclarumjj3.github.io/ola_vlm
- GitHub:https://github.com/SHI-Labs/OLA-VLM
- 模型:https://huggingface.co/models?search=OLA-VLM
例如,我们有一个多模态大语言模型,它能够处理图像和文本数据。在没有OLA-VLM的情况下,模型可能在理解图像内容和关联文本信息方面存在局限性。例如,如果给模型一张图片和一个问题:“图片中的球是什么颜色的?”模型可能无法准确地从图片中提取视觉信息来回答问题。OLA-VLM通过优化模型的内部表示来改善这一点,使得模型能够更准确地理解和回答关于视觉内容的问题。
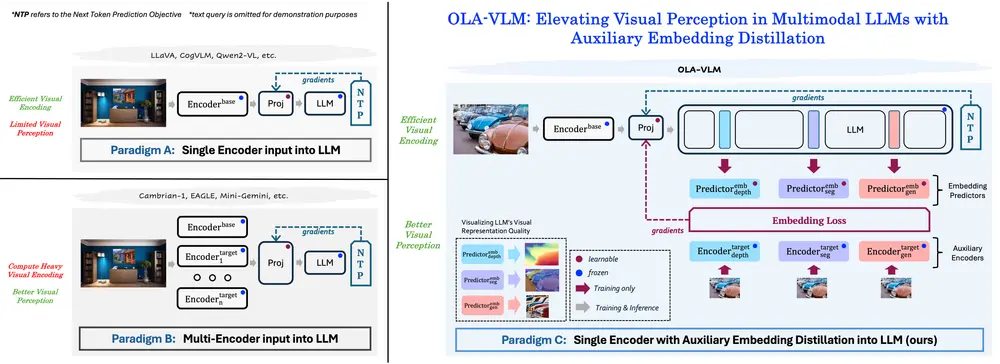
OLA-VLM的核心创新
1. 耦合优化:预测视觉嵌入与下一个文本标记
在MLLMs的预训练阶段,OLA-VLM引入了一种新的目标公式,即耦合优化。具体来说:
- 视觉嵌入预测:模型不仅需要预测下一个文本标记,还需要预测给定图像的视觉嵌入。这种双任务设置使得模型在学习语言生成的同时,也能够更好地理解和表示视觉信息。
- 耦合优化:通过同时优化这两个任务,OLA-VLM能够在视觉和语言之间建立更强的关联,从而提高模型的多模态理解能力。
2. 视觉表示质量与下游性能的正相关关系
研究人员通过实验发现,仅通过自然语言监督训练的MLLMs,其视觉表示的质量与其下游任务的性能之间存在正相关关系。换句话说,视觉表示越准确,模型在下游任务中的表现越好。这一发现为优化视觉嵌入提供了理论支持,表明通过改进视觉表示,可以显著提升MLLM的整体性能。
3. 嵌入优化带来的表示质量提升
在对OLA-VLM进行探测时,研究人员观察到,由于嵌入优化,模型的视觉表示质量得到了显著提升。具体来说:
- 更丰富的视觉特征:通过优化视觉嵌入,模型能够捕捉到更多细节和上下文信息,从而生成更加准确的视觉表示。
- 更好的跨模态对齐:优化后的视觉嵌入与语言表示之间的对齐更加紧密,使得模型在处理复杂的多模态任务时表现出色。
工作原理:
OLA-VLM通过以下步骤工作:
- 预训练阶段:在这一阶段,模型通过最小化嵌入损失和下一个文本标记预测损失函数来优化目标视觉编码器的特征表示。
- 嵌入预测架构:使用嵌入预测架构来比较目标编码器特征和映射的源编码器特征,并使用训练好的预测器进行比较。
- 特殊标记:在模型的输入序列中加入富含目标特定信息的特殊标记,以增强模型处理目标信息友好查询的能力。
实验结果
1. 优于单编码器和多编码器基线
实验结果表明,OLA-VLM在多个基准测试中显著优于单编码器和多编码器基线模型。具体来说:
- 平均性能提升:在各种基准测试中,OLA-VLM平均提高了**2.5%**的性能。
- 深度任务中的显著提升:特别是在CV-Bench的深度任务中,OLA-VLM的表现尤为突出,性能提升了8.7%。这表明OLA-VLM在处理复杂视觉任务时具有明显的优势。
2. 显式特征输入的优越性
OLA-VLM的成功还证明了显式地将相应特征输入LLM的重要性。与传统的单编码器或多编码器模型相比,OLA-VLM通过优化视觉嵌入,能够更好地利用视觉信息,从而在多模态任务中取得更好的表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











