在企业级 AI 应用中,长上下文处理一直是个昂贵的痛点。分析数百页的法律合同、维护跨天的客户对话、或运行自主编码智能体时,KV 缓存(Key-Value Cache)的内存占用往往成为瓶颈,单个请求即可消耗数 GB 显存,严重限制并发能力和响应速度。
- GitHub:https://github.com/adamzweiger/compaction
- 论文:https://arxiv.org/abs/2602.16284
现在,麻省理工学院(MIT)的研究团队带来了一项颠覆性解决方案:Attention Matching。这项新技术能够将 KV 缓存压缩高达 50 倍,同时保持几乎零精度损失,且计算速度比现有最先进方法快几个数量级。
核心痛点:KV 缓存的“内存墙”
大语言模型(LLM)通过存储已处理词元的键值对(KV 缓存)来避免重复计算,从而实现流畅的多轮对话。然而:
- 线性增长:上下文越长,KV 缓存越大,内存占用呈线性甚至超线性增长。
- 现有方案局限:
- 简单丢弃:直接删除旧上下文,导致模型“失忆”。
- 文本摘要:用摘要替换原文,信息丢失严重,在复杂任务(如医疗记录分析)中表现甚至不如无上下文基线。
- 梯度优化(如 Cartridges):虽能高压缩,但需数小时 GPU 训练才能压缩单个上下文,无法用于实时场景。
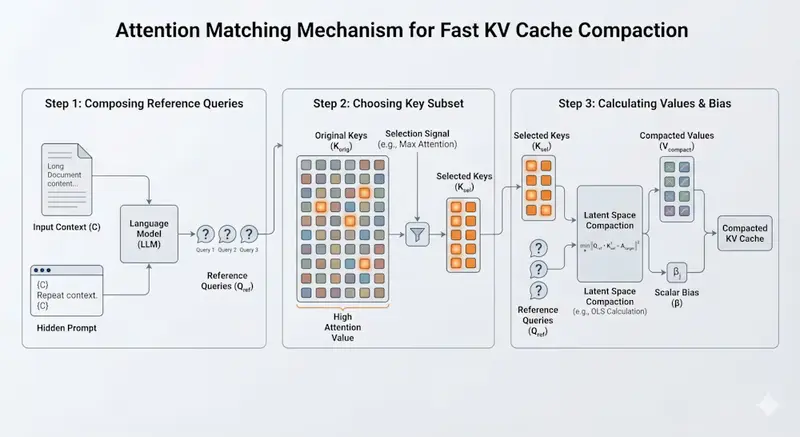
技术原理:用代数代替梯度,以“注意力”为锚点
Attention Matching 的核心洞察是:压缩的目标不是保留原始向量,而是保留模型的“注意力行为”。
只要压缩后的缓存能产生与原始缓存相同的注意力输出(Attention Output)和注意力质量(Attention Mass),模型就感知不到任何区别。
1. 参考查询机制(Reference Queries)
系统先生成一组“参考查询”,模拟模型可能进行的内部搜索:
- 重复预填充:隐藏提示模型复述上下文。
- 自学任务:让模型快速提取关键事实或结构化数据(如 JSON)。
这些查询作为“探针”,测试压缩后缓存的信息保留程度。
2. 数学匹配而非暴力优化
传统方法使用耗时的梯度下降来优化压缩表示。Attention Matching 则巧妙地将其转化为一个线性代数问题:
- 利用参考查询和原始 KV 对,构建方程组。
- 使用普通最小二乘法(OLS)或非负最小二乘法(NNLS)直接求解最优的压缩值和偏置项。
- 结果:无需反向传播,无需 GPU 长时间训练,仅需几秒即可完成压缩。
3. 分块策略
对于超长上下文,采用分块独立压缩再拼接的策略,进一步提升了处理效率和稳定性。
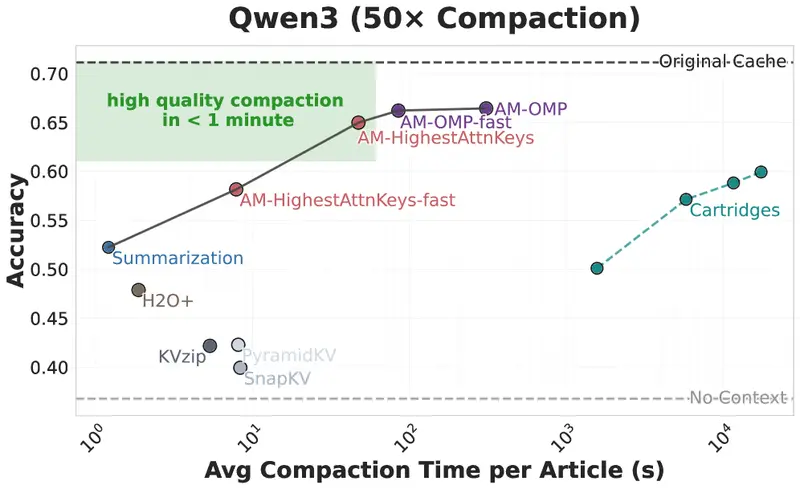
实测表现:速度与精度的双重胜利
研究团队在 Llama 3.1 和 Qwen-3 等主流模型上进行了严苛测试:
| 测试场景 | 数据集 | 压缩比 | 精度表现 | 耗时对比 |
|---|---|---|---|---|
| 阅读理解 | QuALITY (5k-8k 词) | 50x | 无损 | 几秒钟 vs 数小时 (Cartridges) |
| 医疗记录分析 | LongHealth (60k 词元) | 50x | 显著优于摘要 | 实时可用 |
| 极限压缩 | 通用文本 | 200x | 等同于摘要法,但内存更小 | 极速 |
| 在线压缩 | AIME 数学推理 | 动态 50% | 连续 6 次压缩仍满分 | 无感知中断 |
- 医疗场景突破:在处理复杂的 6 万词元患者记录时,传统摘要法导致模型性能崩塌(等同于没看文档),而 Attention Matching 在 50 倍压缩下依然保持了高精度诊断能力。
- 在线压缩验证:即使在推理过程中因内存不足被迫多次暂停并压缩 KV 缓存,模型仍能完美解决高难度数学题,证明了其动态适应性。
企业应用前景与挑战
✅ 核心价值
- 成本骤降:显存需求降低 50 倍,意味着同样的硬件可支撑 50 倍的并发用户,或处理更长的上下文。
- 实时可行:秒级压缩速度使其能嵌入实时工作流(如文档上传后立即压缩、对话中途动态清理)。
- 信息保全:解决了摘要法在专业领域(法律、医疗、代码)信息丢失的致命缺陷。
⚠️ 落地挑战
- 权重访问依赖:该技术需要访问模型权重进行计算,因此不适用于封闭 API 模型(如仅通过 API 调用的商业模型)。企业需使用开源权重模型(如 Llama, Qwen)自建服务。
- 工程集成复杂度:现有的高性能推理引擎(如 vLLM, TGI)架构复杂,集成此技术需要深度的底层改造(如适配前缀缓存、变长内存管理)。
- 极端压缩局限:在追求 100 倍以上极致压缩时,基于梯度的慢速方法可能仍有微弱优势,但在 50 倍这个“甜点区”,Attention Matching 是绝对王者。
未来展望
MIT 团队已开源代码,并指出:潜在空间压缩(Latent Space Compression)将是未来大模型基础设施的标准配置。
“压缩正从企业自行实施的变通方案,转变为模型提供商原生提供的核心功能。” —— Adam Zweiger, 论文合著者
对于拥抱开源模型的企业而言,Attention Matching 不仅是一把节省成本的利器,更是解锁超长上下文、高并发、低成本企业级 AI 应用的关键钥匙。随着推理引擎的逐步适配,我们有理由相信,未来的 AI 服务将不再受限于显存大小,真正进入“无限上下文”时代。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...