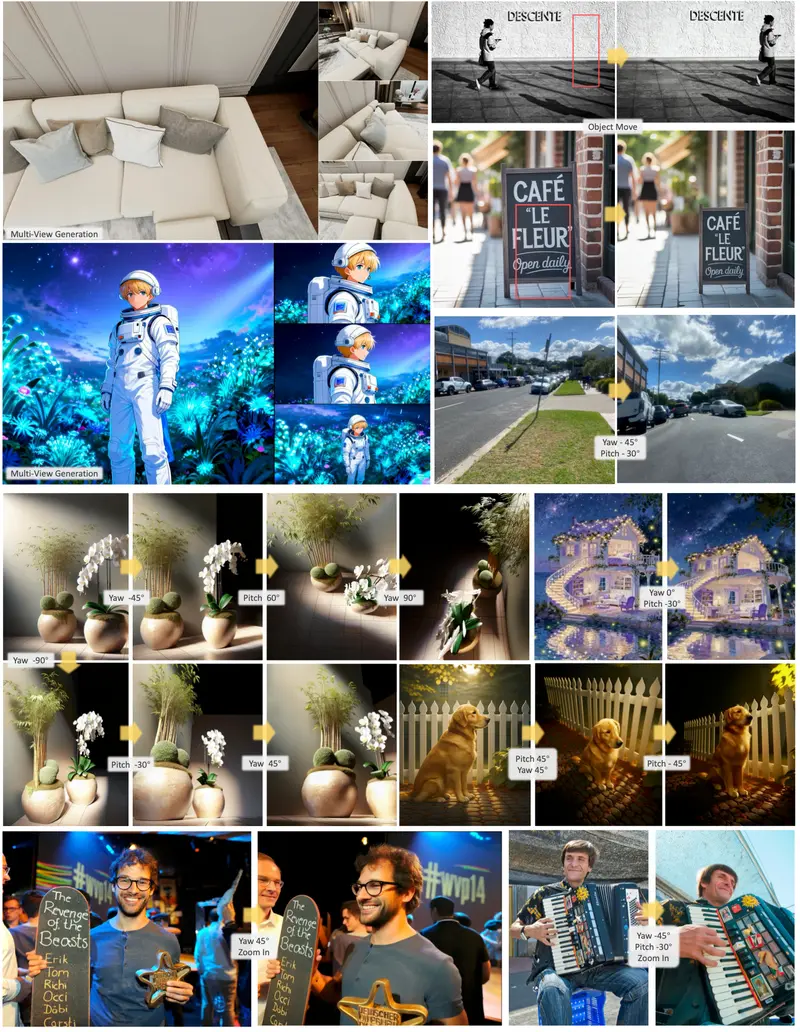
“灵感稍纵即逝,但生成却要等几分钟。” 这是当前 AI 视频创作者最大的痛点。当生成速度慢于构思速度时,创意的反馈循环就被彻底打破了。
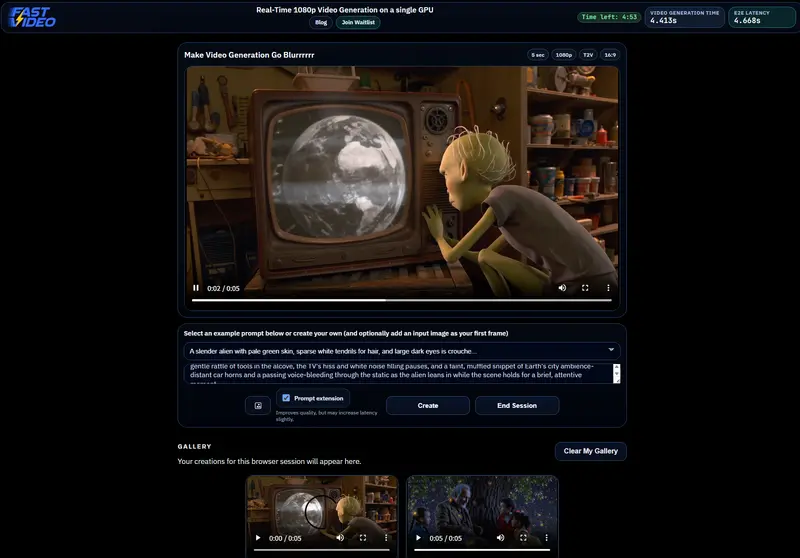
FastVideo 团队宣布了一项突破性进展:他们成功将开源模型 LTX-2.3 优化为极速推理引擎,在单张 NVIDIA B200 GPU 上,实现了 5 秒时长、1080p 分辨率、带音频 的视频生成,端到端延迟仅为 ~4.5 秒。
- 官方说明:https://haoailab.com/blogs/fastvideo_realtime_1080p
- GitHub:https://github.com/hao-ai-lab/FastVideo
- Demo:https://1080p.fastvideo.org
这意味着,AI 视频生成终于从“批量处理任务”进化为“交互式创作工具”。
核心突破:为什么是 4.5 秒?
在此之前,即使是 Google 的 Veo-3 Fast 生成 8 秒视频也需要约 55 秒,且大多局限于 480p/720p 无音频。1080p 是实用化的分水岭,但计算量呈指数级增长。FastVideo 通过全栈优化,将延迟降低了 3.9 倍,关键在于以下四大技术支柱:
1. 专为 Blackwell 架构打造的注意力机制
- 瓶颈:视频生成的计算重担主要在 3D 时空注意力机制。
- 解决方案:FastVideo 集成了专为 NVIDIA SM100/SM103 架构(Blackwell 核心)定制的注意力内核。这使得 B200/B300 GPU 能以前所未有的效率处理海量令牌交换,维持 1080p 下的高帧率生成。
2. 激进的 NVFP4 低精度推理
- 瓶颈:传统 BF16 精度限制了吞吐量。
- 解决方案:充分利用 Blackwell 芯片原生支持的 NVFP4 (4-bit Floating Point) 数据类型。
- FastVideo 在 DiT (Diffusion Transformer) 中实现了 NVFP4 量化线性层。
- 结果:理论吞吐量大幅提升,同时保持了输出质量几乎无损。这是实现单卡实时的关键。
3. 端到端图与内核融合
- 瓶颈:延迟不仅来自模型去噪,还来自提示词编码、潜在空间准备、解码等周边环节。
- 解决方案:
- 应用激进的内核融合 (Kernel Fusion) 技术,将多个小算子合并为大算子,减少内存读写开销。
- 将整个流水线(Prompt -> Latent -> Denoise -> Decode)视为一个整体进行图级别优化,消除所有中间冗余。
4. 系统级 I/O 优化
- 瓶颈:高分辨率视频的帧处理和音频合成往往成为隐藏的性能杀手。
- 解决方案:
- 利用 FastVideo 的性能分析工具,识别并消除了进程间通信 (IPC) 开销。
- 构建了针对目标 CPU 优化的 ffmpeg 版本,确保媒体编码和存储不再拖后腿。
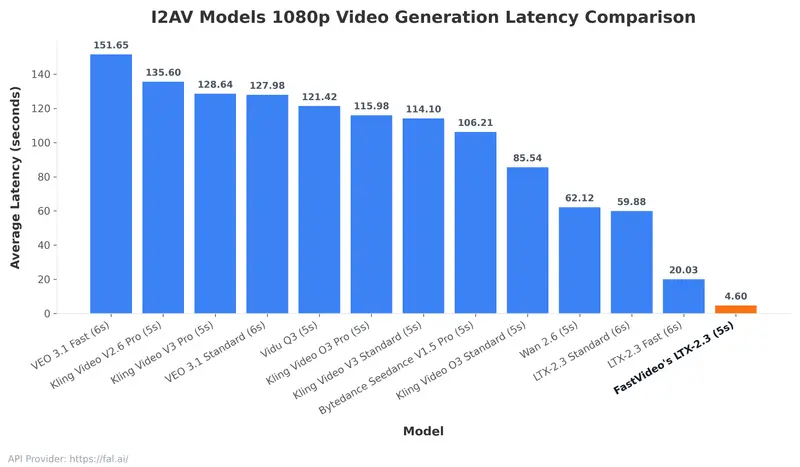
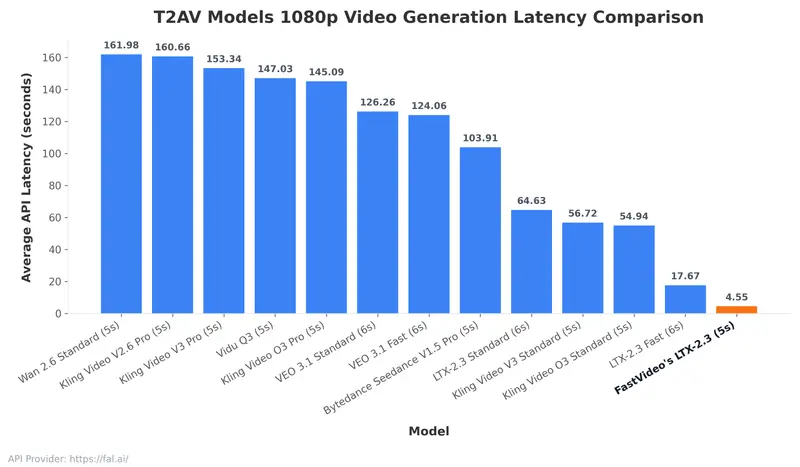
行业意义:创意工作流的革命
这项技术的落地不仅仅是速度的提升,更是创作范式的转变:
- ✅ 真正的实时反馈:创作者可以像调整参数一样实时看到视频变化。想换个风格?4.5 秒后就能看到结果。想微调动作?再等 4.5 秒。
- ✅ 成本大幅降低:单卡即可部署,无需复杂的多卡序列并行(Sequence Parallelism)或多机集群,极大降低了运营成本和部署门槛。
- ✅ 新应用场景爆发:
- 交互式叙事:观众的选择能即时生成后续剧情。
- 实时广告构思:营销团队可在会议中现场生成多个版本的广告素材。
- 本地化部署:随着硬件下放,未来在消费级显卡上实现 <5 秒生成指日可待。
现状与展望
- 演示体验:FastVideo 已上线公开演示(基于半个 GB200 NVL72 集群,负载均衡),用户可免费试用感受极速生成。
- 开源计划:相关优化代码将在不久的将来合并至 FastVideo 主分支,造福整个开源社区。
- 未来目标:团队正致力于将这些优化移植到消费级显卡,让每个人都能在自己的电脑上运行“实时视频生成器”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...