Visual Story-Writing
Visual Story-Writing 并非要取代传统写作,而是提供一种更高维度的编辑方式。它让我们意识到: 写作不仅是“写”,更是“组织”。 当故事可以被“看见”和“拖动”,创作的边界也随之扩展。这或许就是下一代写作工具的模样—— 不再是空白文档,而是一个可交互的叙事宇宙。
Clarifai宣布推出其全新自研的 推理引擎(Inference Engine),专为应对当前高负载、多步骤的 AI 推理任务而设计。该公司声称,该引擎可在相同硬件条件下,实现 推理速度提升一倍,同时将单位计算成本 降低 40%。
AI 平台 Clarifai 近日宣布推出其全新自研的 推理引擎(Inference Engine),专为应对当前高负载、多步骤的 AI 推理任务而设计。该公司声称,该引擎可在相同硬件条件下,实现 推理速度提升一倍,同时将单位计算成本 降低 40%。

这一进展在 AI 基础设施面临巨大压力的背景下尤为关键——随着“代理式 AI”(AI agents)和复杂推理模型的兴起,单次请求可能触发数十甚至上百次模型调用,导致 GPU 资源消耗激增、延迟上升、成本失控。
Clarifai 推理引擎并非依赖单一技术突破,而是通过一系列软硬件协同优化实现性能跃升,涵盖:
Clarifai 创始人兼 CEO Matthew Zeiler 表示:“这是从内核到系统层面的一整套优化。本质上,你可以在不更换 GPU 的情况下,获得更高的吞吐量。”
该引擎支持多种模型架构和云环境,兼容主流大语言模型(LLM)、视觉模型(LVM)以及 RAG、Agent 工作流等现代 AI 架构,旨在帮助开发者在标准 GPU 上实现接近专用芯片(如 ASIC)的推理效率。
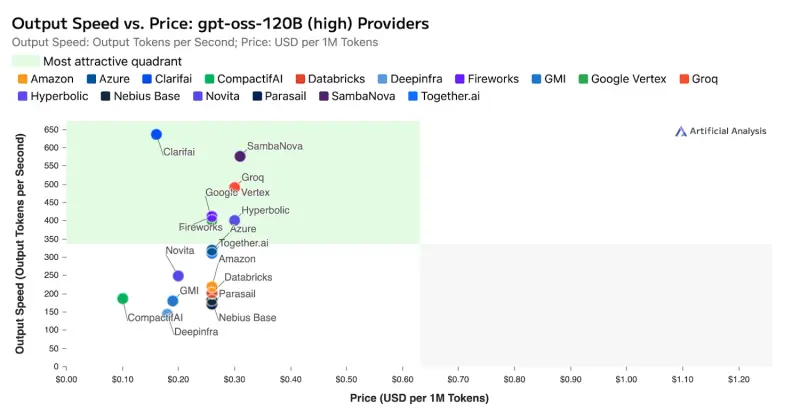
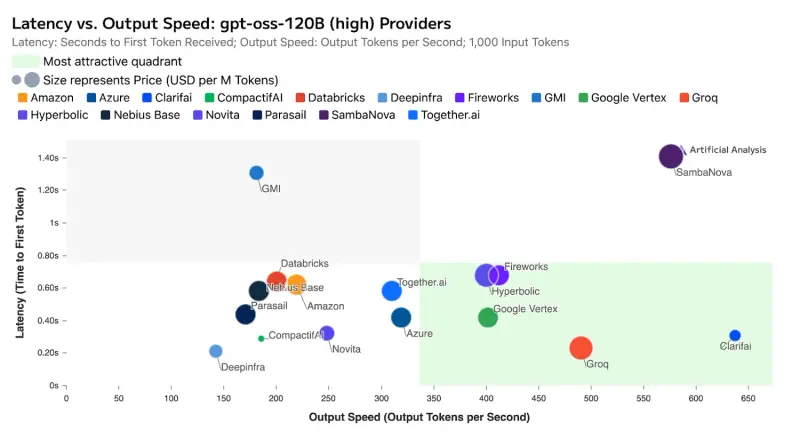
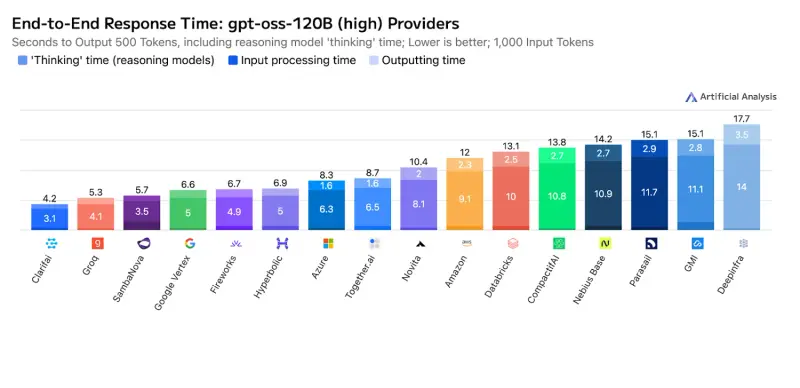
性能数据已由独立评测机构 Artificial Analysis 通过基准测试验证。测试基于开源大模型 gpt-oss-120B,结果显示:
这不仅刷新了基于 GPU 的推理服务性能记录,更值得注意的是:Clarifai 在部分指标上超越了使用专用非 GPU 加速器的竞争对手,首次证明通用 GPU 架构在经过深度优化后,可与定制化硬件一较高下。
传统推理通常是一次输入、一次响应,而代理式 AI 往往需要多轮思考、工具调用、自我修正,形成链式推理流程。这类工作负载对系统提出了更高要求:高吞吐、低延迟、低成本、持续稳定。
Clarifai 推理引擎特别针对此类场景进行了优化。其平台具备自适应能力,能从历史工作负载中学习,动态调整资源分配与执行策略,长期运行中性能持续提升,尤其适合重复性高的自动化任务。
Zeiler 指出:“代理式 AI 正在快速消耗 Token。要让这些应用真正落地,必须解决成本和响应速度的问题。”他认为,尽管行业正投入数千亿美元建设新数据中心(如 OpenAI 规划的万亿美元基建),但软件与算法层面的创新仍有巨大空间。
“我们还没走到算力优化的终点。像 Clarifai 推理引擎这样的技术,能让好模型跑得更远。”
从即日起,企业客户和开发者可与 Clarifai 团队合作,将其推理优化技术应用于自有模型。无论是托管在云端、本地部署,还是混合环境,均可集成该引擎以提升性能与经济性。
Clarifai 强调,其目标是提供不绑定特定硬件供应商的解决方案,帮助组织摆脱对昂贵专用芯片的依赖,在标准 GPU 基础设施上实现高效 AI 运营。
成立于 2013 年,Clarifai 最初以计算机视觉 API 起家,现已发展为全栈 AI 平台提供商。其平台支持 LLM、RAG、自动标注、高并发推理等现代 AI 功能,已在全球 170 个国家服务超过 50 万用户,支撑构建了逾 150 万个 AI 模型。