
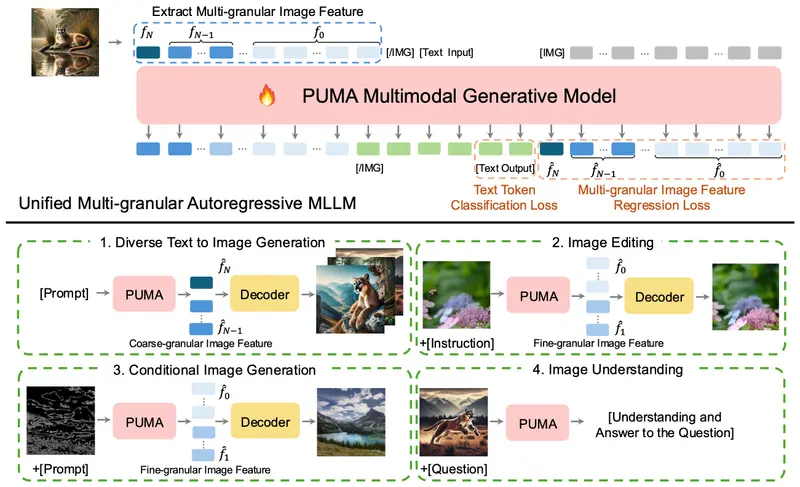
近年来,多模态基础模型在视觉-语言理解领域取得了显著进展,同时也开始探索多模态大语言模型(MLLMs)在视觉内容生成方面的潜力。然而,现有的工作在统一MLLM范式中处理不同图像生成任务的多样化粒度需求方面仍存在不足。为了克服这一挑战,香港中文大学MMLab、香港大学MMLab、商汤科技、上海人工智能实验室和清华大学的研究人员联合提出了一种名为PUMA的新型多模态大语言模型,它能够处理和生成不同粒度级别的视觉表示,以平衡视觉生成任务中的多样性和可控性。这个模型就像一个多才多艺的艺术家,不仅能理解文本指令,还能根据这些指令创作出精细的图像,或者对现有图像进行精确的编辑。
例如,你想创建一幅画,描述了一个穿着特定风格服装的拟人化狐狸。使用PUMA,你只需输入一段描述性的文本,模型就能生成一幅多样化的图像,每一幅都独一无二,但都符合你的描述。或者,如果你有一张风景照片,想要移除照片中的某个元素,比如一个拖拉机,PUMA也能做到这一点,并且保持图像的其他部分不变。

主要功能和特点:
- 多粒度视觉特征:PUMA能够处理从粗糙的语义概念到精细的细节信息的多种视觉特征。
- 统一框架:在一个统一的模型框架内,PUMA能够执行多种视觉任务,如图像理解、文本到图像的生成、图像编辑、修复和条件图像生成。
- 自回归MLLM:PUMA使用自回归机制逐步处理和生成文本和多粒度图像特征。
- 扩散模型:PUMA利用扩散模型作为图像解码器,能够从MLLM生成的特征中重建或生成图像。

工作原理:
- 图像编码:PUMA使用图像编码器提取多粒度的视觉特征,这些特征作为MLLM的输入。
- 特征处理和生成:MLLM处理输入的文本和图像特征,并逐步生成多尺度的图像特征。
- 图像解码:使用专门的扩散模型根据MLLM生成的特征在不同粒度上解码图像。
应用实例
- 创意图像生成:假设你想创作一幅描绘穿着特定风格服装的拟人化狐狸的艺术作品。只需向PUMA输入一段描述性的文本,模型就能生成多个独特且符合要求的图像选项。
- 精确图像编辑:如果你拥有一张风景照,希望从中移除某个不想要的元素,如一辆拖拉机,同时保持画面其余部分不变,PUMA同样可以胜任这项任务,提供自然而流畅的编辑结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











