
想象一下,你只需要教 AI 读书(文字),它就能无师自通地看懂图片、听懂音频、理解视频。这听起来像魔法,但阿里达摩院最新推出的 LCO-EMB(Language-Centric Omnimodal Embedding,语言中心全模态嵌入)技术,正在将这一愿景变为现实。
- GitHub:https://github.com/LCO-Embedding/LCO-Embedding
- 模型:https://huggingface.co/collections/LCO-Embedding/lco-embedding-collections
这项研究解决了一个长期困扰 AI 界的难题:如何让 AI 高效、精准地理解和匹配不同模态的内容(图文、音视频),同时大幅降低对海量配对数据的依赖?
核心突破:以语言为锚,四两拨千斤
传统的跨模态模型(如 CLIP)需要数亿级的“图片 - 文字”配对数据进行暴力训练,成本高且难以处理复杂场景(如文档布局、多语言)。
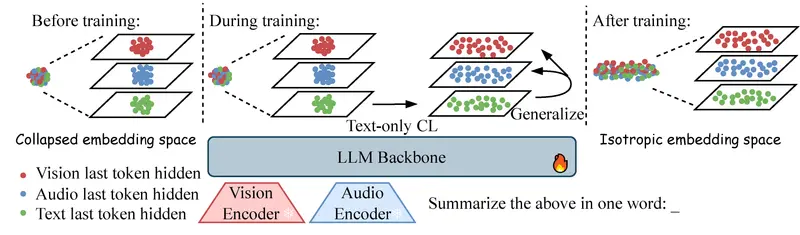
LCO-EMB 提出了一个颠覆性的范式:“语言中心主义”。
研究发现,多模态大语言模型(MLLM)在生成预训练阶段,已经隐式地将所有模态(图、文、音、视)映射到了一个以语言为核心的统一语义空间中。
- 以前:我们需要费力地把图片和文字强行拉在一起(对比学习)。
- 现在:我们只需要优化这个空间中的语言部分,其他模态的表征能力就会“水涨船高”,自动变强。
五大颠覆性功能
- 📉 数据需求暴跌 21 倍
- 传统 SOTA 模型(如 GME)需要约 800 万 对多模态数据。
- LCO-EMB 仅需 37 万 对数据(其中 27 万是纯文字!),效果却更优。这意味着训练成本和时间呈指数级下降。
- 📝 纯文字训练,解锁图像理解
- 这是最神奇的一点:基础版 LCO-EMB 仅使用文字相似性数据集训练,却在图像检索和理解任务上表现优异。
- 原理:只要模型学会了更精准的语言逻辑和语义关联,它就能通过预训练中建立的“隐性桥梁”,将这些能力迁移到图像理解上。
- 📄 文档理解专家
- 特别擅长处理包含复杂布局、图表、混合排版的视觉文档(PDF、扫描件、海报)。它能精准提取关键信息,远超通用模型。
- 🌍 真正的多语言跨模态
- 支持用英文查询检索泰语、越南语等非英语文档。
- 在低资源语言场景下,表现比商业巨头模型(如 Voyage-Multimodal-3)高出 15% 以上。
- ⚖️ 理解与生成兼得
- 很多模型为了优化“检索/匹配”能力,会牺牲“生成/描述”能力。
- LCO-EMB 采用 LoRA 轻量微调,完美保留了模型原有的看图说话、问答等生成能力,实现“一鱼两吃”。
工作原理:激活沉睡的“翻译官”
LCO-EMB 的流程可以比喻为唤醒一位精通多门语言的翻译官:
- 发现隐式对齐:确认模型在预训练时,已经把图、音、视都“翻译”成了内部的语言向量。
- 语言专项特训:只拿出模型的语言解码器,用纯文字数据(如句子对)进行对比学习微调。这就像专门训练翻译官的“母语理解力”。
- 能力泛化:当语言理解力提升后,模型内部统一的语义空间被激活,图像、音频的理解力随之自动提升。
- 可选校准:如有需要,再喂入少量多模态数据(约 9.4 万对)进行微调,进一步校准特定任务。
实测表现:小数据打败大数据
在权威基准测试 MIEB-Lite(51 项任务)中:
- 效率碾压:LCO-EMB 仅用 37 万 数据,超越了使用 800 万 数据的 GME 模型。
- 多语言无敌:在跨语言检索任务中,领先商业模型 15%+。
- 文档理解:仅用文字训练的版本,性能竟与专门优化的文档模型持平。
- 训练速度:相比传统 CLIP 风格方法,GPU 耗时减少 50 倍以上。
重要发现:生成 - 表征缩放定律 (GRSL)
研究团队还发现了一个黄金定律:模型的生成能力越强,其表征(理解/匹配)能力也越强。
- 在低资源语言(如泰语、老挝语)测试中,先强化模型的生成能力(让它能更准地识别和写出这些语言),其检索性能会显著提升。
- 这为未来 AI 发展指明了新方向:想让它更懂世界?先让它更会表达!
对普通人的价值
- 搜索革命:以后找文件、找图片、找视频,只需描述你的意图(甚至用中文搜外文资料),AI 都能精准命中,不再依赖关键词匹配。
- 中小企业福音:不再需要海量数据和昂贵算力才能训练好用的多模态模型,AI 应用门槛大幅降低。
- 全能助手:未来的 AI 将不再是割裂的“搜索工具”或“聊天机器人”,而是既能精准理解你的需求(检索),又能基于理解创作内容(生成)的统一智能体。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











