
Stability AI 近日发布 SD3.5-Flash ——一个全新的少步蒸馏(few-step distillation)图像生成模型,解决当前生成式 AI 模型在普通硬件上运行困难的核心痛点。
该模型能够在8GB 内存限制下,不到一秒内生成高分辨率图像,并已在 RTX 4090、M3 MacBook Pro 等主流消费级设备上验证可行性。这意味着,过去只能在数据中心运行的高端图像生成能力,如今正逐步走向手机、笔记本和平板等终端设备。

为什么需要“少步”模型?
目前最先进的图像生成模型(如修正流模型 rectified flow)依赖数十甚至上百个推理步骤来逐步去噪,从而获得高质量结果。虽然效果出色,但这类模型:
- 计算成本高昂
- 显存占用大(常需 16GB+ VRAM)
- 延迟高(数秒至数十秒)
这使得它们难以部署于移动端或实时应用场景中。
为此,业界普遍采用“知识蒸馏”方法,将大型教师模型的能力压缩到更小的学生模型中,以实现“少步生成”。然而,传统蒸馏方式在极少数步骤(如 4–8 步)下容易出现梯度不稳定、质量下降等问题。
SD3.5-Flash 正是为攻克这一难题而生。
核心创新:三项关键技术突破
1. 时间步共享(Timestep Sharing)——提升训练稳定性
标准蒸馏过程中,学生模型通过模拟教师模型的“加噪→去噪”轨迹进行学习。但在少步体制下,重新加噪的过程会产生噪声估计偏差,导致梯度不稳定。
SD3.5-Flash 提出 时间步共享机制:
不再使用随机加噪样本作为目标,而是复用学生模型自身前向传播中的中间轨迹样本,作为分布匹配的目标。这种方式显著降低了梯度方差,提升了训练鲁棒性。
✅ 效果:即使在仅 4 步的极端条件下,也能稳定训练出高质量模型。
2. 分时步微调(Split-timestep Fine-tuning)——破解容量-质量权衡
少步模型面临一个根本矛盾:模型参数有限,却要在极短时间内完成复杂去噪任务。
为此,团队提出 分时步微调 技术:
- 在训练阶段,将时间轴划分为多个区间;
- 每个区间使用独立的轻量分支扩展模型容量;
- 训练完成后,合并所有分支,形成统一的高效模型。
这种方法相当于“临时扩容”,既保证了各阶段的表达能力,又不增加最终推理负担。
3. 全面管道优化——适配真实硬件环境
除了模型结构改进,SD3.5-Flash 还对整个生成流程进行了深度优化:
- 文本编码器重组:精简冗余计算,减少上下文处理延迟;
- 智能量化策略:支持 INT8 和 FP8 推理,在精度损失极小的情况下大幅降低内存占用;
- 内存管理优化:确保在 8GB 显存限制内流畅运行。
这些优化共同支撑了其在移动 GPU 和桌面显卡上的高效表现。
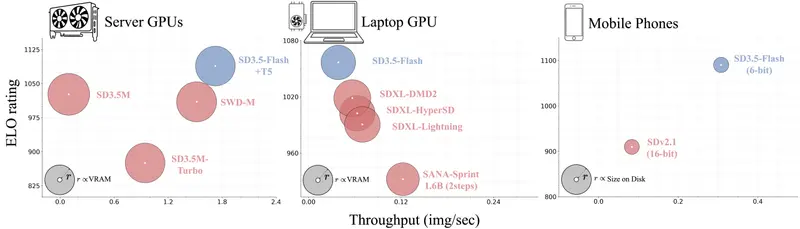
实测表现:用户更偏好,性能更领先
Stability AI 通过大规模用户研究和定量测试验证了 SD3.5-Flash 的优势。
用户偏好测试(ELO 评分)
在与 SDXL-DMD2、NitroFusion 等现有少步模型对比中,SD3.5-Flash 在图像质量、提示一致性等方面均获得更高的人类评分,成为用户首选。
定量指标对比(基于 COCO 数据集 30K 样本)
| 指标 | 表现 |
|---|---|
| ImageReward | 显著优于多数基线 |
| CLIPScore | 提示对齐能力更强 |
| Aesthetic Score | 视觉美感得分高 |
| FID | 略逊于最优模型,但整体处于第一梯队 |
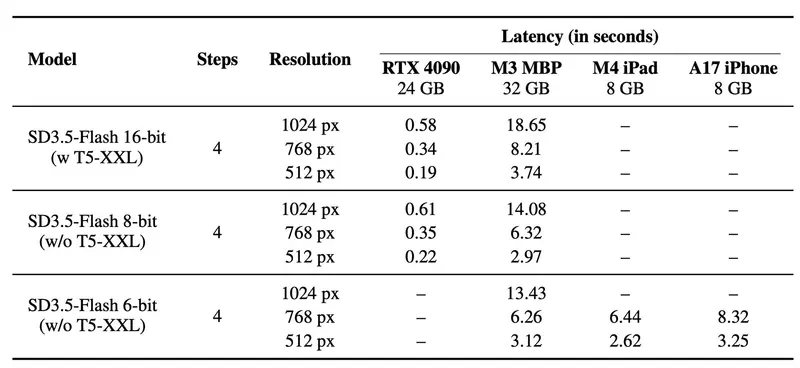
推理效率实测
| 设备 | 模型配置 | 延迟 | 显存占用 |
|---|---|---|---|
| RTX 4090 | 4 步, FP16 | 0.58 秒 | ~7.8 GiB |
| M3 MacBook Pro | 8 步, INT8 | 13.43 秒 | ~8 GiB |
💡 注:Mac 上因 CPU 占比高,延迟较长,但仍可在本地完整运行。
工作原理简述:从“轨迹复制”到“分布匹配”
SD3.5-Flash 的核心是 分布匹配蒸馏(Distribution Matching Distillation, DMD),其训练过程包含三个关键环节:
- 轨迹引导(Trajectory Guidance)
学生模型学习模仿教师模型在潜空间中的去噪路径,确保生成过程平滑。 - 分布匹配(Distribution Matching)
使用 KL 散度最小化学生与教师模型输出分布之间的差异,提升保真度。 - 对抗训练(Adversarial Training)
引入多头鉴别器,增强细节真实感,使生成图像在视觉上更接近自然图像。
这套组合策略确保了即便在极少步骤下,也能保留教师模型的高质量特性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











