
腾讯混元项目组正式开源HunyuanImage 2.1,一款支持 2048×2048 超高分辨率(2K)生成的文生图模型。该模型在语义对齐、细节控制与推理效率方面实现显著提升,具备电影级构图能力,并原生支持中英文提示词。
- 官方介绍:https://mp.weixin.qq.com/s/y42JArSGf-9amxShrpTKGA
- 腾讯混元官网:https://hunyuan.tencent.com/image
- Github:https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
- Hugging Face:https://huggingface.co/tencent/HunyuanImage-2.1
- Hugging Face Demo:https://huggingface.co/spaces/tencent/HunyuanImage-2.1
- GGUF版本:https://huggingface.co/calcuis/hunyuanimage-gguf
- GGUF版本:https://huggingface.co/QuantStack/HunyuanImage-2.1-GGUF
- FP8版本:https://huggingface.co/drbaph/HunyuanImage-2.1_fp8
作为工业级文生图系统的最新迭代,HunyuanImage 2.1 不仅在生成质量上逼近闭源商业模型,还在架构设计与训练方法上展现出多项技术创新。

核心能力一览
✅ 超高分辨率输出
支持 2K(2048×2048)图像生成,适用于海报设计、影视概念图等高质量视觉需求场景。
✅ 多语言与字形感知
- 原生支持中文和英文提示;
- 引入 ByT5 字符级编码器,显著提升图像中嵌入文本的准确性(如招牌、标语、书法等)。
✅ 灵活宽高比支持
兼容多种比例:1:1、16:9、9:16、4:3、3:4、3:2、2:3,适配移动端、横屏内容与印刷品。
✅ 提示词增强(PromptEnhancer)
内置自动提示重写模块,可丰富用户输入的简略描述,添加细节以提升画面表现力。
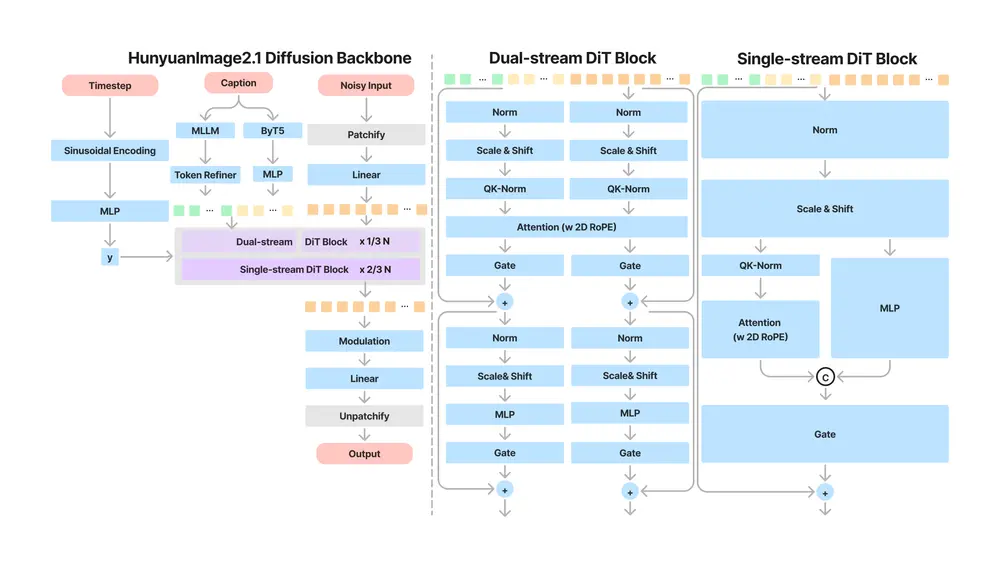
技术架构:两阶段生成 + 高效推理
HunyuanImage 2.1 采用 两阶段生成架构,兼顾质量与效率:
第一阶段:基础文本到图像模型
- 双文本编码器设计:
- 多模态大语言模型(MLLM):增强对复杂场景、人物动作和逻辑关系的理解;
- 多语言 ByT5 编码器:优化文本渲染与跨语言表达。
- 170 亿参数 DiT 架构:采用单流与双流结合的 Diffusion Transformer,提升语义表达能力。
- 人类反馈强化学习(RLHF):通过监督微调(SFT)与强化学习(RL)两阶段后训练,优化美学与结构连贯性。
第二阶段:图像精修模型
对第一阶段输出进行细节增强,进一步提升清晰度、光影质感与局部一致性。
创新技术亮点
🔹 高压缩 VAE(32× 压缩率)
采用高压缩率 VAE,将图像特征压缩至 32×32 空间,大幅减少 DiT 模型的输入 token 数量。这使得生成 2K 图像的计算开销与生成 1K 图像相当,显著提升推理效率。
🔹 结构化标注与数据增强
训练数据引入分层语义标注(短/中/长/超长描述),并创新使用:
- OCR 专家模型:解决密集文本生成难题;
- IP RAG(知识产权检索增强):提升对现实世界知识的描述准确性;
- 双向验证策略:确保标注质量。
🔹 PromptEnhancer:系统性提示改写
首个工业级提示词增强模块:
- 通过 SFT 训练,结构化重写用户提示,补充视觉细节;
- 采用 GRPO 训练 + AlignEvaluator 奖励模型(覆盖 6 大类、24 细粒度评估点),提升重写后生成图像的语义一致性。
🔹 MeanFlow 模型蒸馏
提出基于 MeanFlow 的新型蒸馏方法,解决传统训练不稳定问题,支持少量采样步数下的高质量生成。据称,这是 MeanFlow 在工业级模型上的首次成功应用。
性能评测:媲美闭源模型
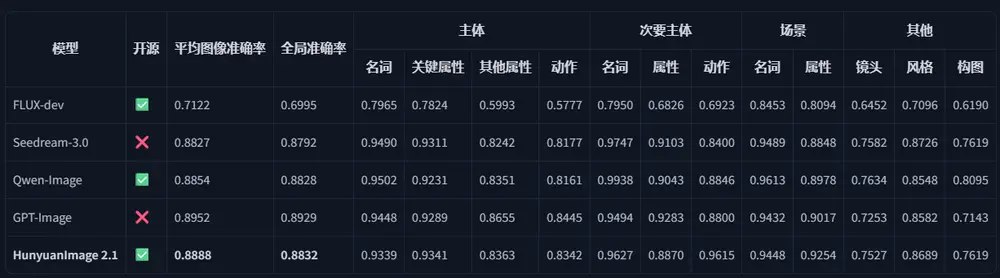
✅ SSAE 语义对齐评测
基于多模态大语言模型(MLLM)的智能评估体系,在 12 个类别、3500 个关键要点上进行比对:
- 平均图像准确率与全局准确率均达到当前开源模型最优水平;
- 表现接近闭源商业模型 GPT-Image。
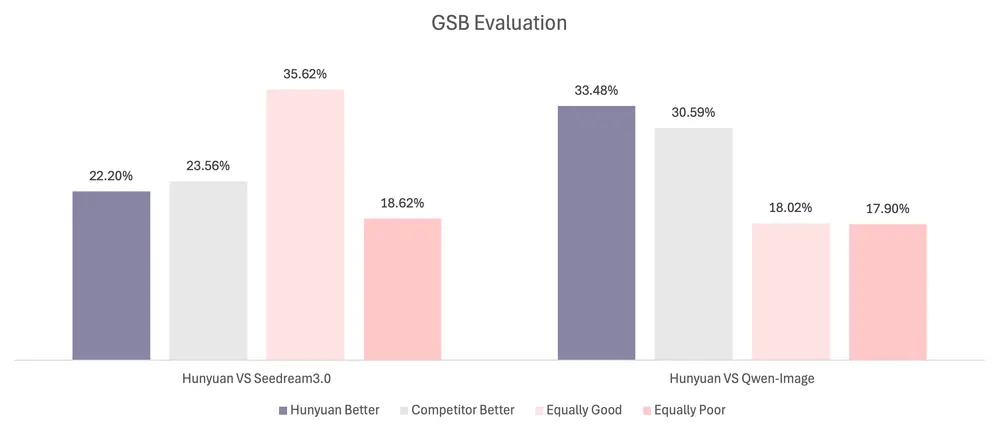
✅ GSB 人类评审评测
由 100+ 位专业评审对 1000 条提示生成图像进行盲评:
- 相比闭源模型 Seedream3.0,相对胜率差距仅 -1.36%;
- 相比开源模型 Qwen-Image,胜率高出 2.89%。
结果表明,HunyuanImage 2.1 作为开源模型,已具备与主流闭源模型竞争的实力。
系统要求
| 项目 | 要求 |
|---|---|
| GPU | 支持 CUDA 的英伟达显卡 |
| 显存 | 至少 59 GB(用于 2048×2048 分辨率,batch size=1) |
| 操作系统 | Linux、Windows |
| 备注 | 支持 CPU offloading。若显存充足,可禁用以提升推理速度 |
⚠️ 注意:59GB 为启用 CPU 卸载时的内存占用。实际部署建议使用 H100/A100 级别显卡。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











