
香港中文大学、香港科技大学与字节跳动联合推出开源模型 DreamOmni2,旨在突破当前 AI 图像编辑与生成的两大瓶颈:纯文本指令表达力有限,以及现有模型难以处理抽象概念(如风格、纹理、妆容等)。
- 项目主页:https://pbihao.github.io/projects/DreamOmni2/index.html
- GitHub:https://github.com/dvlab-research/DreamOmni2
- 模型:https://huggingface.co/xiabs/DreamOmni2
- 生成Demo:https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
- 编辑Demo:https://huggingface.co/spaces/wcy1122/DreamOmni2-Edit
为此,团队提出了两个新任务:多模态指令编辑 与 多模态指令生成,允许用户同时使用文本 + 参考图像作为输入,实现更精准、更灵活的图像操控。
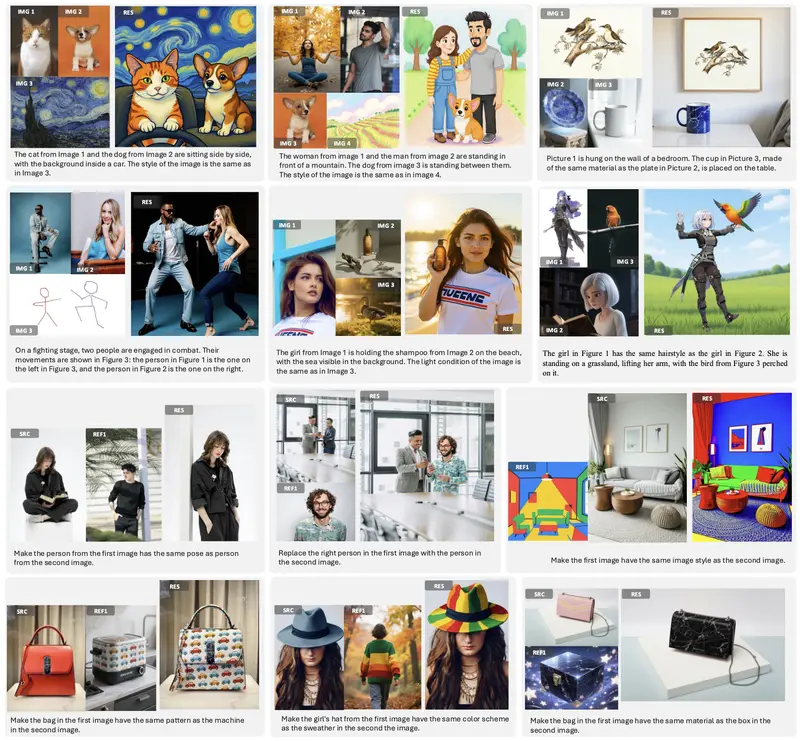
什么是多模态指令?
传统方法仅靠文字描述(如“把裙子换成波点图案”),但“波点”具体指哪种?用户往往需要一张参考图。DreamOmni2 支持这类混合指令:
- 多模态编辑示例:
“将这张人像照片中的裙子,替换为第二张图中裙子的图案和材质。”
→ 模型精准迁移图案,同时保留人物姿态、光照等非编辑区域。 - 多模态生成示例:
“生成一张新图像,人物风格来自第一张图,背景场景来自第二张图。”
→ 模型融合身份特征与环境元素,生成协调的新画面。
三大核心能力
- 统一架构,支持生成与编辑
编辑任务要求严格保留原图未修改部分,生成任务则侧重整体美观与概念融合。DreamOmni2 将两者统一于同一框架,用户可根据需求选择模式。 - 同时处理具体对象与抽象属性
不仅能迁移“裙子”“汽车”等具体物体,还能迁移“赛博朋克风格”“哑光质感”“复古卷发”等抽象概念,能力甚至超越部分商业模型。 - 支持多图像输入
可同时参考多张图像(如一张提供风格,一张提供构图),完成复杂组合任务。
技术亮点
- 高质量训练数据生成:通过“特征混合”技术自动构建包含相同属性/对象的图像对,用于训练提取模块。
- 多图像区分机制:引入索引编码与位置偏移,避免模型混淆多个输入图像的像素信息。
- 联合训练策略:将视觉语言模型(VLM)与生成/编辑模块端到端联合优化,提升对复杂指令的理解能力。
性能表现(人类评估)
| 任务类型 | DreamOmni2 成功率 | 对比模型(如 GPT-4o、Nano Banana) |
|---|---|---|
| 多模态指令编辑 | 60.98% | 显著领先 |
| 多模态指令生成 | 68.29% | 与 GPT-4o 相当,远超其他开源模型 |
在 Gemini 和 Doubao 的自动评估中,DreamOmni2 同样保持领先。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











