
新AI会诱发精神病吗?《柳叶刀》最新研究:聊天机器人或放大易感人群妄想
随着人工智能深度融入日常生活,一项发表于《柳叶刀精神病学》(The Lancet Psychiatry)的最新综述研究引发了学界与公众的广泛关注。该研究首次系统性地探讨了AI聊天机器人与“妄想思维”之...

新奇安信发布“龙虾安全伴侣”:国内首份 OpenClaw 威胁报告揭示技能爆炸背后的隐忧
3月16日,奇安信在北京召开“龙虾安全产品发布会”,直面AI智能体OpenClaw(业内昵称“龙虾”)爆发式增长带来的安全挑战。会上,奇安信发布了国内首份《OpenClaw生态威胁分析报告》,并正式推...

新以 Token 为核心重构 AI 战略!阿里巴巴成立“Alibaba Token Hub”事业群, 悟空事业部首度曝光
2026年3月16日,阿里巴巴集团内部发出一封重磅邮件,宣布正式成立 Alibaba Token Hub(简称 ATH)事业群。这一新组织由阿里巴巴 CEO 吴泳铭直接负责,标志着阿里在 AGI(通用...

新智谱 AI 重磅发布 GLM-5-Turbo:专为 OpenClaw“龙虾”打造的极速智能体引擎
在 AI 智能体(Agent)从“对话”走向“执行”的关键时刻,智谱 AI 正式推出了 GLM-5-Turbo —— 一款专为 OpenClaw(俗称“龙虾”)场景深度优化的基座模型。 国内版: 文档...
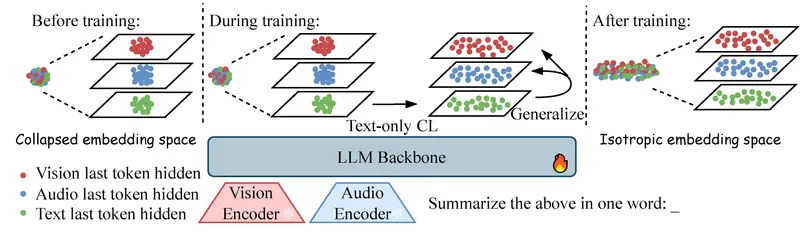
新LCO-EMB:阿里达摩院新突破,用“纯文字”训练出全能多模态AI
想象一下,你只需要教 AI 读书(文字),它就能无师自通地看懂图片、听懂音频、理解视频。这听起来像魔法,但阿里达摩院最新推出的 LCO-EMB(Language-Centric Omnimodal E...
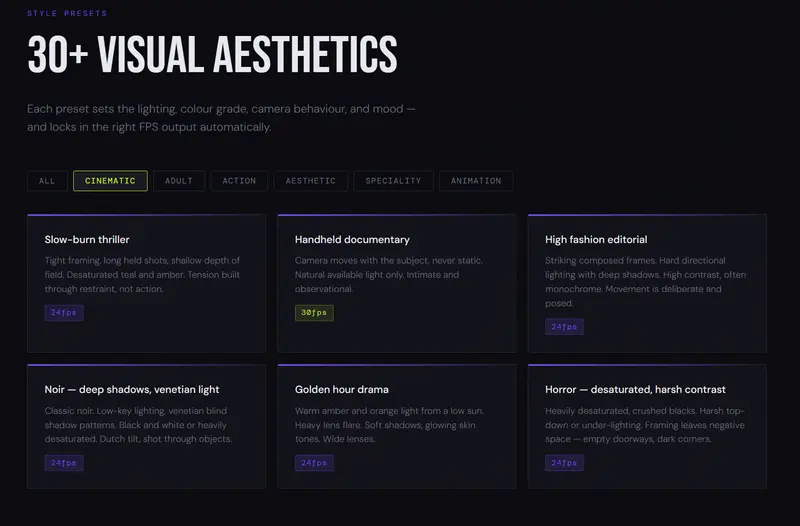
新LTX2EasyPrompt-LD:用简单英文,一键生成LTX-2电影级视频提示词
LTX2EasyPrompt-LD 是一款专为 ComfyUI 打造的自定义节点工具,核心价值在于降低LTX-2视频生成的提示词创作门槛——你只需输入简单的英文描述(比如“夕阳下海边的奔跑镜头”),它...
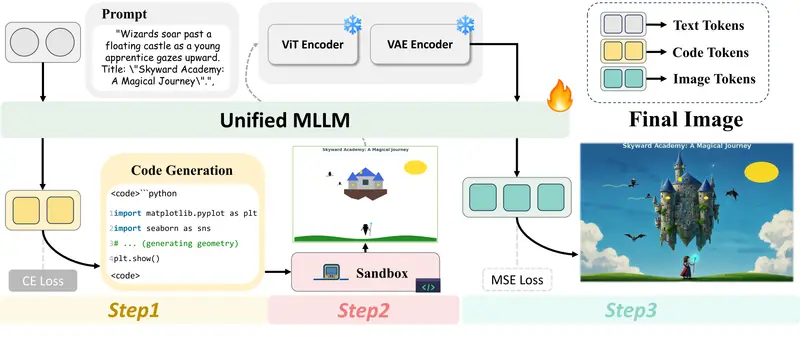
新CoCo:让 AI 像程序员一样“写代码画图”,彻底解决文生图的文字与布局难题
如果你曾让 AI 画一张“带有具体数据的饼图”、“排版精美的餐厅菜单”或“标注了坐标轴的数学函数图”,结果大概率会失望:文字变成乱码、布局歪七扭八、数据完全错误。 这是因为现有的文生图模型依赖模糊的自...
新GreenBoost:Linux 下的“显存无限”魔法,让 12GB 显卡跑 32GB 大模型
你是否拥有一张消费级显卡(如 RTX 4070/5070 12GB),却眼馋那些需要 24GB 甚至 48GB 显存才能运行的超大语言模型(如 GLM-4-Flash, Llama-3-70B)? 传...
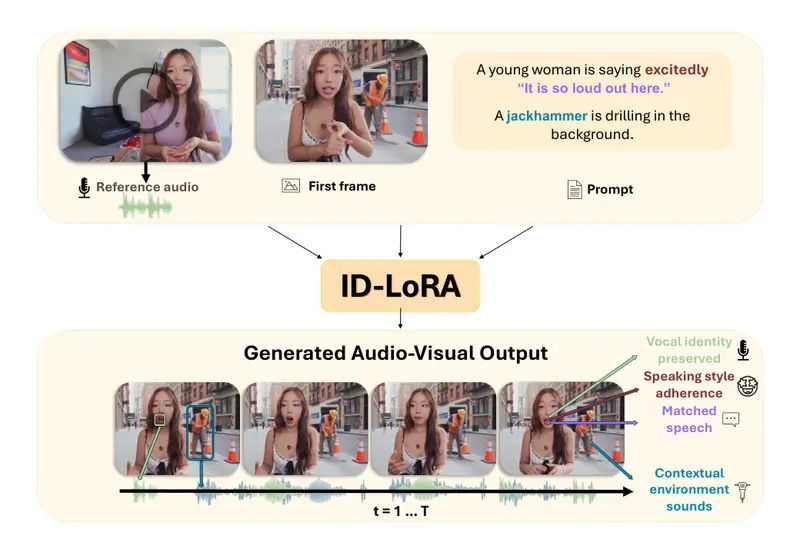
新ID-LoRA:让AI同时“克隆”你的长相和声音,还能配合场景表演
你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能? 这正是特拉维夫大学等研究机构最新发布的 ID...
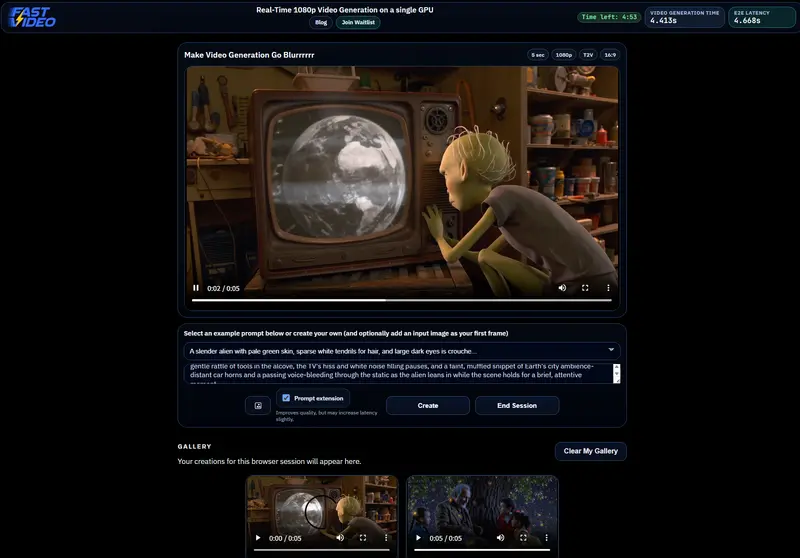
新FastVideo 里程碑:单卡 4.5 秒生成 1080p 视频,AI 视频创作进入“实时交互”时代
“灵感稍纵即逝,但生成却要等几分钟。” 这是当前 AI 视频创作者最大的痛点。当生成速度慢于构思速度时,创意的反馈循环就被彻底打破了。 FastVideo 团队宣布了一项突破性进展:他们成功将开源模型...





