商汤科技正式开源 SenseNova-MARS —— 一款支持动态视觉推理与图文搜索深度融合的多模态大模型(VLM)。该模型提供 8B 与 32B 双版本,在多模态搜索与推理核心基准 MMSearch 上以 69.74 分 超越 Gemini-3-Pro(69.06)与 GPT-5.2(67.64),成为当前开源模型中的 SOTA,并在多项闭源模型对比中实现全面领先。
- GitHub:https://github.com/OpenSenseNova/SenseNova-MARS
- 32B:https://huggingface.co/sensenova/SenseNova-MARS-32B
- 8B:https://huggingface.co/sensenova/SenseNova-MARS-8B
核心突破:Agentic VLM 架构
SenseNova-MARS 是首个将 自主智能体(Agentic)能力深度集成至多模态推理的开源模型。它不仅能理解图文内容,还能:
- 自主规划任务步骤
- 动态调用工具链(图像裁剪、文本/图像搜索等)
- 执行多跳推理闭环
这一设计使其从“被动问答”升级为“主动执行”,真正具备解决复杂现实问题的能力。
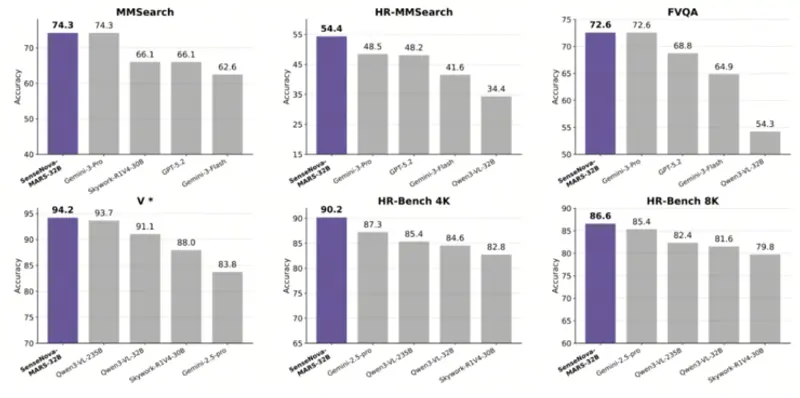
性能表现:在高难度评测中全面领先
| 基准 | SenseNova-MARS | Gemini-3-Pro | GPT-5.2 | 领先幅度 |
|---|---|---|---|---|
| MMSearch(综合) | 69.74 | 69.06 | 67.64 | +0.68 |
| MMSearch(图文搜索) | 74.27 | — | 66.08 | +8.19 |
| HR-MMSearch(高清细节) | 54.43 | — | — | 显著领先 |
HR-MMSearch 测试特点:
- 使用 305 张 2025 年 4K 新图,杜绝知识记忆作弊
- 问题聚焦 占比 <5% 的微小细节(如 Logo、小字、远处物体)
- 覆盖 8 大领域(体育、科技、金融等),60% 问题需 ≥3 种工具协作
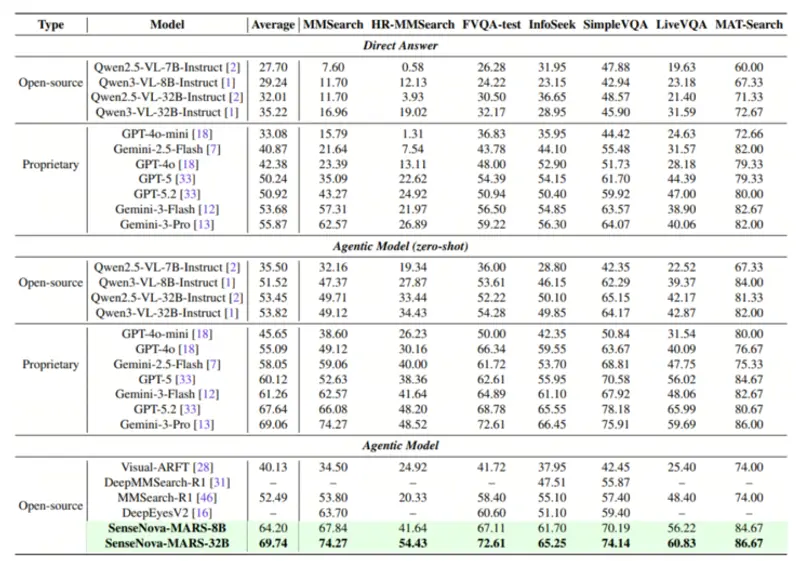
真实场景能力:多工具协同解决复杂任务
传统多模态模型在面对“识别+检索+推理”复合任务时往往失效。而 SenseNova-MARS 可自主完成端到端流程:
示例任务:
“识别赛车服上的微小 Logo → 查询公司成立年份 → 匹配车手出生年月 → 计算年龄差”
执行过程:
- 调用 图像裁剪 工具放大 Logo 区域
- 使用 图像搜索 识别品牌与车手
- 通过 文本搜索 获取公司成立时间与人物生平
- 自动计算并输出结果

典型应用场景:
- 行业分析:从峰会照片中提取企业标志,自动搜集产品参数、融资信息、时间线
- 赛事追踪:识别画面中人物/Logo,追溯背景资料与历史战绩
- 科研辅助:分析论文图表细节,关联最新研究数据验证假设
技术创新:双阶段训练构建“工具使用直觉”
阶段一:高难度数据合成
- 提出 多智能体自动化数据引擎,解决跨模态多跳推理数据稀缺问题
- 采用 细粒度视觉锚点 + 多跳深度关联检索,动态构建逻辑严密的推理链
- 引入 闭环自洽性校验,过滤幻觉数据,确保训练集质量
阶段二:强化学习优化
- 采用 BN-GSPO 算法(双阶段归一化强化学习)
- 平滑工具调用返回分布的多样性
- 确保简单与复杂任务的学习信号一致性
- 通过奖励机制培养 工具选择直觉:模型学会在何时调用何种工具,并融合多源结果
经此训练,模型不仅掌握工具使用,更形成类人决策策略——知道“先看哪里、再查什么、如何验证”。
开源与生态
- 模型权重:8B / 32B 双版本已开源
- 工具链支持:内置图像裁剪、图文搜索等模块
- 应用场景:支持 API 调用与本地部署,适用于企业级多模态智能体开发
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...