多模态大语言模型Omni-RGPT:在统一图像和视频的区域级理解英伟达和延世大学的研究人员推出多模态大语言模型Omni-RGPT,旨在统一图像和视频的区域级理解。Omni-RGPT通过一种新颖的区域表示方法——Token Mark,实现了对图像和视频中特定区域的深...新技术# Omni-RGPT# 多模态大语言模型1年前02600
新型多模态大语言模型Sa2VA:将 SAM2 与 LLaVA相结合,实现对图像和视频的深入理解加州大学默塞德分校、字节跳动、武汉大学和北京大学的研究人员推出新型多模态大语言模型Sa2VA,它将SAM-2视频分割模型与LLaVA视觉-语言模型相结合,实现了对图像和视频的密集、基于语义的理解。Sa...多模态模型# Sa2VA# 多模态大语言模型1年前02810
任务偏好优化TPO:通过视觉任务对齐来提升多模态大语言模型的性能上海人工智能实验室、浙江大学、中国科学技术大学、上海交通大学、中国科学院深圳先进技术研究院和南京大学的研究人员推出一种名为任务偏好优化(Task Preference Optimization, TP...新技术# TPO# 任务偏好优化# 多模态大语言模型1年前03430
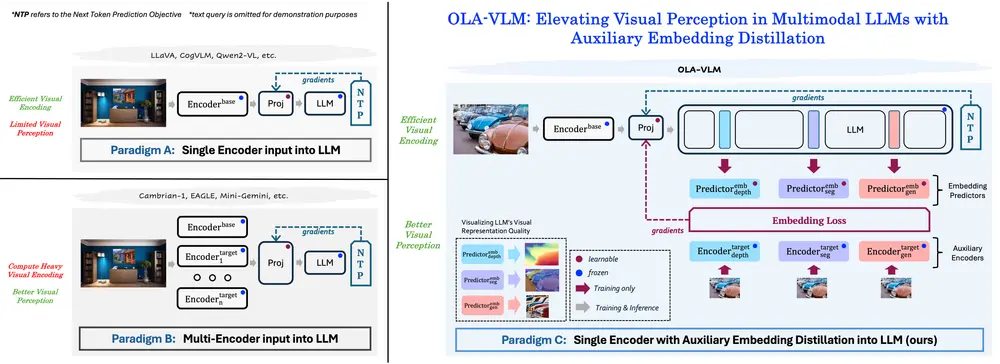
OLA-VLM:提升多模态大语言模型中的视觉感知能力开发当代多模态大语言模型(MLLMs)的标准做法是将视觉编码器的特征输入到大型语言模型(LLM)中,并通过自然语言监督进行训练。然而,这种方法存在一个潜在的局限性:仅依赖自然语言监督对于MLLM的视觉...新技术# OLA-VLM# 多模态大语言模型1年前02780
多模态大语言模型Lyra:专注于增强多模态能力,特别是高级长语音理解、声音理解、跨模态效率和无缝语音交互随着多模态大语言模型(MLLMs)的发展,扩展到单一领域之外的能力对于满足更通用和高效AI的需求至关重要。然而,之前的全模态模型在语音处理方面存在不足,忽视了其与视觉、文本等其他模态的深度整合。为了解...多模态模型# Lyra# 多模态大语言模型1年前03040
华为诺亚方舟实验室推出多模态大语言模型ILLUME华为诺亚方舟实验室发布多模态大语言模型ILLUME,旨在无缝集成图像和文本的理解与生成。ILLUME凭借其创新的架构和训练策略,在显著减少预训练所需数据量的同时,达到了最先进的性能。ILLUME基于统...新技术# ILLUME# 华为诺亚方舟实验室# 多模态大语言模型1年前02810
多模态大语言模型InternVL 2.5:处理和理解来自多种模态(如文本、图像和视频)的信息InternVL 2.5 是由上海人工智能实验室、商汤科技研究院、清华大学、南京大学、复旦大学、香港中文大学和上海交通大学等多家机构联合推出的一款先进的多模态大语言模型(MLLM)。该模型基于此前发布...多模态模型# InternVL 2.5# 多模态大语言模型1年前03010
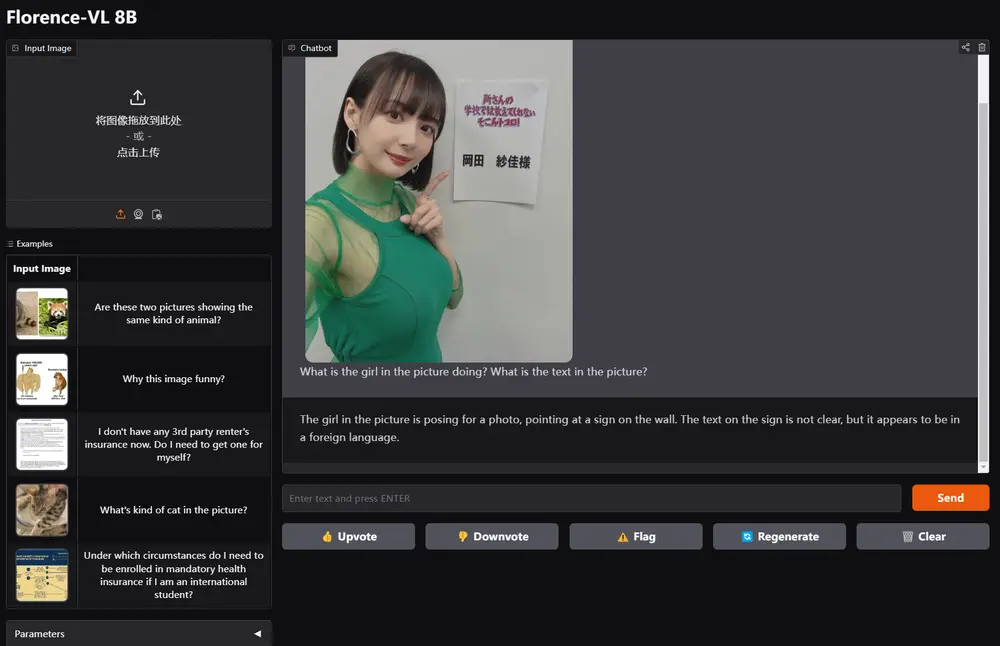
微软推出全新多模态大语言模型家族Florence-VL马里兰大学和微软研究院的研究团队共同提出了Florence-VL,这是一个全新的多模态大语言模型(MLLMs)家族。Florence-VL的视觉表示由生成式视觉基础模型Florence-2生成,与传统...多模态模型# Florence-VL# 多模态大语言模型# 微软1年前03160
多模态大语言模型ChatRex:提升对人类姿态的感知和理解能力IDEA的研究人员推出多模态大语言模型ChatRex,它旨在提升对人类姿态的感知和理解能力。ChatRex通过结合视觉和语言模型,能够执行多种与人体姿态相关任务,包括姿态理解、生成和编辑。这个模型特别...多模态模型# ChatRex# 多模态大语言模型1年前02800
新型多模态大语言模型PUMA:不仅能理解文本指令,还能根据这些指令创作出精细的图像,或者对现有图像进行精确的编辑近年来,多模态基础模型在视觉-语言理解领域取得了显著进展,同时也开始探索多模态大语言模型(MLLMs)在视觉内容生成方面的潜力。然而,现有的工作在统一MLLM范式中处理不同图像生成任务的多样化粒度需求...百科# PUMA# 多模态大语言模型1年前04240
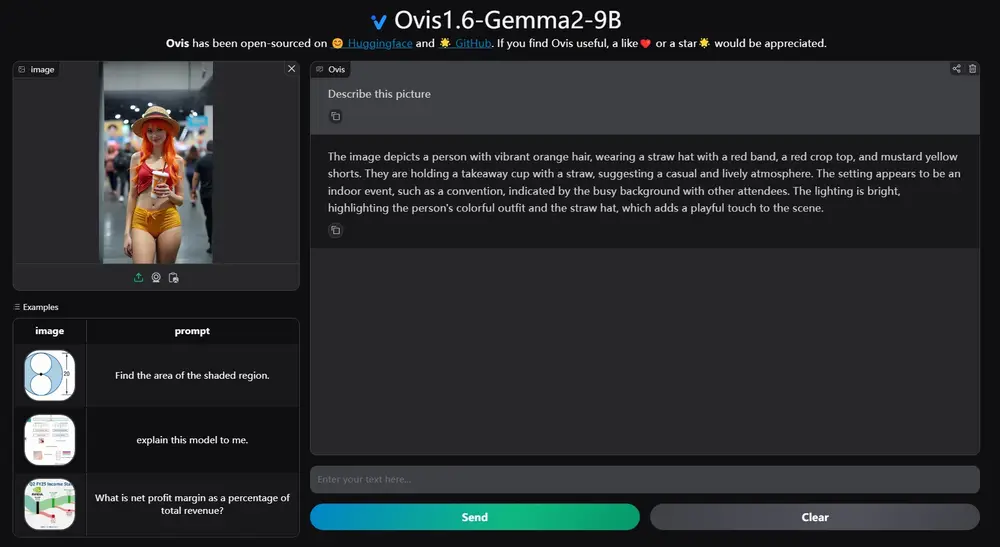
阿里国际推出多模态大语言模型 Ovis1.6-Gemma2-9B:能够同时处理和理解文本和视觉信息 Ovis1.6-Gemma2-9B是阿里国际推出的一款多模态大语言模型,Ovis是一种新颖的多模态大语言模型(MLLM)架构,旨在结构化地对齐视觉和文本嵌入。Ovis1.6-Gemma2-9B基于O...多模态模型# Ovis1.6-Gemma2-9B# 多模态大语言模型1年前05640
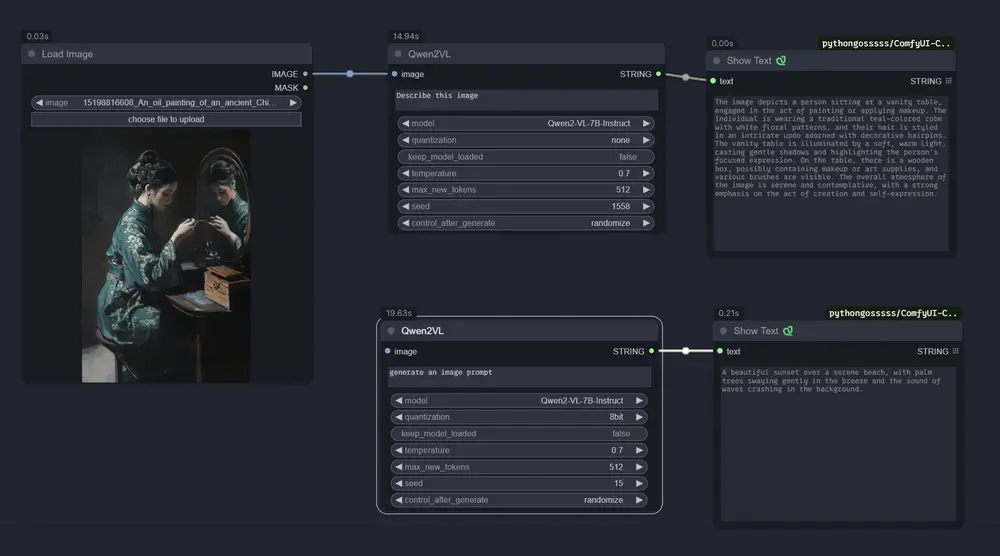
多模态大语言模型Qwen2-VL-7B-Captioner-Relaxed:经过指令调整的Qwen2-VL-7B-Instruct版本Qwen2-VL-7B-Captioner-Relaxed 是 Qwen2-VL-7B-Instruct 的一个经过指令调整的版本,它是一个多模态大语言模型。这个经过精细调整的版本是基于一个为文生图模...多模态模型# Qwen2-VL-7B-Captioner-Relaxed# 多模态大语言模型1年前05930