随着大语言模型(LLM)参数规模持续增长,部署成本已成为制约其广泛应用的主要瓶颈之一。
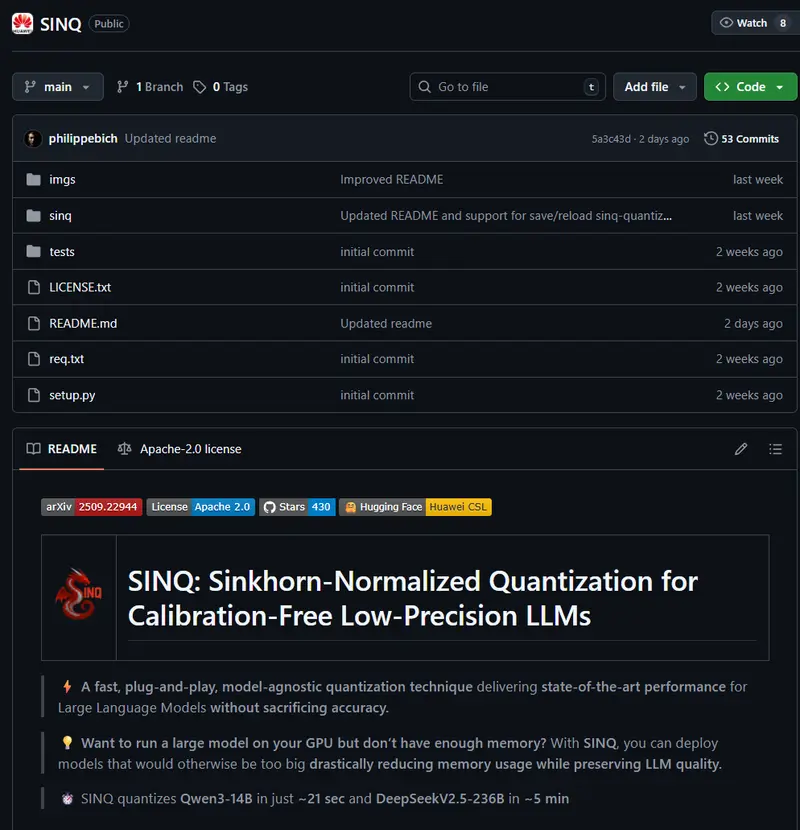
华为苏黎世计算系统实验室近日推出一项名为 SINQ(Sinkhorn-Normalized Quantization)的开源模型量化技术,旨在显著降低LLM内存占用,同时最大限度保留输出质量。该方案无需校准数据、易于集成,且已以 Apache 2.0 许可证在 GitHub 和 Hugging Face 公开发布,支持自由使用与商业部署。
实测表明,SINQ 可将模型内存需求减少 60%–70%,使原本需 >60GB 显存的模型可在约 20GB 显存环境下运行——这意味着开发者现在可以用单张消费级 GPU(如 RTX 4090)替代昂贵的企业级硬件(如 A100/H100),大幅降低推理成本。
为什么需要模型量化?
现代LLM通常以 FP16 或 BF16 精度存储权重,每个参数占用2字节。一个70亿参数模型仅权重就接近14GB;百亿级以上模型则动辄需要数十GB显存。
而高端数据中心GPU(如NVIDIA A100 80GB、H100)价格高昂:
- A100 单卡售价约 1.9万美元
- H100 超过 3万美元
相比之下,消费级旗舰显卡如 RTX 4090(24GB) 售价约为 1600美元,云实例每小时费用也仅为A100的1/3左右。
量化技术的核心目标就是:
在不明显损失性能的前提下,用更低精度格式(如INT8、NF4)表示模型参数,从而减少内存占用和计算开销。
但传统方法往往面临两大挑战:
- 精度下降明显,尤其在4-bit及以下;
- 依赖校准数据集,增加部署复杂性和延迟。
SINQ 正是为解决这些问题而设计。
SINQ 的核心技术:双轴缩放 + Sinkhorn归一化
SINQ 是一种无需校准、即插即用的量化方法,其创新主要体现在两个层面:
✅ 1. 双轴缩放(Dual-Axis Scaling)
不同于传统量化中对整个权重矩阵使用单一缩放因子,SINQ 引入了行向量与列向量的独立缩放机制。
这使得量化误差能更灵活地分布在整个矩阵中,有效缓解因个别异常值(outliers)导致的整体失真问题。
✅ 2. Sinkhorn-Knopp 风格归一化
受经典 Sinkhorn 算法启发,SINQ 对权重矩阵的行和列标准差进行迭代调整,使其趋于均衡状态。
研究团队提出“矩阵不平衡度”作为新指标,发现它比传统的峰度(kurtosis)更能准确预测量化后性能退化。通过最小化这一指标,SINQ 显著提升了低精度下的稳定性。
这两个机制协同作用,使 SINQ 在无需任何校准样本的情况下,仍能达到接近甚至媲美有校准方法的性能表现。
实测表现:高效、兼容、速度快
SINQ 已在多个主流架构上验证,包括:
- LLaMA / LLaMA2 / LLaMA3
- Qwen 系列(含 Qwen3)
- DeepSeek-MoE / DeepSeek-V2
在标准基准测试(WikiText2、C4)上的评估结果显示:
| 指标 | 表现 |
|---|---|
| 困惑度(Perplexity) | 显著低于 RTN、HQQ 等无校准方法,接近 AWQ 校准方案 |
| 翻转率(Flip Rate) | 更低,说明权重扰动更小,保真度更高 |
| 量化速度 | 是 HQQ 的 2倍,比 AWQ 快 30倍以上 |
此外,SINQ 支持多种先进量化格式:
- 统一量化(INT8/INT4)
- 非均匀量化(如 NF4)
- 可与 AWQ 等校准方法结合,形成增强版 A-SINQ
在校准场景下,A-SINQ 进一步缩小了与全精度模型之间的差距。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...