
随着多模态大模型在图文理解、文本到图像生成、图像编辑等任务中表现日益强大,其高昂的推理成本也逐渐成为落地瓶颈。传统的自回归解码与扩散去噪过程需要大量迭代计算,在长上下文或多轮交互场景下响应迟缓。
为此,字节跳动提出 Hyper-Bagel ——一个面向统一多模态系统的高效推理加速框架,同时提升理解和生成任务的速度,而无需牺牲输出质量。
该框架已在内部多个产品线验证,显著降低服务延迟与算力消耗,支持更流畅的交互式应用体验。

核心挑战:多模态推理的“速度墙”
现代多模态模型通常融合文本、图像等多种标记(tokens),在处理复杂指令时上下文长度迅速增长。无论是:
- 自回归生成中的逐 token 解码,
- 还是扩散模型中数十步的去噪过程,
都会带来巨大的计算开销,限制了其在实时系统中的部署能力。
Hyper-Bagel 正是为了打破这一“速度墙”而生。
技术方案:分而治之,双轨加速
Hyper-Bagel 采用“分而治之”策略,针对不同任务类型设计专用加速机制:
1. 多模态理解加速:推测解码(Speculative Decoding)
为加速自回归解码过程,Hyper-Bagel 引入轻量级草稿模型(Draft Model)进行快速预测:
- 草稿模型以较低计算代价连续生成多个候选 token;
- 主模型并行验证这些预测结果;
- 成功则批量接受,失败则截断重校。
这一方法将原本串行的内存访问瓶颈转化为可并行的计算问题,在多模态问答、视觉推理等任务中实现 2倍以上推理加速,且无精度损失。
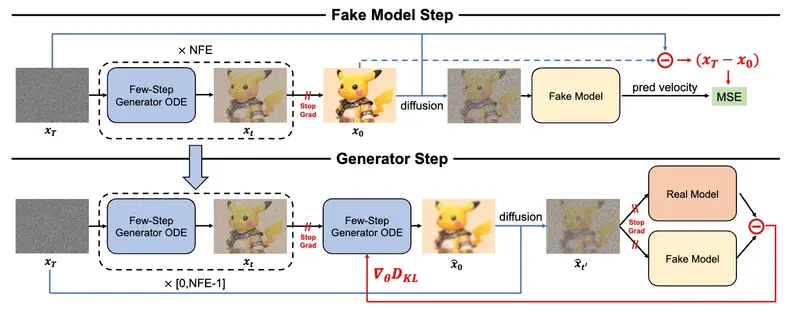
2. 多模态生成加速:多阶段知识蒸馏
针对扩散模型生成慢的问题,Hyper-Bagel 构建了一个五阶段蒸馏流程,训练极低步数(NFE)的学生模型,逼近高步数教师模型的表现。
蒸馏五个阶段详解:
| 阶段 | 方法 | 目标 |
|---|---|---|
| ① CFG 蒸馏 | 将文本/图像引导参数嵌入前向传播 | 支持可控生成 |
| ② TSCD(轨迹分割一致性蒸馏) | 使用多头鉴别器 + 对抗损失 | 增强结构完整性 |
| ③ DMDO(分布匹配通过ODE) | 利用常微分方程对齐师生轨迹 | 避免图像过度平滑 |
| ④ ADP(对抗性扩散预训练) | 基于修正流(Rectified Flow)进行对抗训练 | 提升1-NFE初始质量 |
| ⑤ ReFL(奖励反馈学习) | 引入基于VLM的奖励模型模拟人类偏好 | 优化语义保真度 |
通过这一系统化蒸馏流程,学生模型仅需极少推理步数即可生成高质量结果。
性能表现:从“分钟级”到“秒级”响应
Hyper-Bagel 在多个基准测试中展现出卓越的加速能力:
| 任务 | 模型配置 | 加速比 | 输出质量 |
|---|---|---|---|
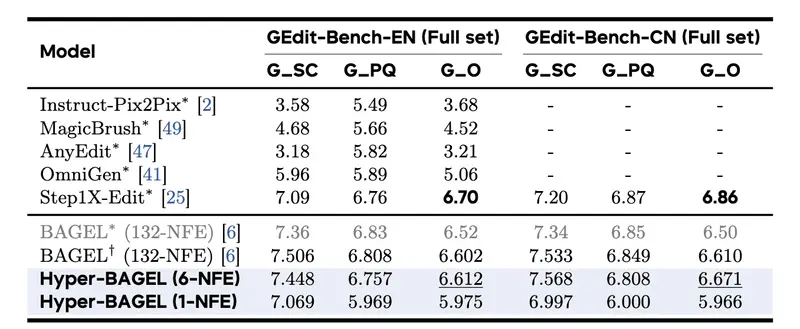
| 文本到图像生成 | 6-NFE vs 100-NFE | 16.67× | 与基线相当(GenEval) |
| 图像编辑 | 6-NFE vs 132-NFE | 22× | 在英中文数据集均超越基线(GEdit-Bench) |
| 多模态理解 | 推测解码启用 | >2× | 准确率无损 |
更进一步,团队开发出 1-NFE 模型(单步去噪),可在 毫秒级完成图像生成或编辑,支持近实时交互,适用于:
- 即时风格迁移
- 快速对象移除/替换
- 交互式创作工具
尽管细节保真度略有妥协,但整体语义连贯性和可用性仍具竞争力。
实际意义:让复杂多模态交互变得即时
Hyper-Bagel 不只是一个实验室成果,更是面向生产环境的工程突破。它的核心价值在于:
- ✅ 统一架构:一套框架覆盖理解与生成;
- ✅ 无损加速:在关键任务中保持原始模型性能;
- ✅ 支持实时交互:为下一代 AI 创作工具提供低延迟基础;
- ✅ 高性价比部署:大幅降低 GPU 成本与能耗。
这意味着,未来用户可以在聊天界面中“边说边看图”,或对图像进行“拖拽式编辑+AI补全”,整个过程如本地操作般流畅。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











