RotorQuant 是一项突破性的 KV 缓存量化技术,旨在解决大型语言模型(LLM)在长上下文推理中的显存瓶颈。通过引入块对角旋转(Block-Diagonal Rotation)替代传统的蝴蝶网络(Butterfly Network),RotorQuant 在保持甚至提升模型精度(PPL)的同时,实现了惊人的推理加速和极致的参数效率。
- 项目主页:https://www.scrya.com/rotorquant/
- GitHub:https://github.com/scrya-com/rotorquant
与 Google 的 TurboQuant 相比,RotorQuant 不仅解码速度快 28%,预填充速度快 5.3 倍,且所需参数量仅为前者的 1/44。它已集成于 llama.cpp,支持 NVIDIA GPU 和 Apple Silicon,是让大模型在消费级硬件上流畅运行长文本的关键技术。
核心突破:为什么 RotorQuant 更快?
传统量化方法(如 TurboQuant)使用全局的沃尔什-阿达玛变换(WHT),计算复杂度高且存在元素间依赖。RotorQuant 的核心洞察是:KV 缓存向量存在于低秩流形上,无需满秩变换,小的正交块旋转足以解相关数据。
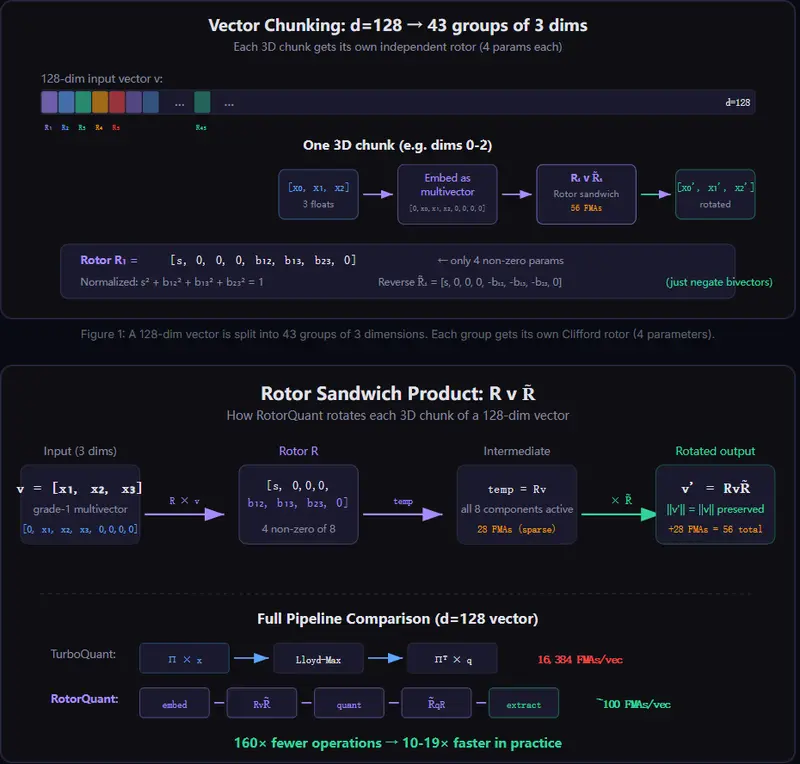
1. 绕过蝴蝶网络:从 O(d log d) 到 O(d)
- TurboQuant:应用 $d \times d$ 的 WHT 变换,需要 $\log_2(d)$ 级蝴蝶网络,计算量大且难以完全并行。
- RotorQuant (Planar/Iso):对每对或每组维度应用独立的 2D Givens 旋转或 4D 四元数旋转。
- 计算量剧减:FMAs(乘加运算)从 16,384 降至 256 (Planar) 或 512 (Iso)。
- 完全并行:无元素间依赖,硬件利用率极高。
- 参数极少:仅需 128 个旋转参数,而 TurboQuant 需要 16,384 个。
2. 延迟量化策略
- 预填充阶段零开销:K 缓存在预填充(Prompt Processing)期间保持 FP16 格式,完全消除旋转和量化开销。
- 解码阶段即时量化:新生成的 Token 在插入缓存时立即量化。
- 结果:在
llama.cpp中,这种混合策略使得解码速度甚至超过了 FP16 基线(因为 Flash Attention 中减少了内存带宽压力,且无数量化 overhead)。
3. V 缓存的逆旋转修复
- TurboQuant 利用 Hadamard 变换的自消除特性,无需显式逆旋转。
- RotorQuant 发现 V 缓存反量化必须应用正向旋转的逆(逆 Givens 或逆四元数)。团队通过补丁(
6e5a4aa)修复了这一点,将 PPL 从灾难性的 15,369 拉回至正常的 7.05。
性能基准:碾压 TurboQuant
测试环境:Llama 3.1 8B Instruct,对称 3-bit K+V 压缩,RTX 5090。
| 配置 (K/V) | 解码速度 (tok/s) | 预填充速度 (tok/s) | PPL (Wiki-2) | 压缩率 | 备注 |
|---|---|---|---|---|---|
| FP16 / FP16 | 140 | 6,156 | 6.63 | 1x | 基线 |
| Planar3 / Planar3 | 119 | 3,822 | 7.05 | 10.3x | 综合最佳 |
| Iso3 / Iso3 | 118 | 3,397 | 6.91 | 10.3x | 精度最高 |
| Turbo3 / Turbo3 | 93 | 722 | 7.07 | 10.3x | Google 方案 |
| Planar3 / FP16 | 134 | — | ~6.63 | 5.1x | 仅压缩 K |
关键对比 (vs TurboQuant)
- 速度:解码快 28% (119 vs 93 tok/s),预填充快 5.3 倍 (3,822 vs 722 tok/s)。
- 精度:PPL 更低 (6.91/7.05 vs 7.07),意味着回答质量更高。
- 效率:参数量减少 44 倍 (128 vs 16,384),极大地降低了存储和加载开销。
显存节省:长文本的救星
在 3-bit 对称压缩(10.3 倍压缩率)下,KV 缓存占用的显存大幅降低:
| 上下文长度 | FP16 KV 占用 | RotorQuant 占用 | 节省显存 |
|---|---|---|---|
| 8K | 288 MB | 28 MB | 260 MB |
| 32K | 1,152 MB | 112 MB | 1.04 GB |
| 128K | 4,608 MB | 447 MB | 4.16 GB |
这使得在消费级显卡(如 RTX 4090/5090 或 Mac M系列)上运行 128K+ 超长上下文成为可能,且不会因显存溢出而崩溃。
技术演进路线图
RotorQuant 的发展体现了“用代数丰富性换取速度”的设计哲学,且事实证明更简单的旋转效果反而更好:
| 方法 | 旋转类型 | 组大小 | FMAs (d=128) | 参数 | 状态 |
|---|---|---|---|---|---|
| RotorQuant (原始) | Cl(3,0) 转子三明治 | 3 | ~2,400 | 372 | 研究 (Triton) |
| IsoQuant | 4D 四元数 | 4 | 512 | 128 | 生产 (llama.cpp) |
| PlanarQuant | 2D Givens 旋转 | 2 | 256 | 128 | 生产 (llama.cpp) |
| TurboQuant | WHT 蝴蝶网络 | 128 | 16,384 | 16,384 | 生产 (llama.cpp) |
- PlanarQuant 和 IsoQuant 由社区开发者 @ParaMind2025 基于块对角旋转思想实现,并已合并入主流推理框架。
应用场景
- 移动端/边缘设备大模型:在 iPhone (M4/M3) 或 Android 手机上运行 7B-13B 模型,显著降低内存峰值,提升续航。
- 长文档分析与 RAG:处理数百页 PDF 或长篇代码库时,保持极高的预填充速度和低显存占用。
- 本地私有化部署:在显存有限的个人电脑上部署高精度模型,无需昂贵的 A100/H100 集群。
- 高并发推理服务:更高的解码吞吐量意味着单卡能支持更多并发用户,降低服务端成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...