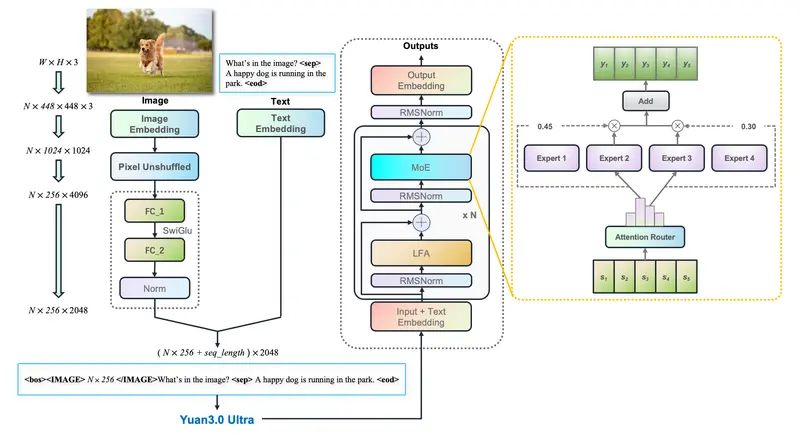
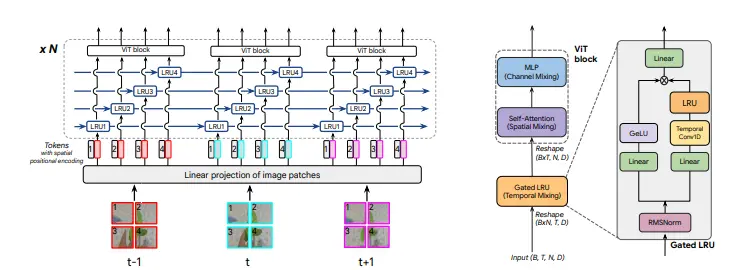
Google DeepMind发布一种新型的视频建模架构TRecViT(Temporal Recurrent Video Transformer)。这个架构是一种混合模型,它结合了时间序列处理和空间特征提取的优势,以提高视频理解任务的性能。TRecViT在处理视频时,会将视频帧分割成非重叠的块(patches),然后将这些块通过线性投影映射到一个token嵌入空间,并添加空间位置编码。接着,这些tokens会通过门控线性递归单元(LRUs)处理,这些LRUs在空间上共享参数。最后,经过递归块处理的输出会被送入一个ViT(Vision Transformer)块进行进一步处理。这个过程重复多次,以处理视频信号的时间、空间和通道维度。
主要功能:
- 视频理解:TRecViT能够处理包括视频分类和目标跟踪在内的多种视频理解任务。
- 稀疏和密集任务:模型能够处理稀疏任务(如视频分类)和密集任务(如点跟踪)。
- 因果模型:TRecViT是因果模型,意味着它在处理视频时尊重时间顺序,适用于需要在线处理的应用场景。
主要特点:
- 时间-空间-通道分解:TRecViT通过专门的块分别处理时间、空间和通道三个维度。
- 门控线性递归单元(LRUs):用于时间维度的信息混合,具有O(N)的训练时间复杂度和O(1)的推理时间复杂度。
- 自注意力层:用于空间维度的信息混合,允许并行处理所有像素。
- 多层感知器(MLP):用于通道维度的信息混合。
- 参数效率:与纯注意力模型相比,TRecViT拥有更少的参数、更小的内存占用和更低的浮点运算(FLOPs)计数。
工作原理:
TRecViT的工作原理基于时间序列的LRUs和空间序列的自注意力机制。LRUs处理视频帧的时间维度,而ViT块处理空间和通道维度。这种分解方法使得TRecViT能够有效地处理视频数据,同时保持较低的计算和内存需求。
具体应用场景:
- 视频分类:TRecViT可以用于识别视频中的动作或事件。
- 目标跟踪:TRecViT能够跟踪视频中的特定点或对象。
- 自监督学习:TRecViT可以通过掩码自编码(masked autoencoding)在无标签数据上进行预训练。
- 长视频记忆任务:TRecViT能够记住并重建在视频中较早前看到的帧,适用于需要长期记忆的应用,如视频编辑或增强。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...